YOLOv4: Optimal Speed and Accuracy of Object Detection论文解读
最近目标检测又出了yolo-v4,作为一个做目标检测的不可不膜拜膜拜。首先由于约瑟夫大神已经退出CV,yolo-v4 的一作是DarkNet的维护者,但还是加入了DarkNet官方。个人觉得这篇文章的对我的最大意义在于对现有的目标检测算法的结构以及各种训练trick作了对比,读完之后又加深了对该领域的一些理解。总之,论文结合各种最新trick来改进yolo-v3,效果还是很强的
贡献
如原文摘要中所说的: 目前有大量的特色功能能够提升CNN的性能。作者使用了目前流行的 Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT), Mish-activation, 以及 Mosaic数据增强, DropBlock 正则, CIoU 损失. 在COCO上达到了sota的效果。
- 发展出一个强力且有效的目标检测模型,使每个人都可以在1080 Ti或者2080 Ti上训练出一个超级快和准确的目标检测模型。
- 在训练阶段验证了目前最佳 Bag-of- Freebies 和 Bag-of-Specials方法的作用
- 修改了sota的方法,包括CBN,PAN,SAM,使其更加适合单GPU训练
回顾目标检测
模型
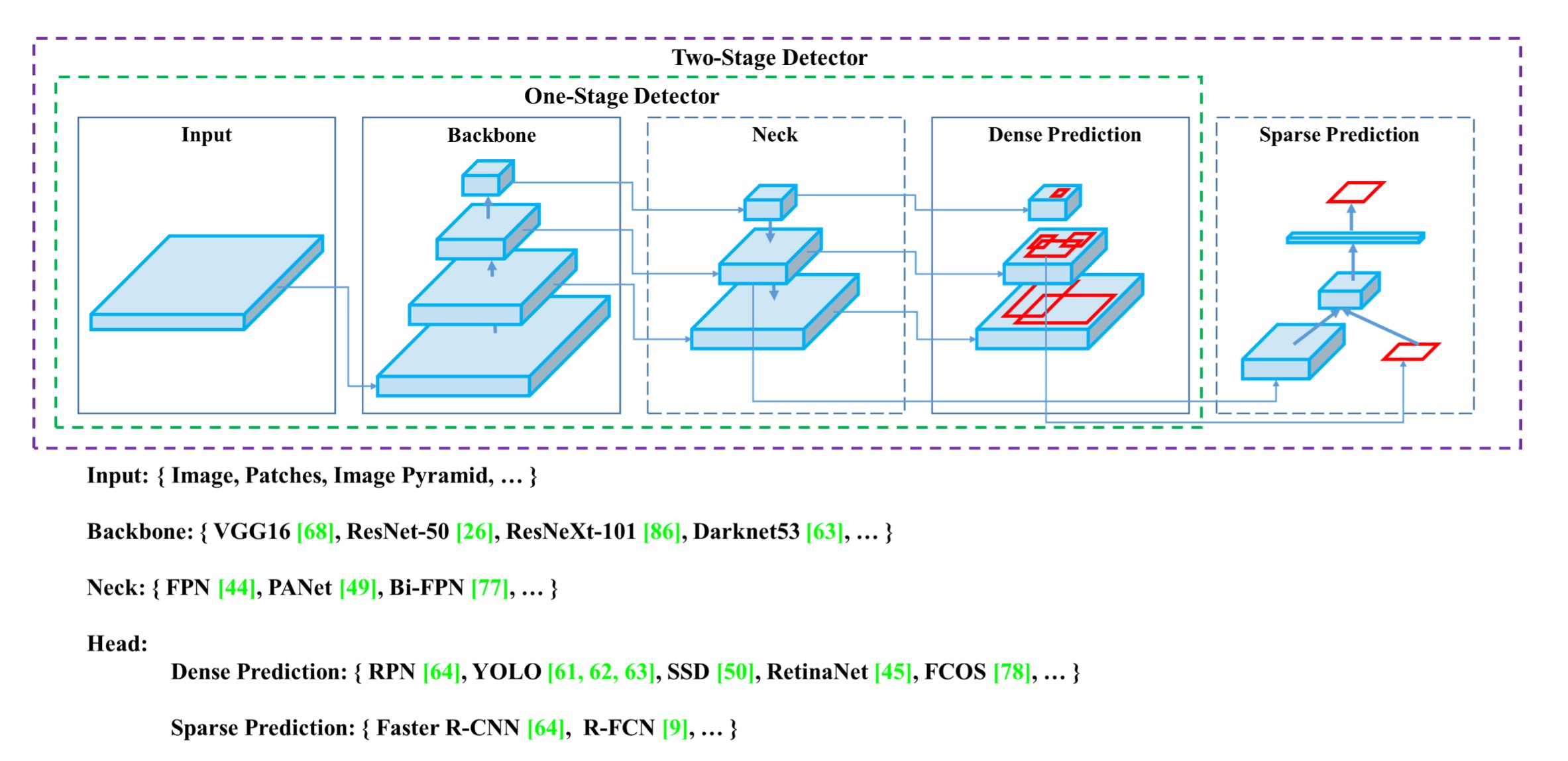
主流的目标检测算法可以归纳为上图的结构:
- 输入:图像、图像块或者图像金字塔
- backbones: VGG16, Resnet50,Darknet等
- Neck: 分为两类 1)可选构件–SPP, ASPP, RFB, SAM 2)路径聚合构件–FPN,PAN,Bi-FPN等
- 检测head:分为两类 1)稠密预测(单阶段)– 基于anchor的RPN,SSD,YOLO,RetinaNet以及anchor free的 FCOS,CornerNet等 2)稀疏预测(two stage)Faster rcnn等
Bag of freebies(免费赠品?)
通常,目标检测网络都是离线训练。在离线训练的时候通常采用一些措施来提升精度但是并不会影响推理阶段。把这些技巧称为BOF。主要是指训练时采用的一些技巧: 数据增强,dropout、dropconnect等,在线难例挖掘,focal loss,基于IOU的loss等。
Bag of specials
对于那些只增加少量推理代价却能显著提高目标检测精度的插件模块和后处理方法,称之为“Bag of specials”. 一般来说,这些插件模块是为了增强模型中的某些属性,如扩大感受野、引入注意力机制、增强特征集成能力等,后处理是筛选模型预测结果的一种方法。
- 提升感受野的方法有:SPP,ASPP,RFB
- 注意力机制模块有:SE(Squeeze-and-Excitation)模块,SAM(Spatial Attention Module)模块
- 特征集成:skip-connection, FPN以及各种FPN变种
- 激活函数:Relu, LRelu, PRelu, Mish, Swish 等等
- 后处理方法: NMS,soft-NMS, Diou nms
Methodology
网络结构选择
目标时为了得到网络分辨率,卷积层数量,参数量和卷积层输出数量之间的最佳平衡。作者研究表明:CSPResNeXt50在分类方面优于CSPDarkNet53,而在检测方面反而表现要差。
确定了主干网络后,下一步是选择可添加模块以提升感受野和最佳的从不同检测层的参数聚合方法:FPN, Bi-FPN等,检测网络需要以下特性:
- 更高的输入分辨率–更好的检测小目标
- 更多的网路层–网络的输入增大则需要更大的感受野
- 更多的参数–更大的模型可以同时检测不同大小的目标
概括来说:选择具有更大感受野、更大参数的模型作为backbone
不同大小的感受野带来的影响可以总结如下:
- 增大到物体大小 – 可以看到整个物体
- 增大到网络大小 – 可以看到物体周围的背景
- 超过网络大小-增加图像点和最终激活之间的连接数
最终确定的YOLO-V4网络结构为: CSPDarknet53 backbone, SPP 模块, PANet path-aggregation neck, and YOLOv3 (anchor based) head。
BoF 和 BoS 的选择
为了在训练阶段提升目标检测,通常会采用以下技巧:
- 激活函数: ReLU, leaky-ReLU, parametric-ReLU, ReLU6, SELU, Swish, or Mish
- Bounding box 回归损失: MSE, IoU, GIoU, CIoU, DIoU
- 数据增强: CutOut, MixUp, CutMix
- 正则化方法:DropOut, DropPath, Spatial DropOut, or DropBlock
- 网络激活归一化:Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN) , Filter Response Normalization (FRN), or Cross-Iteration Batch Normalization (CBN)
- 跳跃链接: Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections (CSP)
激活函数方面选择Mish;正则化方面选择DropBlock;由于聚焦在单GPU,故而未考虑SyncBN
其它改进
为了更加适合单GPU训练, 还做了一下改进
- 提出新的数据增强方法: Mosaic, 和自对抗训练(SAT)
- 通过遗传算法选择最佳超参
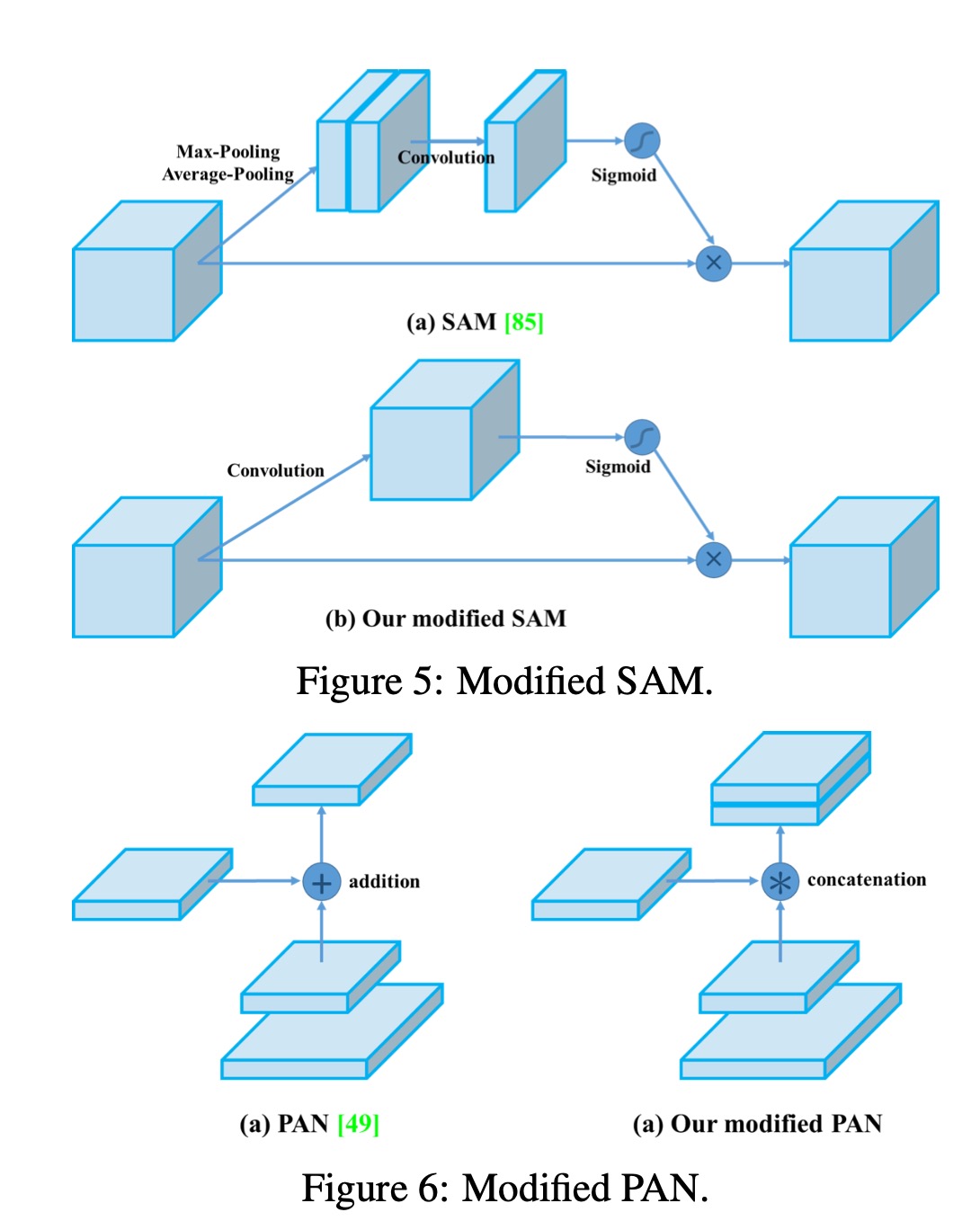
- 修改了SAM,PAN,CmBN
Mosaic数据增强方法如下, 将四张不同语境的图片混合在一起:

自对抗训练: 自对抗训练(SAT)也代表了一种新的数据增强技术,在两个前向后向过程中进行操作。在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对自身进行了一次对抗性攻击,改变原始图像,从而制造出图像上没有所需对象的欺骗。在第二阶段中,训练神经网络以正常的方式检测修改图像上的目标。(到底怎么改变的读这个还不太清楚,还得有空去看看源码)
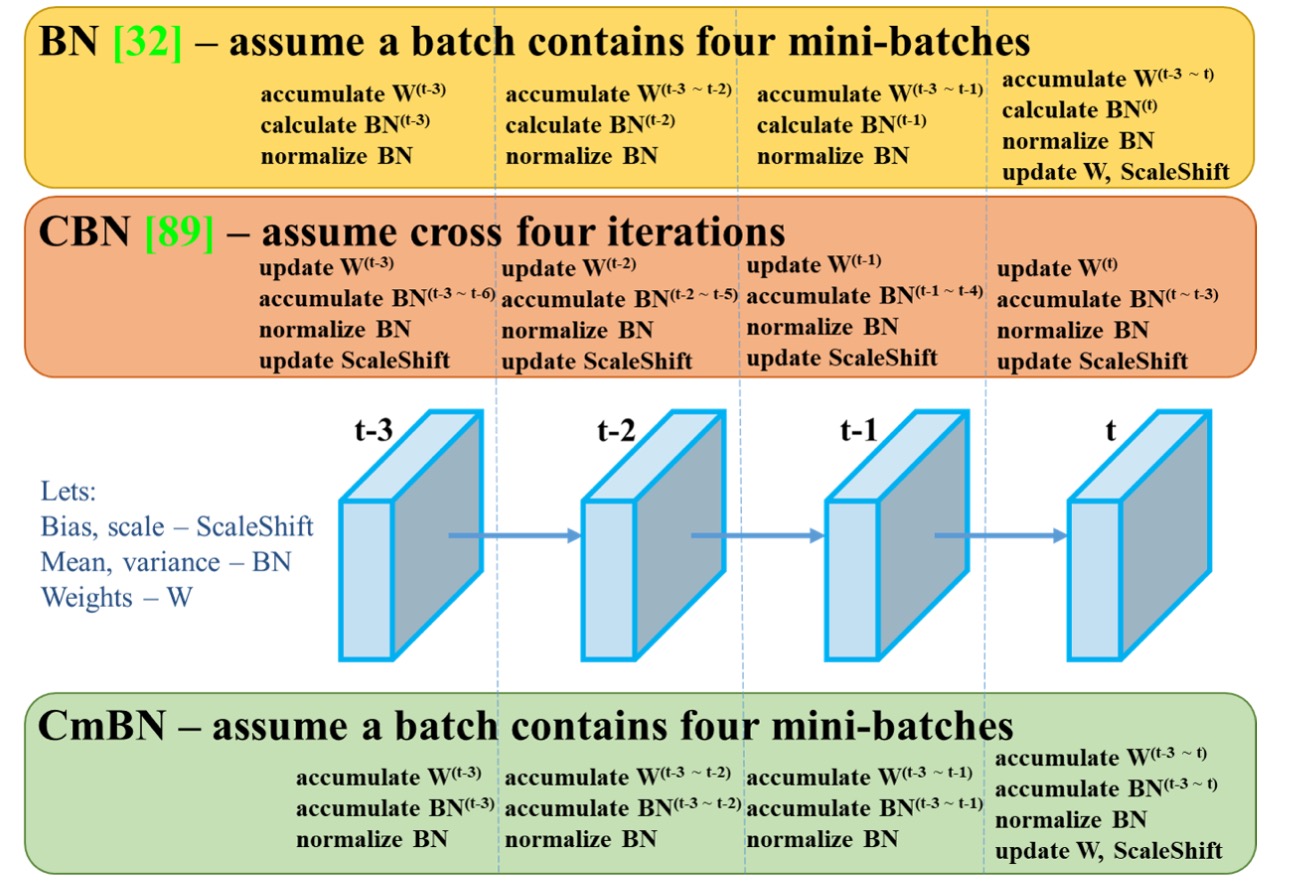
CmBN:
修改的SAM与PAN:
YOLO-v4 网络结构总结:
- Backbone: CSPDarknet53
- Neck: SPP, PAN
- Head: YOLOv3
YOLO-v4 trick:
- Bag of Freebies (BoF) for backbone: CutMix, Mosaic data augmentation, DropBlock regularization, Class label smoothing
- Bag of Specials (BoS) for backbone: Mish activation, Cross-stage partial connections (CSP), Multi-input weighted residual connections (MiWRC)
- Bag of Freebies (BoF) for detector: CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler , Optimal hyper-parameters, Random training shapes
- Bag of Specials (BoS) for detector: Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIoU-NMS
实验结果
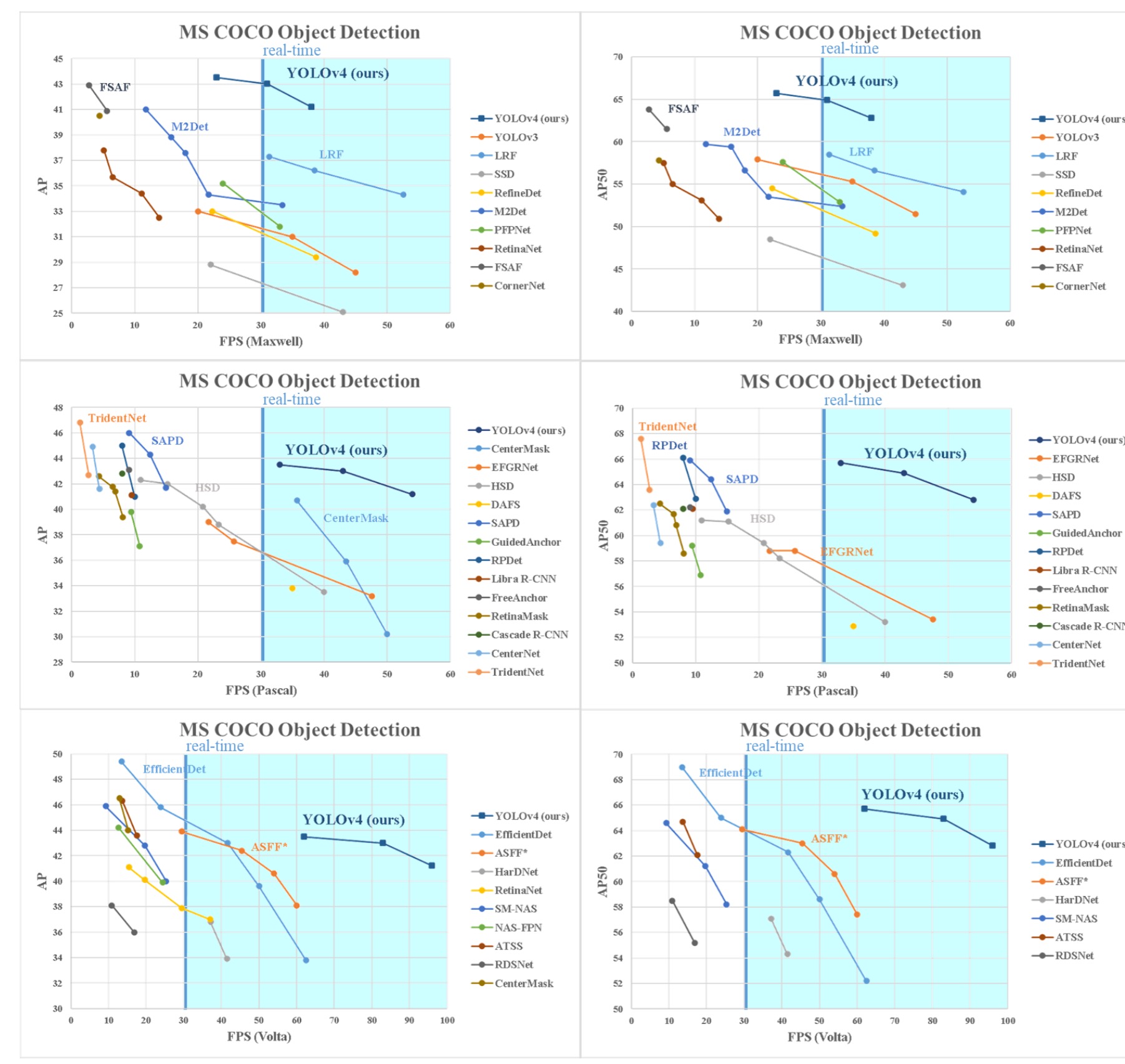
yolo-v4 可以说是做了特别多的对比实验,实验结果很多,这儿就放个最主要的对比吧,详细的请看原论文。