
OHEM: 在线困难样本挖掘: Training Region-based Object Detectors with Online Hard Example Mining
在目标检测中, 存在正负样本类别不平衡的现象, 特别是对于单阶段的目标检测算法. 如果每张训练图片中目标个数还很少的话, 背景区域就占了绝大部分, 分类时网络只需要将前景分为背景就可以得到很小的损失, 导致训练失败. focal loss 也是为了解决这个问题, 今天阅读的 OHEM 也是为了解决这个问题.
OHEM 主要针对于检测中的前景背景分类, 对于yolo而言就是confidence头, 不是具体到某个类别的分类. 造成这个的原因主要是类别不平衡, 论文中提出了两个实现.
one stage: TopK Loss
即在训练时根据损失对负样本进行排序, 选择前K个loss较大的负样本进行损失统计,而loss较小的负样本不计入损失, 这里的前K可以是一个百分比,即前K%的hard样本. 一般设置成一个正负样本的比例, 根据图片中正样本的个数选择一定比列的负样本. 对于单阶段目标检测算法, 即选择loss 大的anchor, 对基于RPN的则是选择loss 大的 ROI
two stage: dual ROI Network
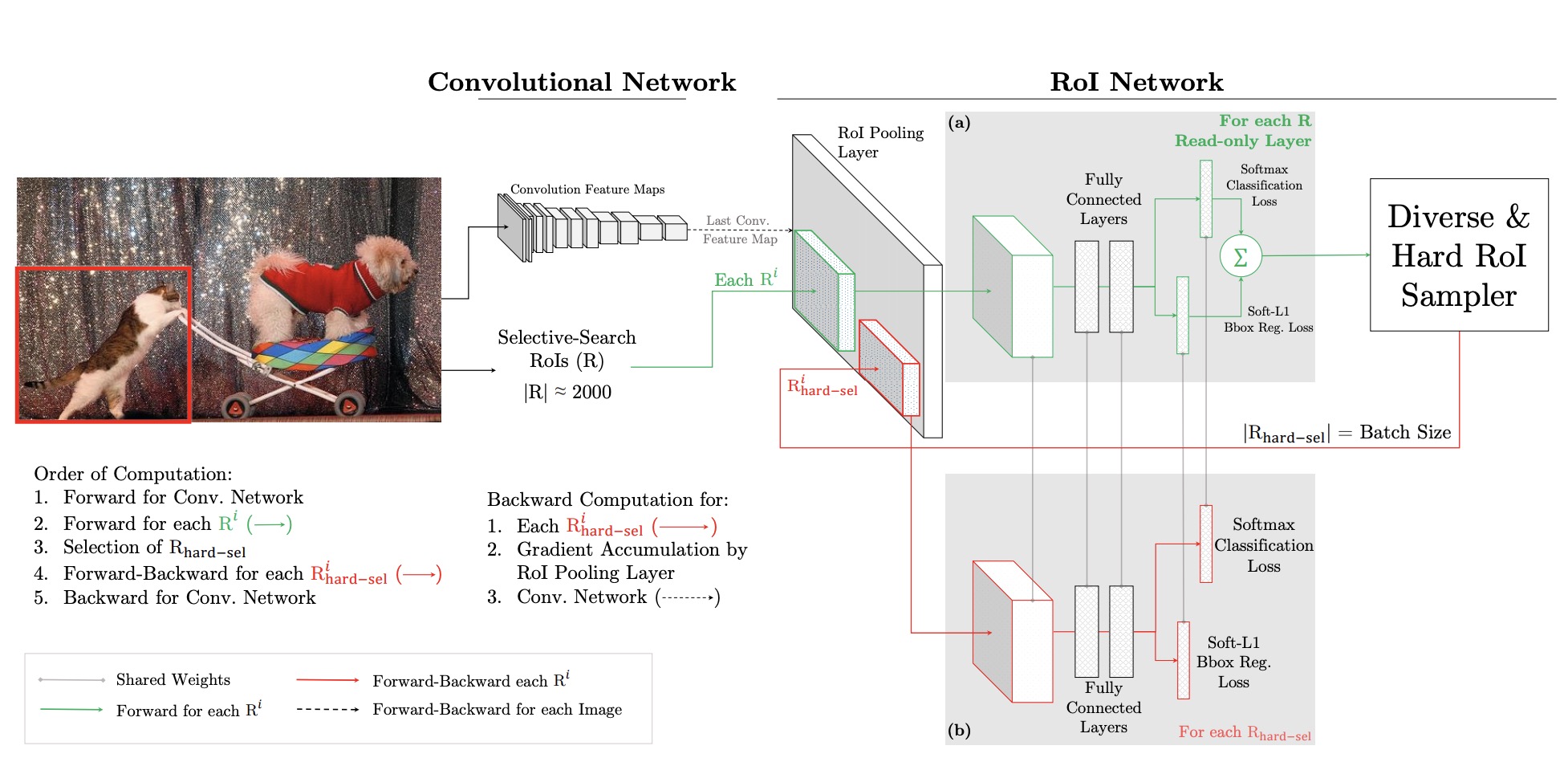
如上图是应用于Faster Rcnn中, 包含两个ROI network, 上面一个ROI network是只读的, 为所有的ROI在前向传递的时候分配空间. 下面一个ROI network则同时为前向和后向分配空间. 首先,ROI经过ROI plooling层生成feature map,然后进入只读的ROI network得到所有ROI的loss, 然后是hard ROI sampler结构根据损失排序选出hard example, 并把这些hard example作为下面那个ROI network的输入.
