
object detection(3): Fast rcnn
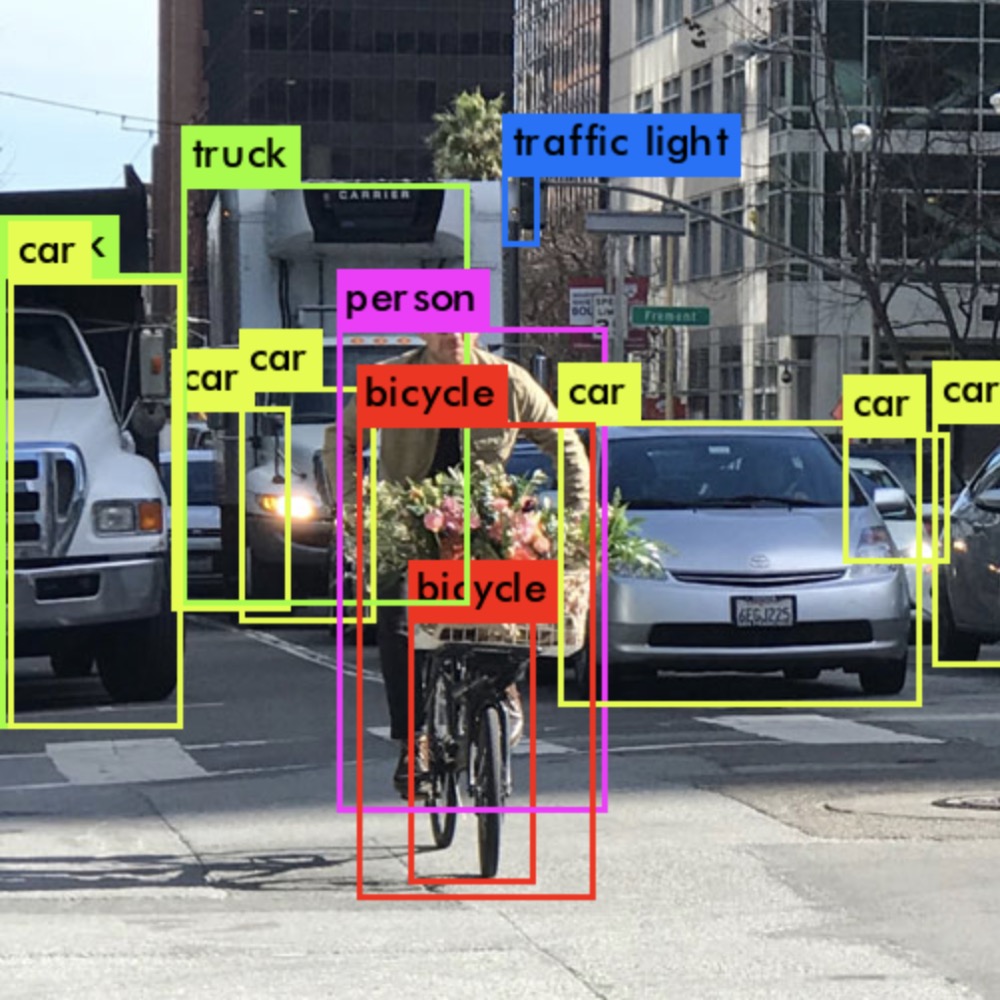
主要贡献
- RCNN, SPPnet的训练是 multi-stage的, 需要每一步训练一个模型. faste rcnn 通过 multi-task loss 将分类与边框回归融合到网络中, 前两者为训练SVM和线性回归器
- 提出ROI pooling 层
- 提升精度、速度
网络架构
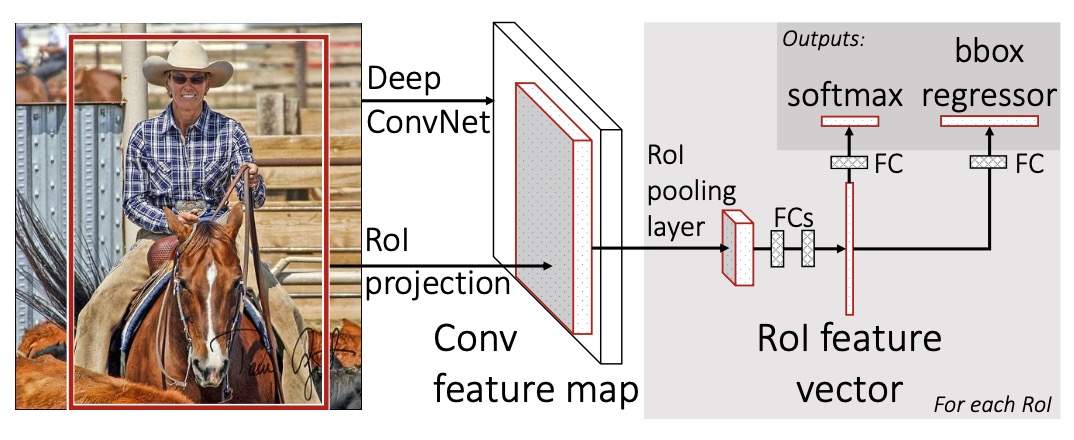
fast rcnn 检测流程如上图所示:
- 输入图片, 使用 SS 算法得到一定数量的 region proposals
- 使用CNN网络对图像提取特征, 得到最后一次卷积层的feature maps
- 将 region proposals(即 ROI) 映射到 feature maps 上, 得到每一个ROI区域的feature maps
- 对于每一个ROI, 通过 ROI pooling 层, 将其feature 池化为固定大小的特征, 然后经过一些列fc, 最后分别输出 softmax 分类与 bounding box 回归.
The RoI pooling layer
ROI 池化层先将 ROI 对应的 feature maps 划分为 $H * W$ 大小(论文中设为 7 * 7 to vgg16), 然后对其中每个小 grid 进行最大池化. ROI 池化层相当于单尺度的SPP 层.

如上图所示, 有两个尺寸不同 ROI 区域, 为了得到相同大小的 embedding, 将每个 ROI 划分为相同数量的($H * W$) grid, 然后对每个 grid 进行最大池化得到一个数值. 那么不同尺寸的 ROI 区域得到的 embedding 大小都一样.
示例如下,假设特征图为:
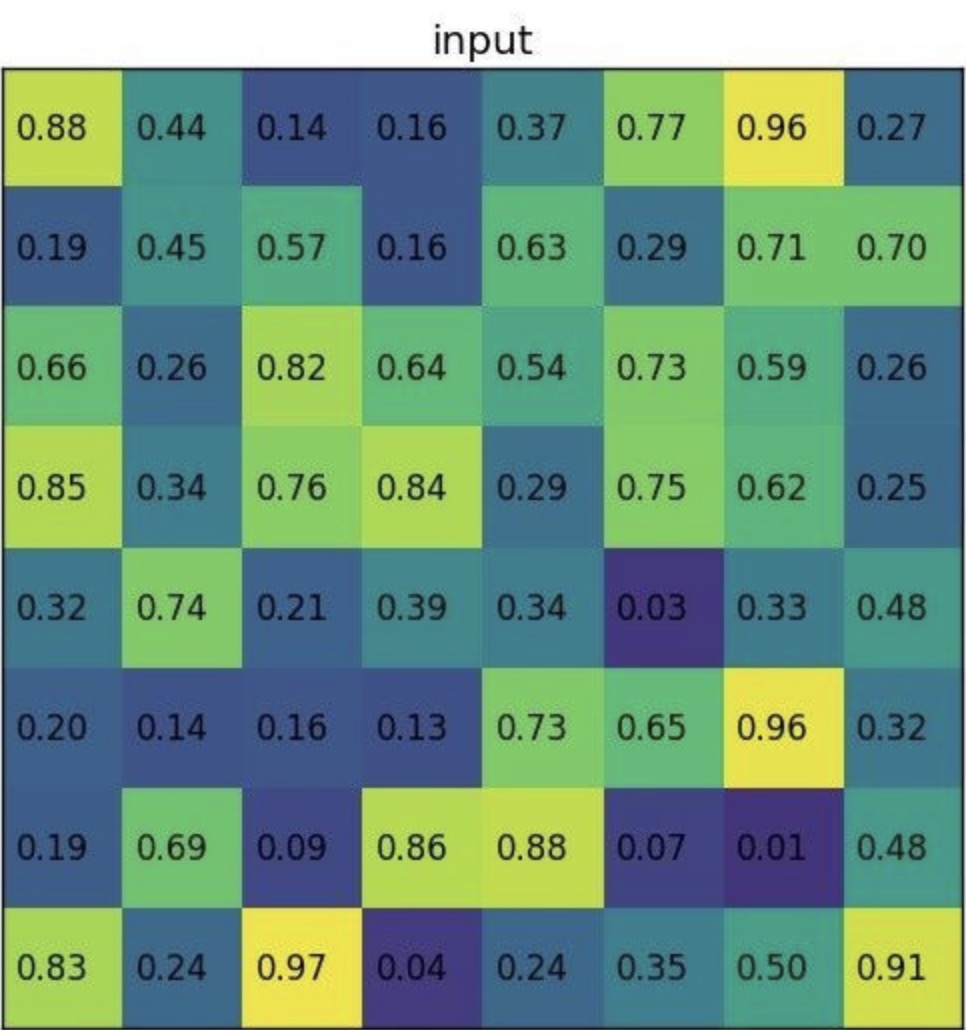
ROI 映射到feature maps,对应区域为:
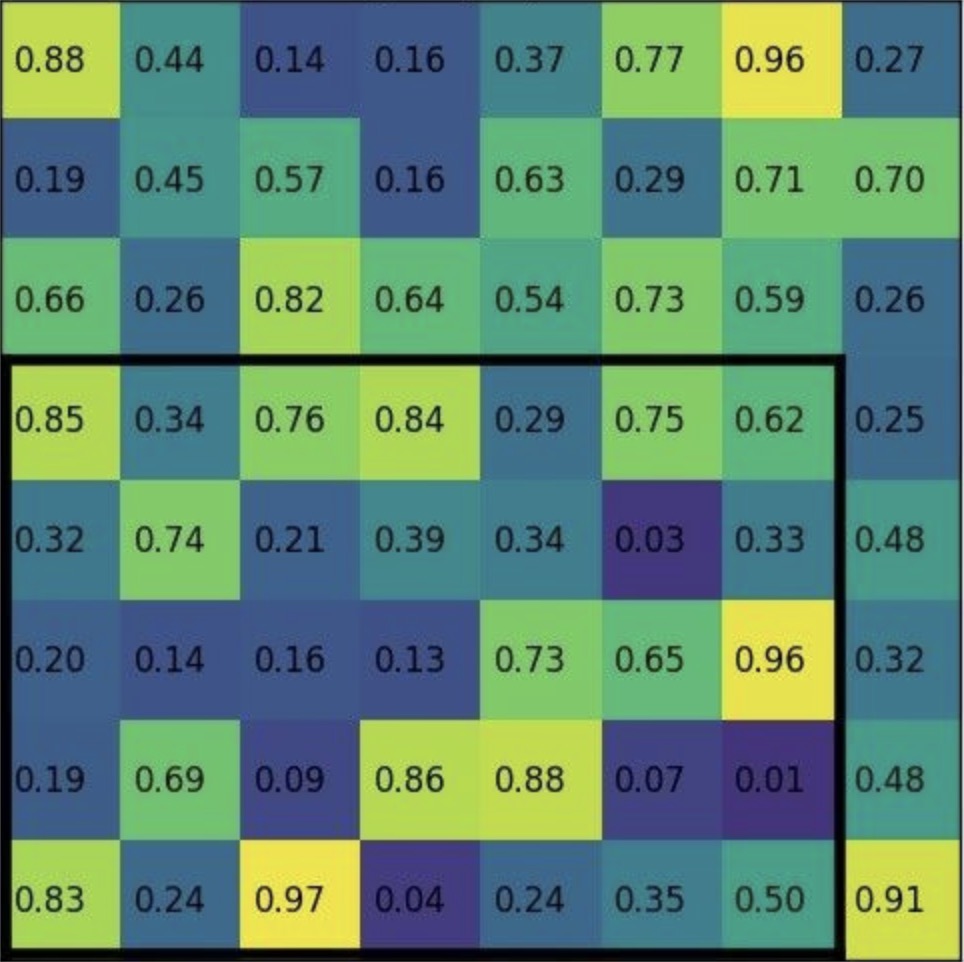
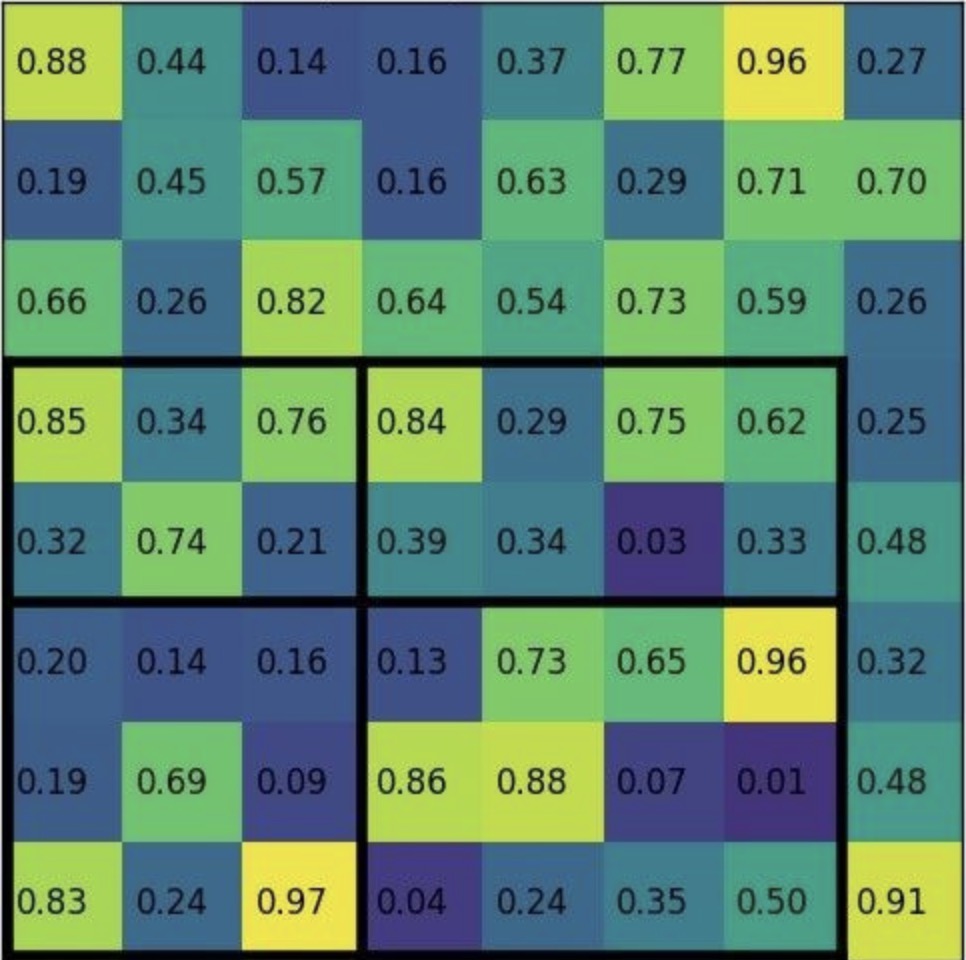
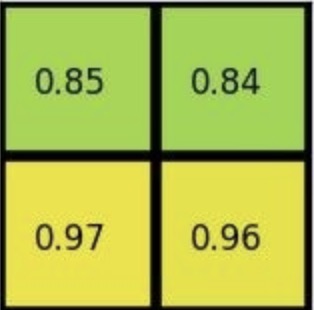
论文中的划分方式为每个grid的大小一样, 在上图中即为 2 X 3, 会丢弃第七列和最下行的特征, 导致带来像素偏差
Multi-task Loss
fast rcnn 将分类与边框回归整合到一个网络中, 除去 region proposal, 后续部分为端到端. 对于分类与回归使用多任务损失.
$$ L (p, u, t^u , v) = L _{cls} (p, u)+ \lambda[u >=1] L _{loc} (t^u, v)$$ $$L _{cls}(p,u) = -log p_u$$ $$L _{loc} (t^u ,v)= \sum _{i \in {x,y,w,h}} smooth _{L1} (t _i ^u -v_i)$$
$L _{cls}$ 为分类损失. $L _{loc}$ 为bounding box损失. $u$ 为gt 类别, $v$ 为gt bounding box. 背景类别序号为0, 对于定位损失, 不考虑背景, 故 $u>=1$.
存在的改进点
fast rcnn 将分类与回归结合到网络中, 不再训练使用svm 和训练线性回归器. region proposal 仍使用其它算法, 便引出了faster rcnn, 实现完全的端到端.
fast rcnn 存在两次量化, 导致存在像素偏差对边框回归带来误差. Mask rcnn 中的 ROI align 解决此问题.
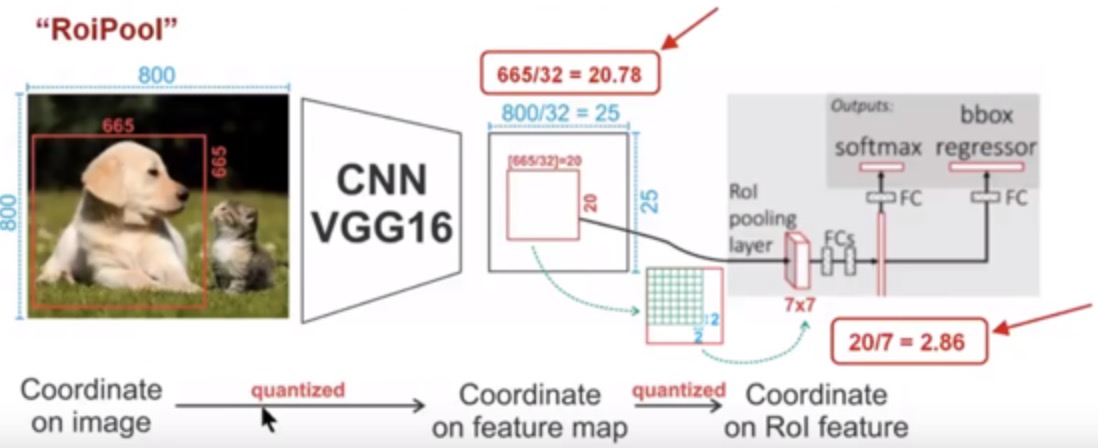
针对上图:
- region propsoal 大小为 665 X 665, 经过VGG16, 映射到特征图中大小为 665 / 32 = 20.78, 向下取整为20, 映射的特征图大小为 20 X 20, 此时为第一次量化, 此时特征图上一个像素对应于原图32个像素, 0.78 X 32 = 24.96, 偏差了接近25个像素
- 在VGG16网络下, ROI pooling 后固定成 7 X 7 特征图. 20 / 7 = 2.85, 向下取整为2, 故将20 X 20 特征图划分为49个 2 X 2 的小区域, 然后对每个小区域进行最大池化, 得到 7 X 7 的特征图. 此时为第二次量化, 当每个grid 2 X 2 时, 20 X 20 特征图上的部分特征没有被包含进去. 此时又导致了像素偏差.
