Vision Transformer 笔记
本文主要从代码角度记录使用transformer实现图像分类的流程. 代码vit-pytorch/
总体结构
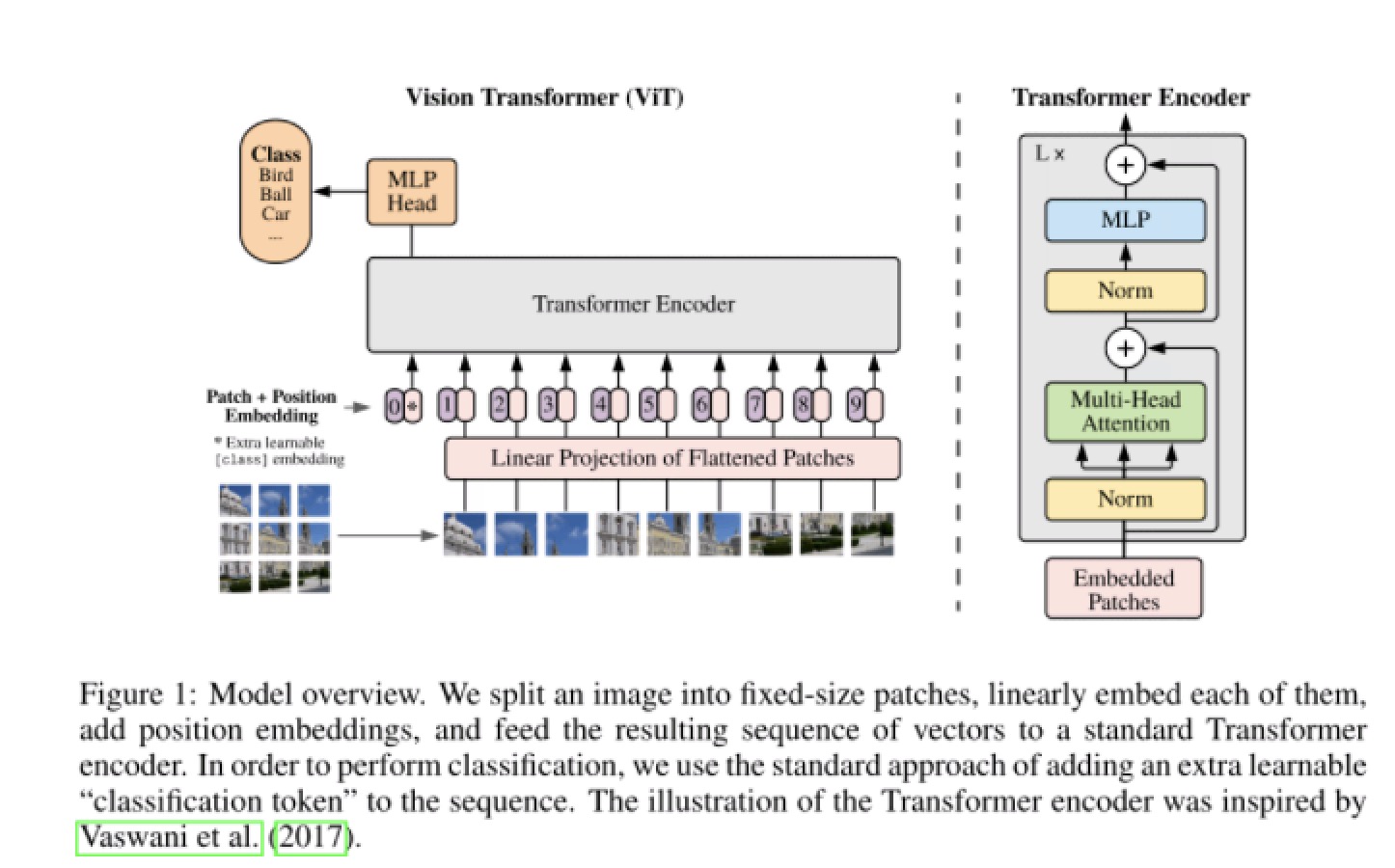
结合上图与代码展开:
前向传播过程代码如下:
def forward(self, img, mask=None):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x, mask)
x = x.mean(dim=1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
主要由5步构成:
- 将图片变成图片块并进行embedding
- 生成用于分类的token
- 编码位置信息 pos_embedding
- transformer 编码器模块进行attention计算
- mlp 分类头进行分类
patch_embedding
num_patches = (image_size // patch_size) ** 2
patch_dim = channels * patch_size ** 2
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
range('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_size, p2=patch_size),
nn.Linear(patch_dim, dim),
)
假如输入图片大小为 H * W * C,将图片切分为 9 块, 每块子图的宽高为(p, p), 将每个子图展开为一维向量大小为 p * p * c, 总输入变为 9 * (p * p * c), 每张图片变成了9个一维向量。然后连接一个全连接层对每个向量进行embedding, 输出维度为 dim
分类token
在vit中,如上图,进过编码器后得到9个图片块对应的向量,通俗说这9个图像块已经互相建立了联系,看到了彼此,但是该用哪一个去进行分类呢?因此增加了一个专用于分类的向量,该向量时可学习的。大白话理解就是:这9个也不要争了,增加一个来统领全局,由它来学的整个图片的信息。
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# 维度和patch embedding的维度一样,前向传播时会concat 到embedding 前面
pos_embedding
与transformer一样,对图像进行分块后失去了空间位置信息。原始的Transformer引入了一个 Positional encoding来加入序列的位置信息,transformer中的 Positional encoding 是写死的,在这里也引入的pos_embedding,是用一个可训练的变量替代。
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
num_patches + 1 , 是因为增加了一个分类token
transformer 编码器模块进行attention计算
原版transformer的encoder一样进行编码
mlp 分类头进行分类
self.mlp_head = nn.Sequential(
nn.layerNorm(dim),
nn.Linear(dim, num_classes))
即一个全连接层进行映射到世界类别进行分类, 在vit前向传播过程中,通常只取第一个分类token $x[:0]$ 输入到 mlp 中.
x = x.mean(dim=1) if self.pool == 'mean' else x[:, 0]
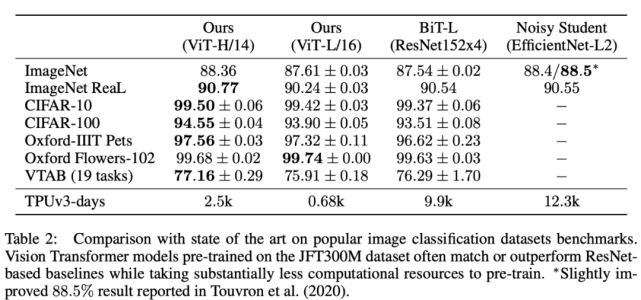
vs sota