
Detr:End-to-End Object Detection with Transformers笔记
目前transformer在CV领域打的火热,前文记录了transformer用于图像分类的实现,本文主要记录transformer用于目标检测,以下主要结合youtuber 讲解视频 和 一步一步的debugdetr 的代码的学习记录。
DETR 总览
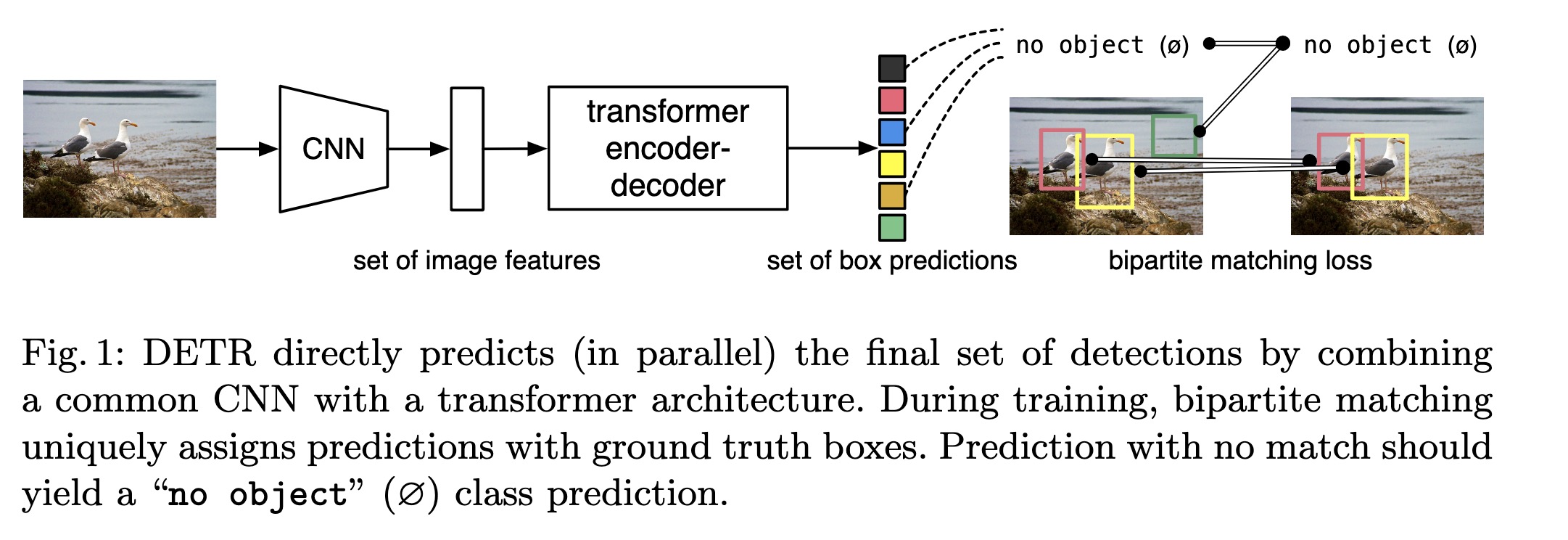
其流程如上图所示,输入一张图片,先进过CNN网络得到一系列图片特征,然后使用transformer对图片特征进行编、解码,得到指定数量的预测框集合,对每个预测框使用分类头分类和box头输出物体的中心点和宽高(相对于输入图片).
优点:
- 全新的目标检测框架,detr的精度能赶上faster rcnn,毕竟是新方向,后续肯定会有很多人投入研究,提升性能
- 更简单的目标检测策略,网络直接输出物体,抛弃了比如anchor啊,NMS啊各种复杂的设计和处理
模块解析
detr 总体网络结构如下图, 以下分模块进行分析:
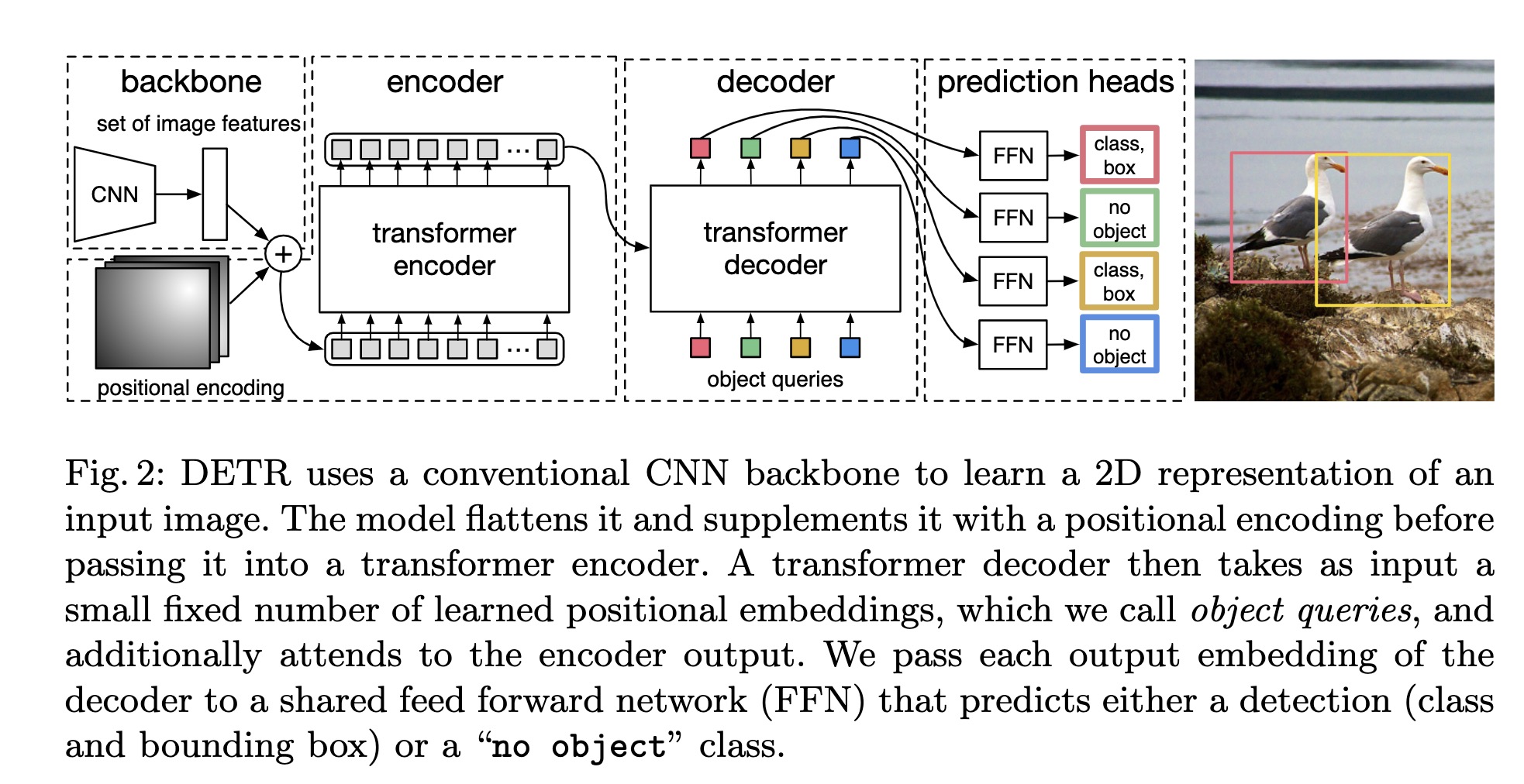
backbone
backbone 采用传统的CNN网络,记输入图像大小为 3 * H * W, 经过backbone后得到特征图大小为 C * h * w, 代码中为 C= 2048, h = H /32, w = W / 32. 在backbone 提取特征后会经过 1 x 1 卷积对通道降维,代码中将 C 降维到256. 特征为 256 x h x w, 由于transformer的输入为一维数据,将特征展开为 256 x (h x w), 可以理解为 h x w 个像素点,每个像素点特征为向量为 (1, 256)
src = src.flatten(2).permute(2, 0, 1) # (h x w, batch_size, 256)
和NLP transformer一样,训练时以batch输入, 需要将图片填充到最大的输入图片大小,所以每张图片有个二维mask, 标记该像素点是否是填充的, 该mask 在backbone 得到图片特征图后会插值成特征图宽和高. 即假如特征图大小为 8 x 8 , mask 会resize为 8 x 8, 计算attention的时候避免填充位置影响attention
# resize mask
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
# 输入到transformer之前,展开为一维
mask = mask.flatten(1) # (batch_size, h x w)
positional encoding
由于transformer 本身不能表达位置信息,需要增加位置编码,同时对于目标检测而言,位置编码应该是二维的,包含x方向与y方向。在代码中有两种实现,一种是写死的,一种是可学习的。
不贴代码了,主要重点是 positional encoding 的大小和 backbone 最后的特征图大小一样,按上诉例子即为 8 x 8, 特征维度也为 256. 同时,输入到transformer之前,需要展开为一维:
pos_embed = pos_embed.flatten(2).permute(2, 0, 1) # (h*w, batch_size, 256)
encoder
代码中的encoder层前向传播有两种形式,主要就是先norm还是后norm, 首先将 提取的图像特征与pos embedding 进行相加得到 query 与 key.
此处有个细节,在原始transformer和vit(transformer用于图像分类)中, 输入encoder q,k,v 是同一个向量,在这里面只有q 和 k 包含位置信息,v 是不包含位置信息的,这也没毛病,attention主要是 q 和 k, 这俩得包含位置信息
经过encoder 后,输出特征为 (h x w, batchsize, 256)
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
decoder
decoder 结构整体和transformer中结构一样,区别是detr 中decoder的输入是并行输入且固定大小(大小取决于希望的最大检测数)。对于seq2seq模型而言,它是输入一个特征预测下一个,decoder的query 可以理解为待查询的值,即我向decoder输入一个特征向量,我要在encoder中查询最相关的特征。目标检测不存在输入一个预测下一个这样的机制,所以需要设计一个目标检测的query,同时decoder也是不包含位置信息的,需要增加位置信息。detr中设计了固定大小的可学习的positional encodings,也就是object queries,通俗讲就是希望通过学习使得每个object query关注图像不同的区域,告诉各自负责的区域有没有物体以及物体的坐标,下图是取了100个object query中的20个预测的box的分布,可以看出,每个object query确实关注不同的区域(玄学啊)

在训练时,作者使用了辅助损失,即在每一层decoder输出都进行预测,计算损失,推理时只使用最后一层decoder输出预测目标。
prediction head
- 分类头:一个全连接层
- box头:FFN,简单多层感知机
预测头是共享的,即transformer decoder 输出 N个特征向量,每个特征向量都用该预测头。
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
class MLP(nn.Module):
""" Very simple multi-layer perceptron (also called FFN)"""
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
return x
二部匹配与损失
transformer decoder 输入 object queries 为 N, 那么就会得到 N 个预测目标 (类别,x,y,w,h),那么gt 需要个数也为N,不够以 no_object 填充,预测结果集合和gt集合均为N,然后使用二部图进行最佳匹配,保证每个只能对应一个(关于二部图匹配不细说了,自己还得再充充电)最后计算损失, 最小化二部图匹配损失。
损失计算包含分类损失与坐标损失:
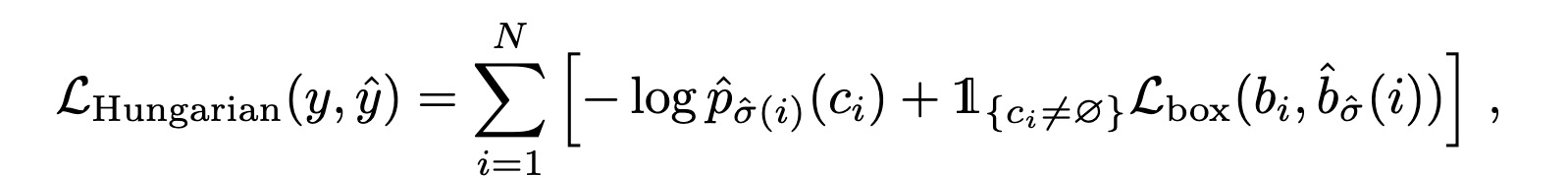
坐标损失不计算 no_object, 坐标损失包含L1 loss和iou loss.
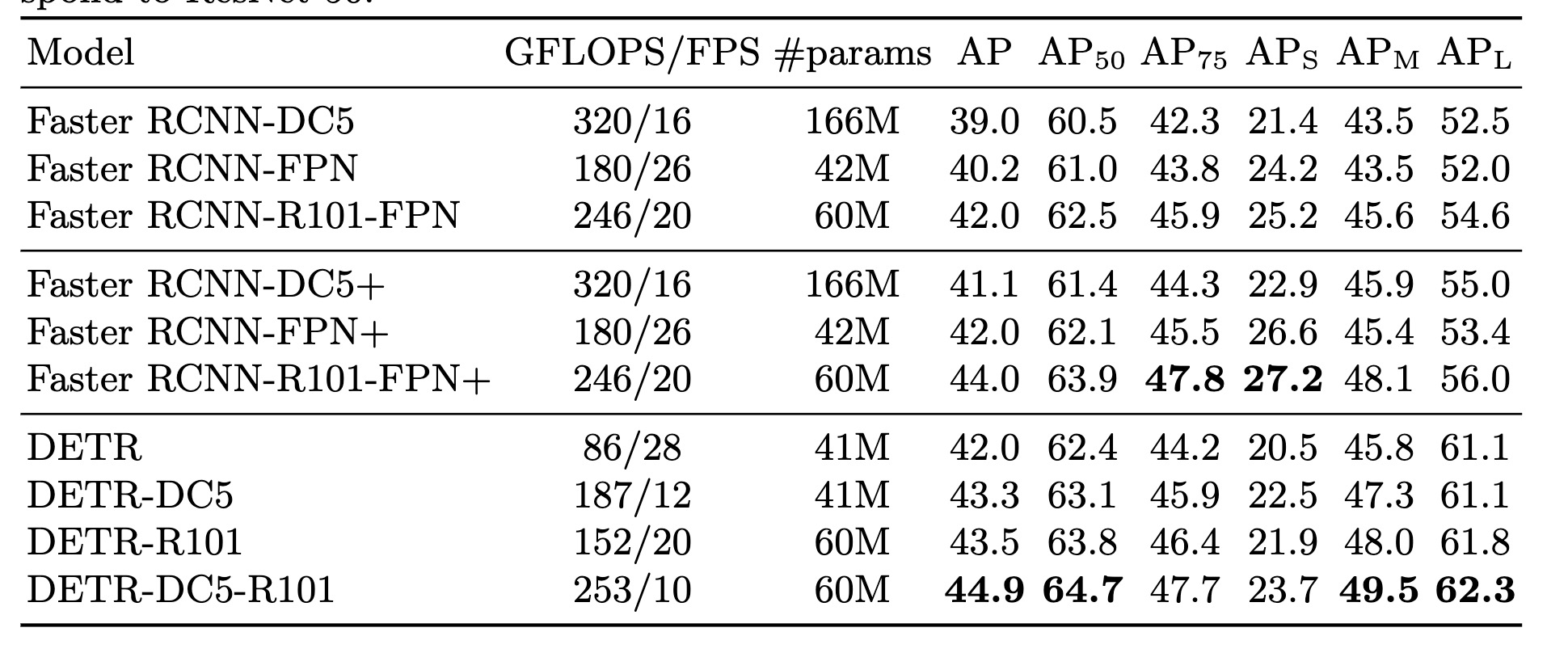
vs sota on coco-val
Visualizing attention


