
灵魂三问 论文做了什么? 该论文是谷歌最近的新作,以语言建模的形式实现目标检测。 论文怎么做的? 将bounding box 和 类别标签离散化为token。
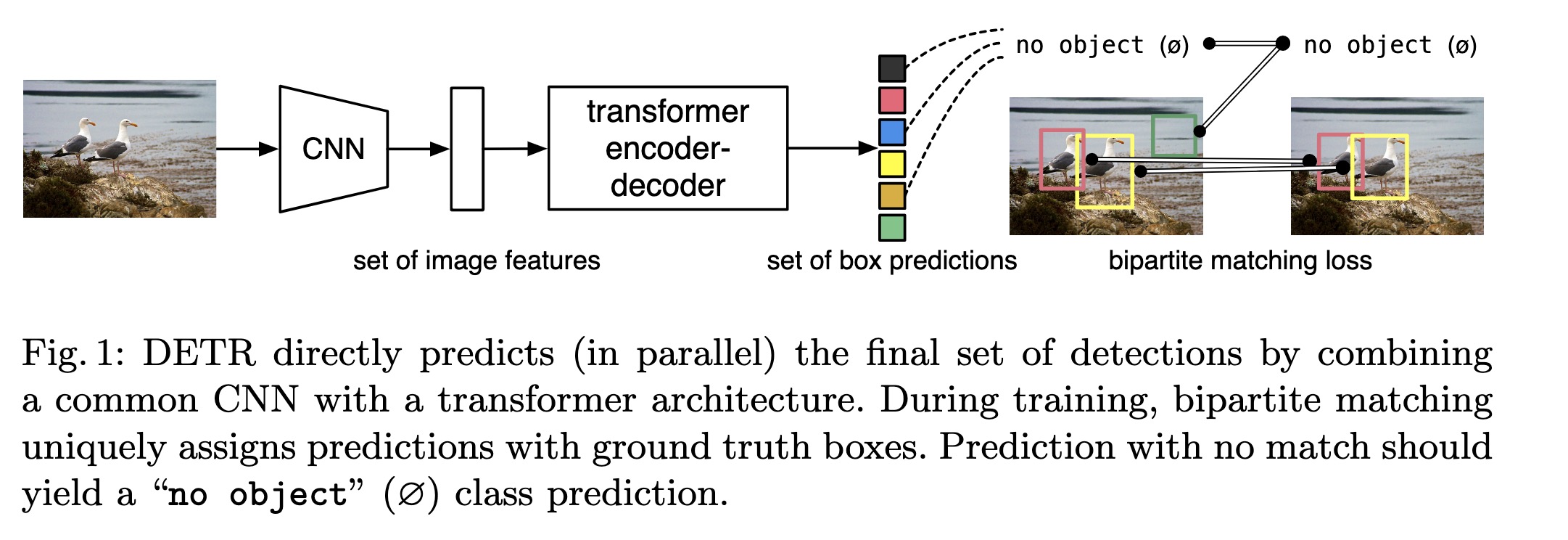
目前transformer在CV领域打的火热,前文记录了transformer用于图像分类的实现,本文主要记录transformer用于目标
训练过很多目标检测网络,个人觉得yolov5是使用过的收敛最快的网络,训练10多个epoch就能达到很高的P、R. 收敛快的原因也不是网络本身
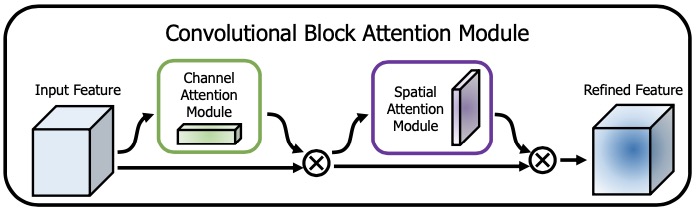
之前谈过SE-net, 对于目标检测或检测用于特征通道的attention, 今天记录一下CBAM模块, 对分类或检测中用来获取通道、空间位置的a
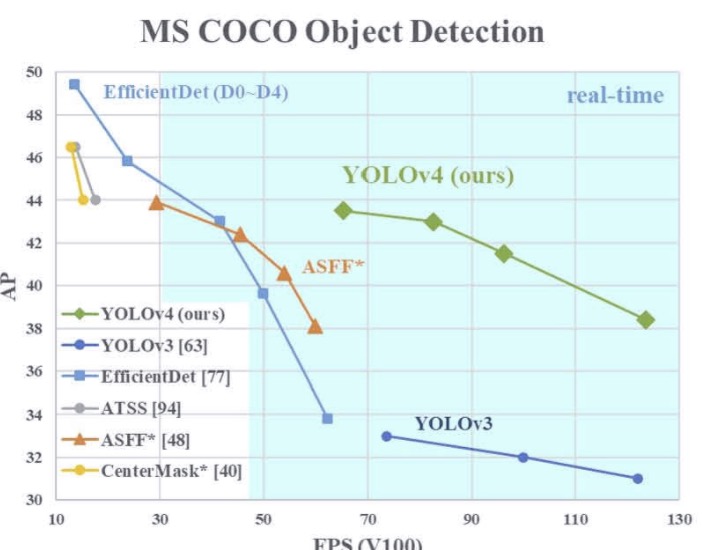
最近目标检测又出了yolo-v4,作为一个做目标检测的不可不膜拜膜拜。首先由于约瑟夫大神已经退出CV,yolo-v4 的一作是DarkNet的
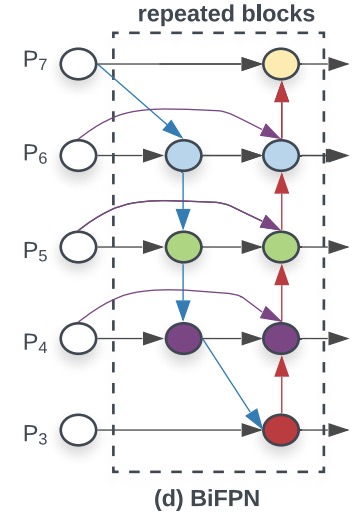
最近谷歌放出了 EfficientDet 论文与代码, 在COCO上取得了最好的MAP, 本文对 efficientDet 做个简要的总结, 同时对efficientNet也做个回顾. Efficie

主流的目标检测算法大多数是基于anchor box的, one-stage 的yolo-v2, yolo-v3, ssd…以及two-stage 的faster rcnn
在目标检测中, 存在正负样本类别不平衡的现象, 特别是对于单阶段的目标检测算法. 如果每张训练图片中目标个数还很少的话, 背景区域就占了绝大部分, 分

最近闲暇时自己在pytorch实现并训练了yolo-v2, 对yolo-v2的实现做一个简单的总结, 主要是loss 层, 别的地方都没啥难度 关于y

该篇论文来源于Intel, 如其名用来加速目标检测. 主要针对于 one-stage 的目标检测算法. 主要创新点 对于 one-stage 的目标检测算法而言, 由于其设置了大量的 default box, 然后
