Pix2seq阅读笔记
灵魂三问
论文做了什么?
该论文是谷歌最近的新作,以语言建模的形式实现目标检测。
论文怎么做的?
- 将bounding box 和 类别标签离散化为token。对应于语言模型的token,网络预测各个token的概率。
- 通过编码器-解码器机制将图片像素转换为目标序列。
- 最后通过最大似然估计优化目标函数。
其机制上和 image caption基本一致,这个是读出图片中有哪些物体以及他们的位置。只不过之前的image caption 基本采用sequence2sequence,一般是CNN提取图片特征 + LSTM、transformer解码。
论文的贡献?
该论文提出了一个新的目标检测方式,即以语言建模的形式实现。而且其结构简单,可以延伸到更多的场景和应用中。基本上是一个新的baseline,论文也是和 faster R-CNN 和 detr 做了对比,并没有和YOLOv4,v5等对比。
结构
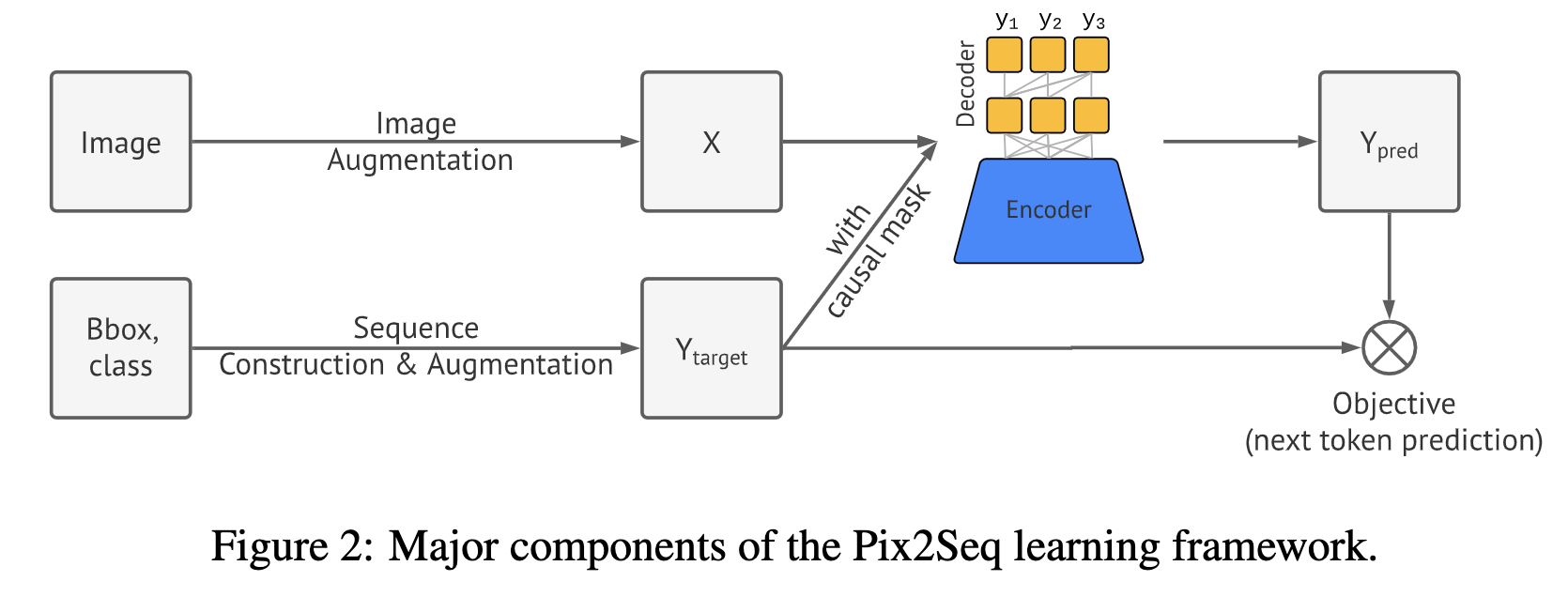
如上图所示,主要分为几个部分:
- image augmention: 图像增强,比如裁剪随机缩放等
- sequence construction and augmentaion: 对Bbox 和类别标签进行离散化为token
- Architecture: 编码器-解码器结构
- Objective/loss function: 最大化对数似然
序列构建、目标描述
序列构建是将 Bbox和类别标签离散化为token. 一个检测目标被离散化为[ $y_ {min}$ , $x_ {min}$, $y_ {max}$, $x_ {min}$, c ]
因为类别本身就是离散的,所有不用特别考虑。主要针对坐标的离散化,文中将坐标离散为 [1, $n _{bins}$], bins 的数量可自己根据实际情况设定。那么词汇表大小为 bins的数量 + 类别的数量。 比如一张 600 * 600 的图片,坐标量化为600个bins,那么网络预测的时候词汇表中哪个 bin 的概率最高,就认为该位置为物体的坐标。
因此,固定输入尺寸下,bins的数量越小,坐标量化就越不准,小目标会丢失,bins的数量刚好等于高或宽中的最大值的话,bins就和像素点一一对应。当然,如果输入太大,词汇表就会很大,不过对于目标检测而言,相对于语言模型的词汇表也算小了。

一张图片里面可能有多个目标,对给定的图片生成一个目标描述序列,[物体1, 物体2, …]。同时,对目标检测而言,物体出现的顺序是不重要的,作者采用随机排序策略, 每个物体在序列中出现的位置是随机的。
类似于语言模型,需要标记句子的结束,文中引入 EOS token 标记序列的结束。
网络架构、目标函数以及推理
网络架构
整体结构采用 编码器-解码器结构,编码器将图片编码到高维特征空间,可使用 ConvNet、transformer或者二者的组合,解码器使用transformer的decoder,一次生成一个token。不再需要 proposal和回归。
目标函数
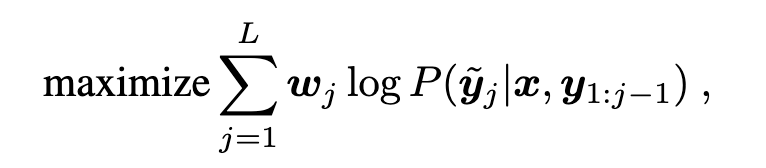
和语言模型一致,token的预测。w为预指定的token权重。
推理
推理时可取最大概率,即arg max, 即 top-1 (top-k 采样), 作者对比采用核采样( nucleus sampling)的召回更高,即 top-p.
序列增强整合任务先验
存在的问题:预测会提前结束,即物体没有全部召回的情况下,EOS token 就出现。 可能引起的原因:
- 标注噪声
- 某些物体的识别和定位不确定
可以通过人工延迟 EOS的出现,但是会导致预测噪声和重复预测。
作者引入序列增强,即对输入的序列中融合真实的和合成的噪声 tokens,同时修改目标序列让网络能够识别噪声。如下图:

个人理解这么做就好比之前的目标检测网络,回归分类的时候既有目标也有背景,引入噪声 token 也相当于引入了背景,让网络具有了更广识别能力。
在引入序列增强后显著延迟了 EOS的出现,提升召回,但是噪声和重复预测的频率没有增加。让网络预测输出最大长度,产生指定长度的预测目标序列。同时,对于预测为噪声类的,以真实类中概率最大的标记它。
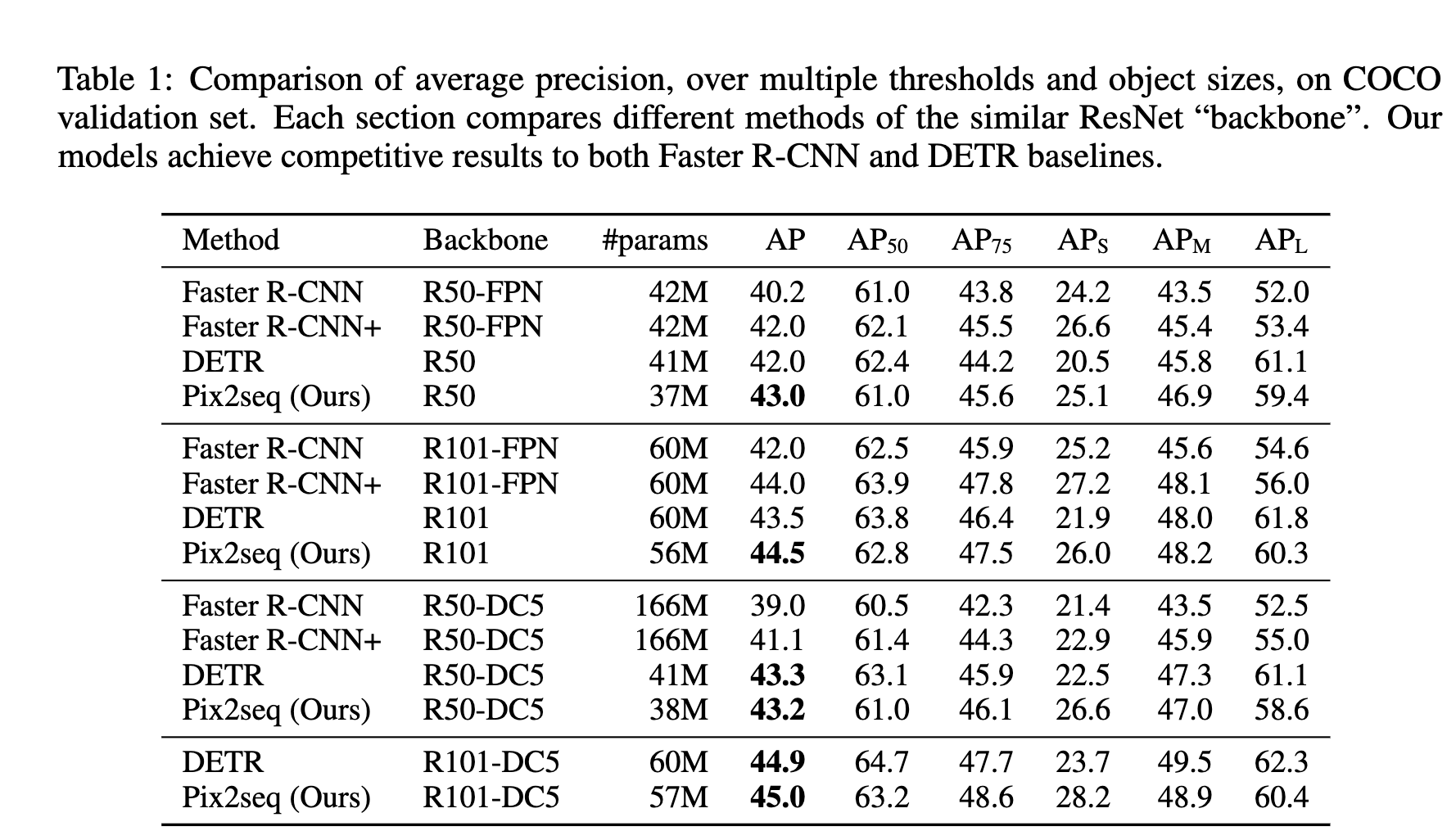
实现结果