
分布式训练基础
对于算法工程师而言,单卡跑不起来或者跑起来慢是很常见的问题,分布式训练各个框架都有支持。有时候训练模型一张卡放得下但误以为多卡一定就快,训练的时候使用多卡效率还不如单卡。也没有深入理解背后的原理,写这篇笔记以理解分布式训练中的 parameter server 算法与 Ring AllReduce 算法, 理解各自的工作原理即可
分布式训练,主要可以分为以下三种:
- 并行方式: 数据并行 VS 模型并行
- 参数更新方式: 同步更新 VS 异步更新
- 对于参数的同步更新方式,主流分为: parameter server VS AllReduce
并行方式
- 模型并行: 不同的GPU输入相同的数据,运行模型的不同部分,比如多层网络的不同层。比如网络太大,单卡已经装不小模型了,这种情况通讯开销大,各卡之间相当于前后依赖,毕竟模型各层之间是串行。
- 数据并行: 不同的GPU 运行相同的完整的模型,输入不同的数据。一般分布式都是这种方式。
更新方式
当采用数据并行时,由于每块GPU上运行一部分数据,需要考虑将每个GPU上的梯度如何进行汇总来更新模型参数。
- 同步更新:每个输入batch的数据会先按GPU划分到各个卡上,等所有GPU计算完成后,再统一计算新权值,然后所有GPU同步新值后,再进行下一轮计算。存在木桶效应,即同步更新会有等待,速度取决于最慢的那块GPU。但是实际一般采用同步更新,实现简单。
- 异步更新:每个GPU计算完梯度后,无需等待其他更新,立即更新整体权值并同步。异步更新没有等待,但是其实现考虑的因素太多,这儿也不深究了。
parameter server VS AllReduce
parameter server
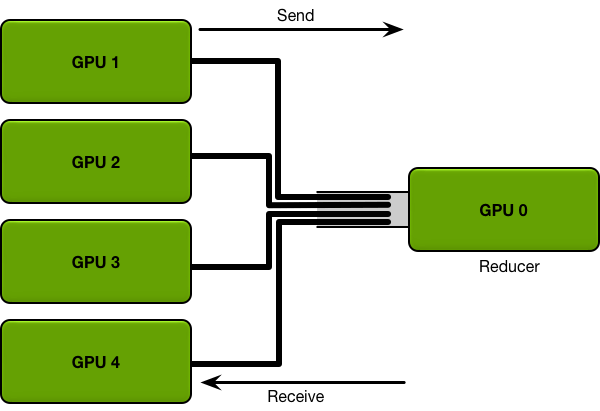
假如有5块GPU, 0号GPU为master,也是reducer, GPU 0将数据分成五份分到各个卡上,每张卡负责自己的那一份mini-batch的训练,得到grad后,返回给GPU 0上做累积,得到更新的权重参数后,再分发给各个卡. 导致木桶效应严重,所有的卡都要和master通信进行数据、梯度、参数的通信,时间开销大.
有N个GPU,通信一次完整的参数所需时间为K,那么使用PS架构,花费的通信成本为: $T = 2(N-1) K$,通信时间与GPU数量线性相关
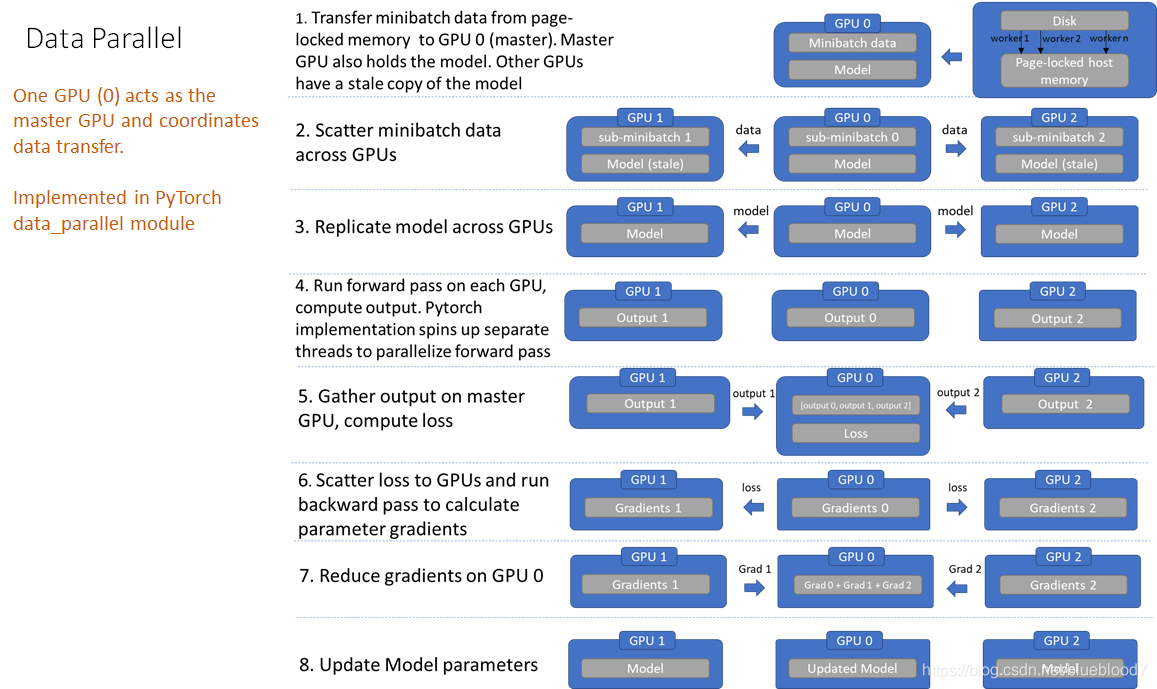
在pytorch中 data parallel 即采用 ps 算法,整个流程如下图:
ring AllReduce
该算法是百度在 《Bringing HPC techniques to deep learning 》提出:
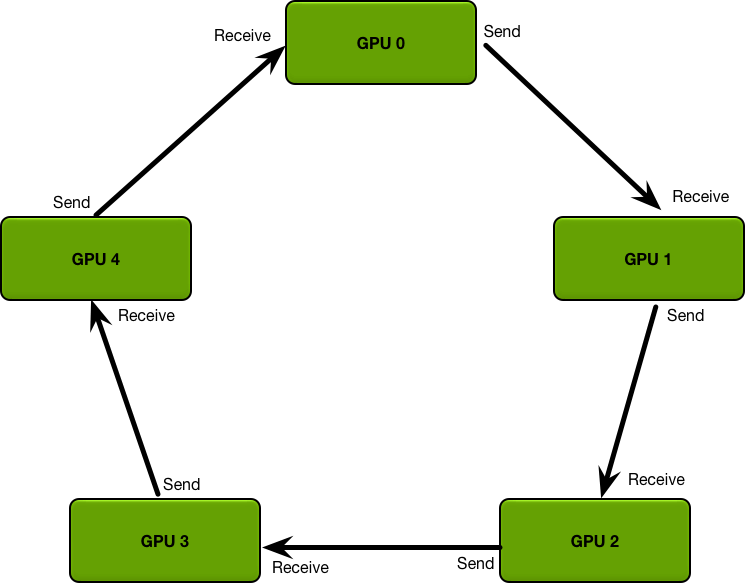
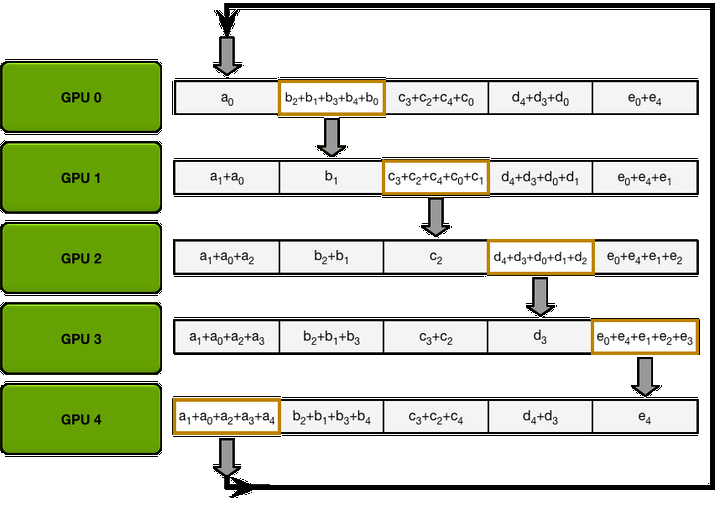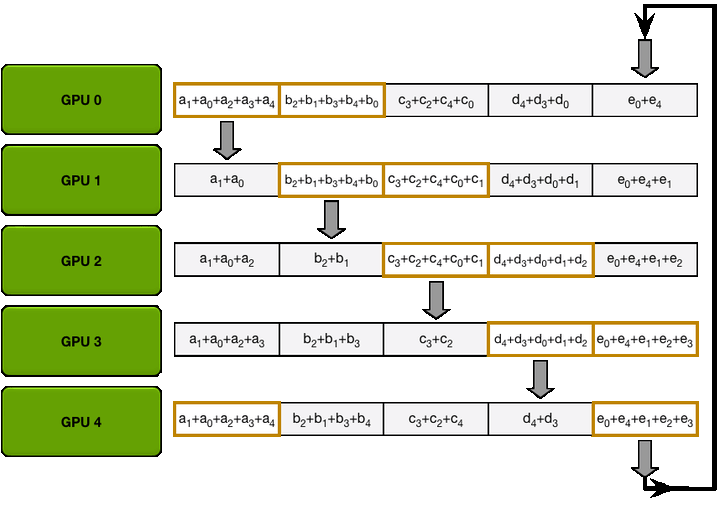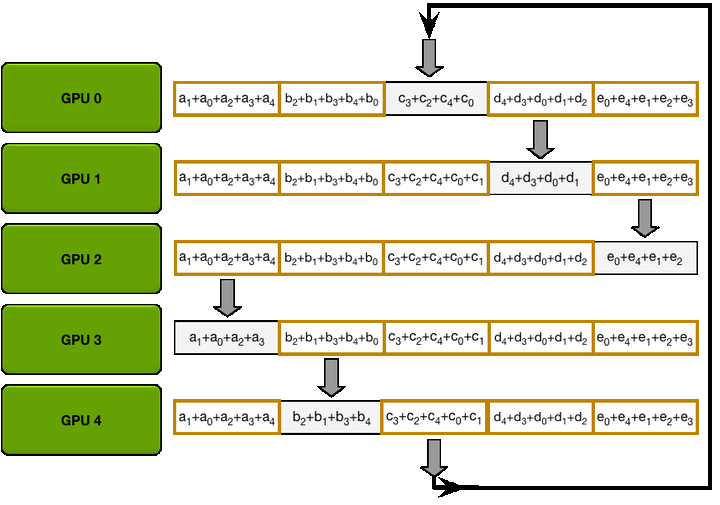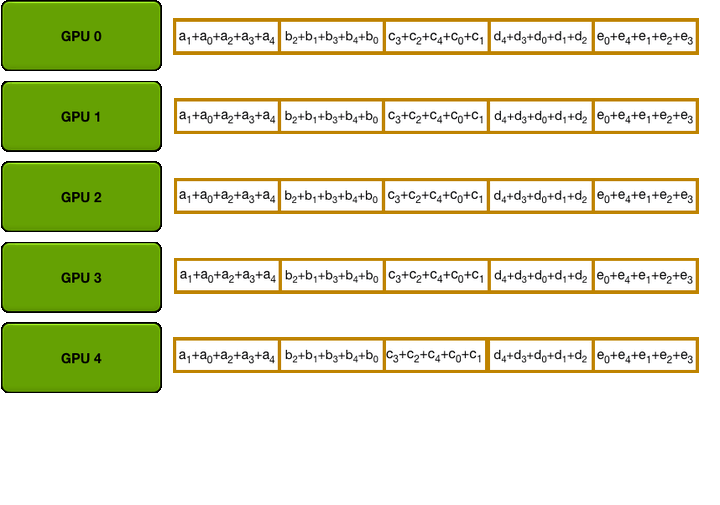
在 ring Allreduce 中,所有的GPU形成一个环。每个GPU有一个左邻居和一个右邻居;它只会向它的右邻居发送数据,并从它的左邻居接收数据,该算法分两步进行:第一步,scatter-reduce, 第二步:allgather.
第一步: 参数分为N份,相邻的GPU传递不同的参数,在传递N-1次之后,可以得到每一份参数的累积(在不同的GPU上)

在第一次迭代时,
| GPU | Send | Receive |
|---|---|---|
| 0 | Chunk 0 | Chunk 4 |
| 1 | Chunk 1 | Chunk 0 |
| 2 | Chunk 2 | Chunk 1 |
| 3 | Chunk 3 | Chunk 2 |
| 4 | Chunk 4 | Chunk 3 |
经过4轮迭代
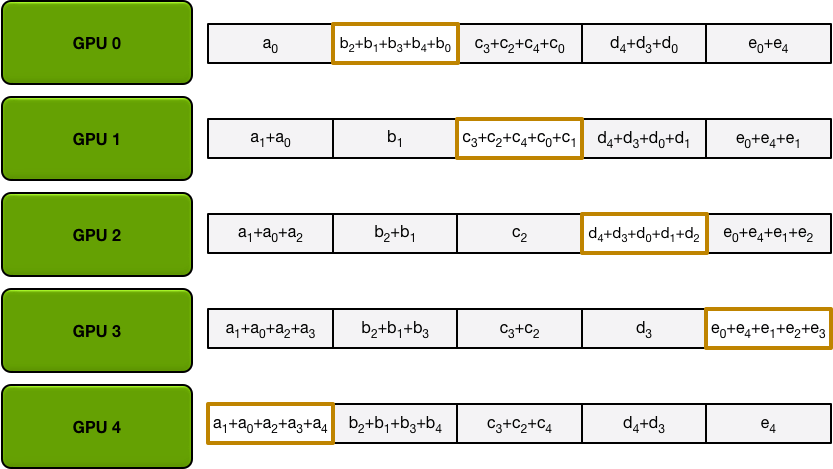
第二步:The Allgather
Allgather 也需要 N-1 次迭代,使每块GPU得到所有参数
在第一次迭代时:
| GPU | Send | Receive |
|---|---|---|
| 0 | Chunk 1 | Chunk 0 |
| 1 | Chunk 2 | Chunk 1 |
| 2 | Chunk 3 | Chunk 2 |
| 3 | Chunk 4 | Chunk 3 |
| 4 | Chunk 0 | Chunk 4 |
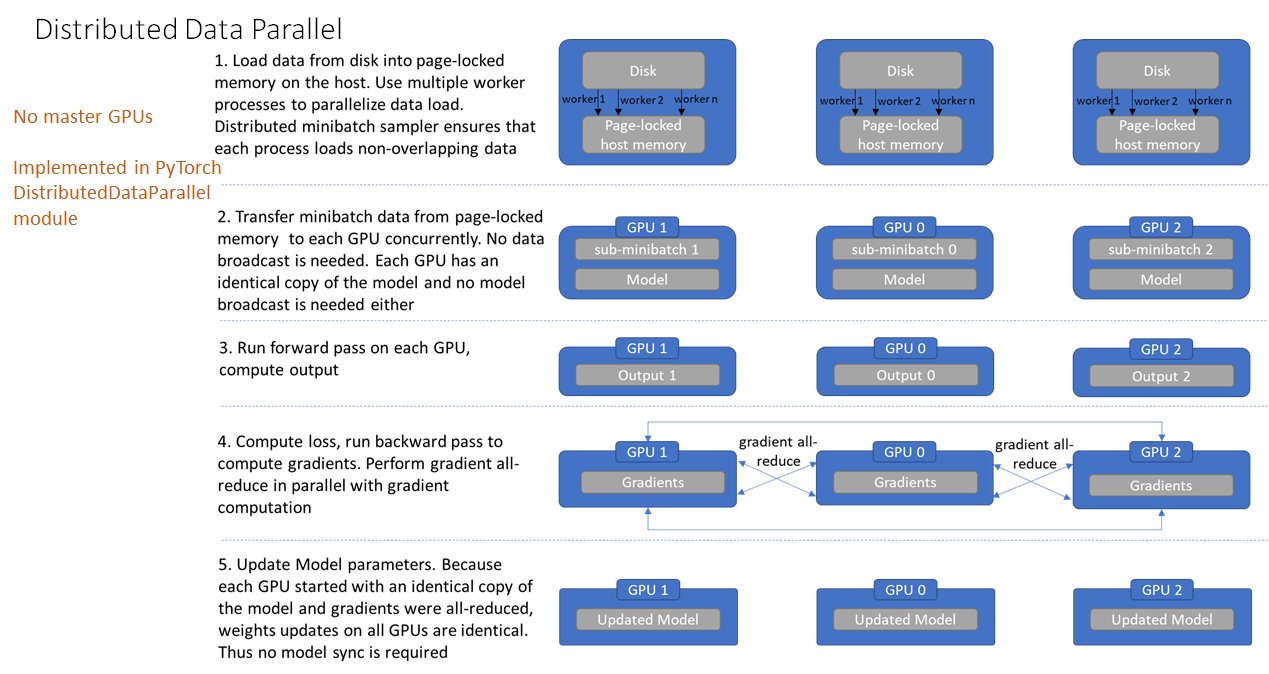
在pytorch中,DDP 即采用allreduce 算法,整体流程如下:
ref
https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/
