Yolo: v1-v3
目标检测主要有两种实现,一是faster-rcnn为代表的proposal two-stage 系列,二是以YOLO为代表的one-stage 的回归网络. 主要区别在于proposal系列的方法精度相对更高,但速度较慢. one-stage 的方法相对的速度快,精度总体来说低一些. 本文对yolo-v1到yolo-v3作个小结. 包含自己的理解与参考别人的理解
YOLO-v1
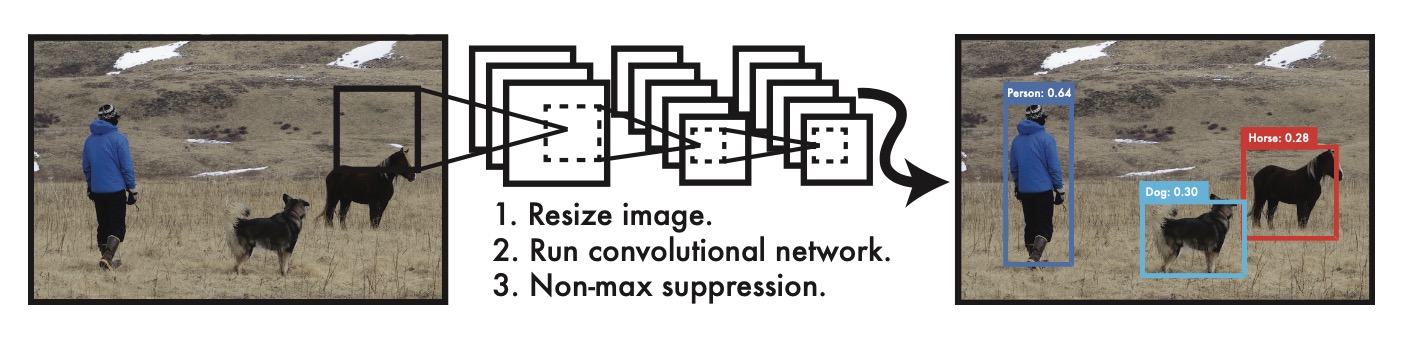
YOLO-v1算法流程如上图所示:输入图片,resize到固定 448 * 448, 经过卷积网络得到网络输出,最后进行非极大值抑制得到最终结果. 整个流程相对RCNN系列更简洁.
Unified Detection
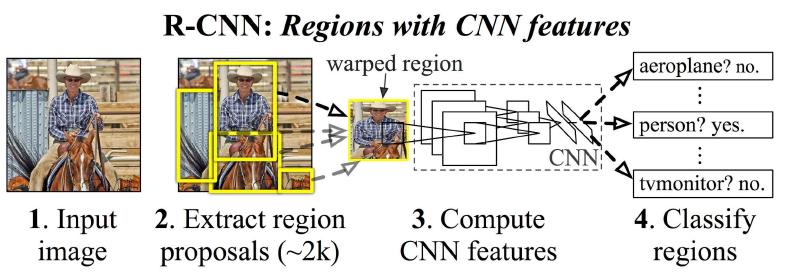
上图为RCNN的目标检测流程图,它将目标检测拆分为几个部分. 虽然最新的faster rcnn等已将全部由CNN 实现,但仍然不是一个统一的网络. 因此,检测速度较慢.
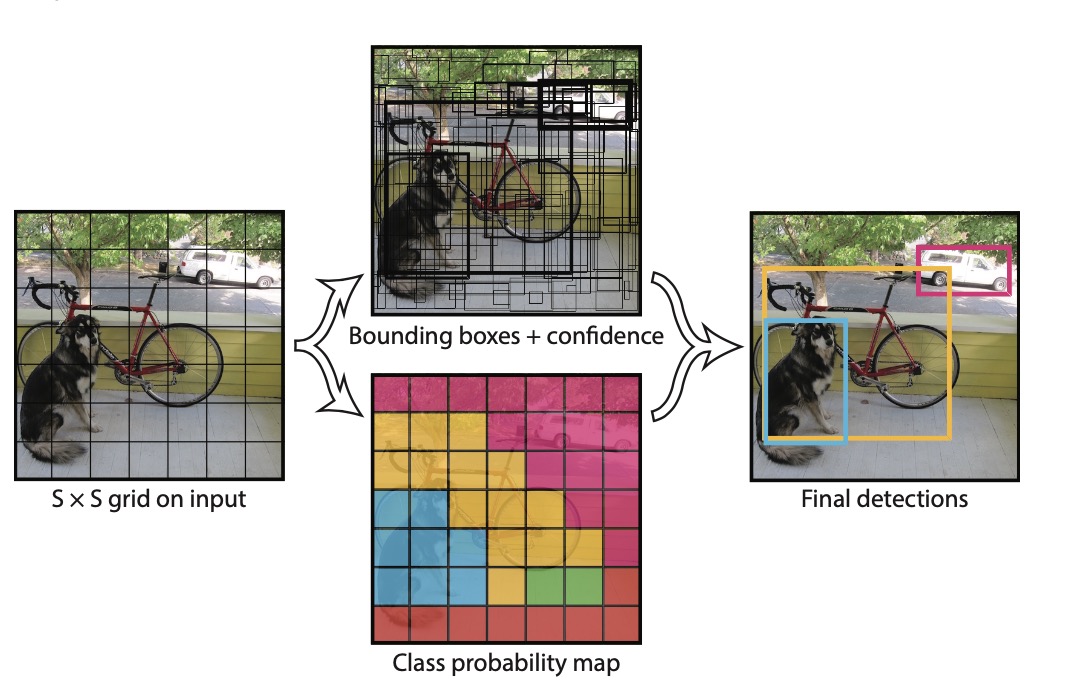
YOLO 将目标检测的各个部分统一为一个网络. 使用整张图像的特征来预测所有的bounding box. 它同时预测类别与bounding box. 如上图所示.
network
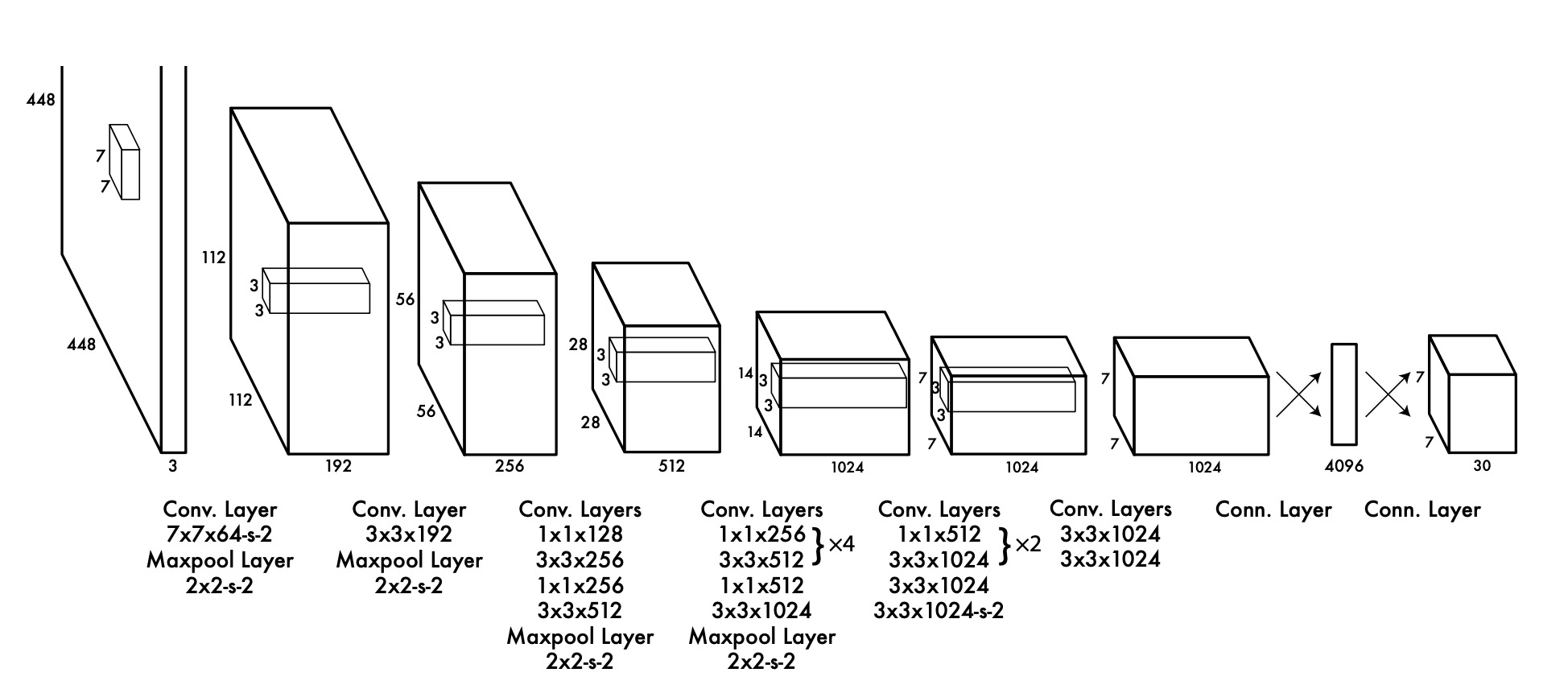
yolo-v1 网络结构如上图所示. 它包含了24个卷积层和两个全连接层. 1 * 1 卷积用来降维. 在PASCAL VOC detection dataset背景下,网络最后输出为 7 * 7 * 30 的向量.
流程
输入图像被划分为 $S * S$ 个网格. 如果一个物体的中心落在一个格子中,该网格负责检测此物体.

如上图,狗的 bounding-box 中心落在红色格子内,那么训练时只有红色格子负责检测狗(虽然狗的其它部分也落在了别的格子内,但它们都不会检测狗),自行车同理,只有绿色格子负责检测自行车.
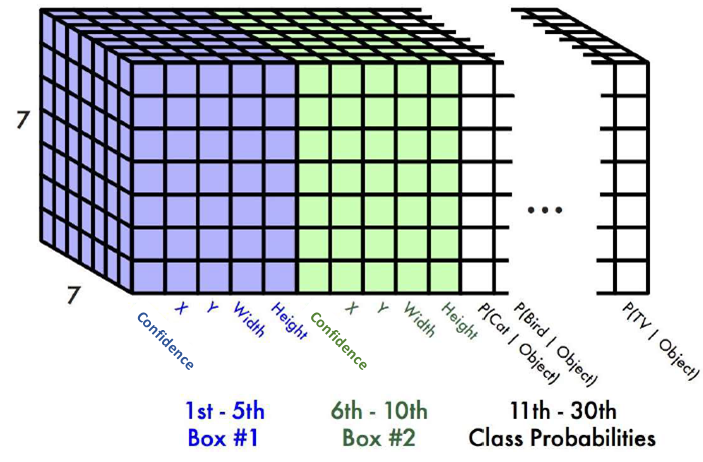
每一个格子都会预测 $B$ 个bounding-box (yolo-v1中 $B=2$) 以及 $C$ 个类别概率(voc 12 下 $C=20$). 每个 box 包含物体的可信度分数 $confidence$. 反应了模型认为此 box 是否包含 任意 物体的概率, 对应论文中的 $Pr(Object)$ .
其中, 每一个 bounding-box 预测5 个数据项: $x, y, w, h, confidence$.
- $x, y$ 坐标表示预测bounding-box的中心点. 实际训练过程中, $x, y$ 是 bounding-box 中心位置相对于当前 grid 的偏移量.
- $w, h$ 是bounding-box 的宽度和高度. 实际训练过程中, 除以图像高度或宽度以归一化.
- $confidence$ 代表预测的bounding-box与 gt 之间的 IOU. $confidence$ 为 $Pr(Object) * IOU _{pred} ^{truth}$. 当框内有物体时, $Pr(Object)$ 为 1, 否则为 0.
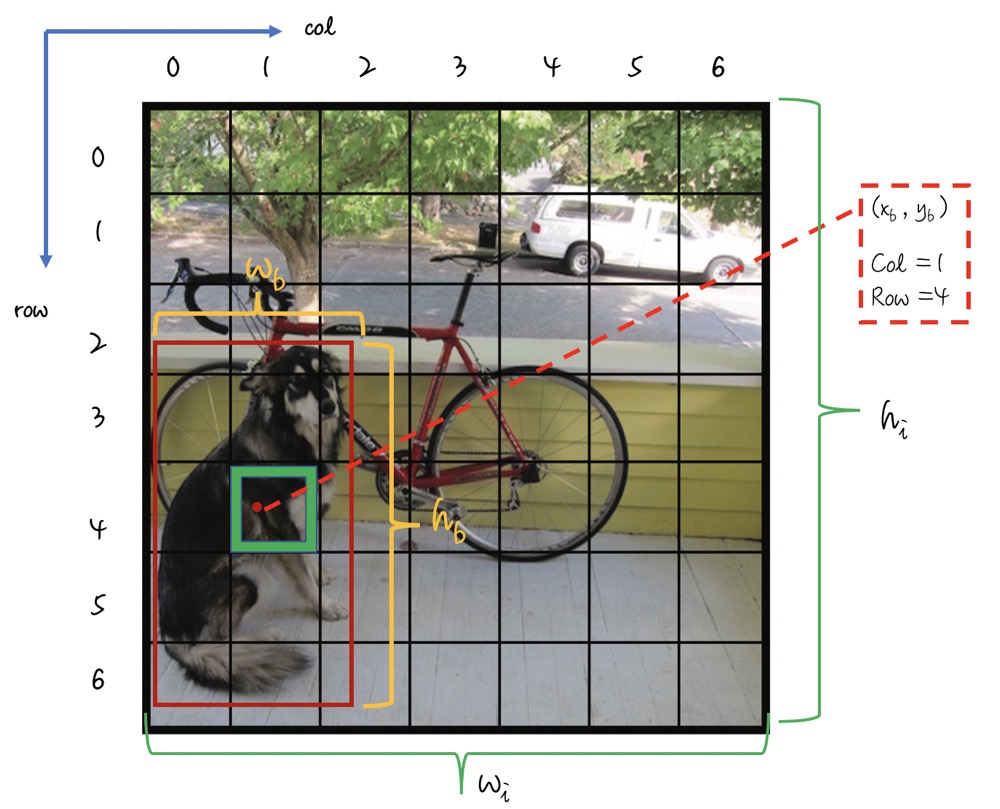
$x, y, w, h$ 归一化说明如上图. 记 bounding-box 在原图的中心坐标位置为 $x_b, y_b$, 图像高度、宽度分别为 $h_i, w_i$, bounding-box 的高度和宽度分别为 $h_b, w_b$. 将原图分为 $S * S$ 个grid, 编号为 (0 … 6). 如当前预测狗的grid 为 (row=4, col=1). 转换公式如下:
$$x = \frac{x_b} { w_i} * S - col$$ $$y = \frac{y_b }{ h_i} * S - row$$ $$w = \frac{w_b}{w_i}$$ $$h = \frac{h_b}{h_i}$$
因为网络的输出 $7 * 7 * 30$ 向量单通道仅仅只是7个点, 相对于grid 的偏移即相对于此点的偏移. 此点映射到原图即原图每个 grid cell 的左上角. (测试时,上式反推得到的是映射回 448 * 488 尺寸图像上的坐标, 需要根据实际比例进行修正.)
每一个 grid 预测 $C$ 类的条件概率, $Pr(Class_i | Objct)$ ,表示该单元格存在物体且属于某一类的概率. 测试时,对于每一个预测box: $$Pr(Class_i | Objct) * Pr(Object) * IOU _{pred} ^{truth} = Pr(Class_i) * IOU _{pred} ^{truth}$$
yolo-v1 输出如下图所示:
Loss Function

- $(x,y)$ : 预测bounding-box 的 $x, y$坐标被参数化为特定网格单元位置的偏移,因此它们也被限定在0和1之间。只有当存在目标时,计算平方误差和. $\lambda _{coord}$ 提升bounding-box损失.
- $(w, h)$: bounding-box的宽和高, 归一化到 0-1 . 只有存在目标时才计算.
- $C_i$ : 在每个图像中,许多 grid 不包含任何对象. 这会将这些单元格的 $confidence$ 推向零,通常会超过包含对象的 grid 的梯度,从而使模型不稳定. 引入 $\lambda _{noobj}$ 系数控制比例.
- $p_i ( c)$ : 类别概率. 平方误差和.
Other details
- Pascal voc下, 每张图片可以预测7 * 7 * 2 = 98 个bounding-box.
- yolo-v1 每个grid 只能预测两个box, 且属于同一类. 故对靠的近的不同类物体检测能力不足. 同时, 由于一个 grid cell 内的两个检测器都针对于同一个目标, 在训练时谁预测的结果与 GT 的IOU 最大谁就负责检测.
- 泛化能力较差. 倾向于检测长宽比类似于训练集长宽比的物体.
YOLO-v2
yolo-v2 在yolo-v1 的基础上作了改进, 在保持处理速度的基础上, 分别从预测精度(Better)、检测速度(Faster)和识别更多目标(Stronger)上进行了优化. 本文只挑重点介绍.
1: Batch Normalization
在所有的卷积层增加了BN, 去掉dropout.
2: High Resolution Classifier
由于历史原因, 大部分识别网络在 Imagenet 上预训练时使用的是 224 * 224 的图像. yolo-v1 也是在此基础上先训练识别, 再在 448 * 448 图像上训练检测网络. 分辨率的切换会带来性能的影响. 因此, yolo-v2 现在 224 * 224 图像上训练完分类模型后,再在 448 * 448 分辨率下对分类网络微调, 让网络适应更高的分辨率.
3: Convolutional With Anchor Boxes
在yolo-v1 中说过, yolo-v1 在输出 7 * 7 尺寸下只能检测 98 个 box, 其中每个 grid 的输出的两个box 还属于同一个类(共享一套类别概率). yolo-v2 引入了faster-rcnn 中的先验框(anchor box)机制.
yolo-v2 移除了全连接层. 输入resize 到 416 * 416 , 输出特征图大小为 13 * 13. 每个 grid 预测 $N$(5) 个 anchor box. 且每个box 独享一套类别概率. 如下图:

使用 anchor-box 时精度降低了, 但提升了召回率.
4: Dimension Clusters
在Faster rcnn和 SSD 中, anchor-box的长宽比是人工设计的. yolo-v2中, 作者使用 k-means 聚类生成 anchor-box, 得到的anchor-box 的长宽比更好.
5: Direct location prediction
Faster R-CNN 中anchor-box 回归公式如下: $$t_x = (x -x_a)/ w_a, t_x = (y -y_a)/ h_a,$$ $$t_w = log(w/w_a), t_h = log(h / h_a),$$ $$t _x ^* = (x^* -x_a)/ w_a, t _y ^* = (y^* -y_a)/ h_a$$ $$t _w ^* = log(w^* / w_a), t _w ^* = log(w^* / w_a)$$
$x, y, w, h$ 分别为 box 的中心坐标与宽高. $x, x_a, x^*$ 分别为预测的box, anchor-box 以及 ground-truth box. loss 计算为预测值与anchor-box的偏移与ground-truth与anchor-box偏移的差值.
上式计算宽高的缩放系数时,映射到了对数空间, 是为了避免带来不稳定的梯度. 不加变换时要求 $t_w, t_h$ 大于 0. 因为物体的高和宽不会是负数. 相当于带不等式约束. 取对数后将其不等式约束去掉.
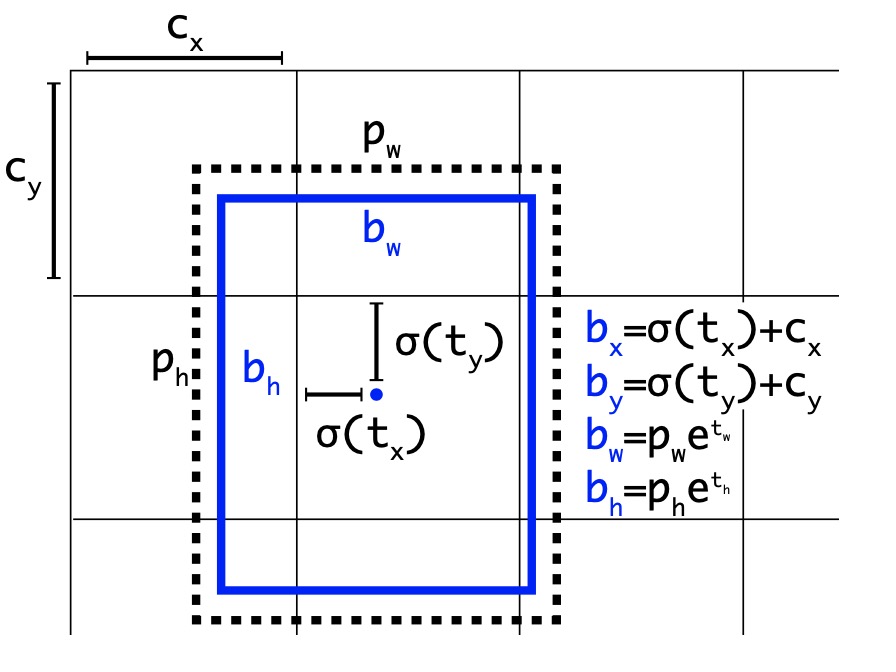
yolo作者直接预测anchor-box 的位置, 而不再是与ground-truth之间的差值. 如上图所示, 网络最后输出的为 $13 * 13$ 的特征图, 图中的每一个 grid cell 仅仅是一个像素点而已. 对应到上图中每个 grid cell 的索引是其左上角像素的索引. 每个 grid cell 的尺度为1. 上图中grid cell 索引为$[0:12] * [0:12]$ .
回归公式如下: $$b_x = \sigma(t_x) + c_x$$ $$b_y = \sigma(t_y) + c_y$$ $$b_w = p_w e ^{t_w} $$ $$b_h = p_h e ^{t_h}$$
$c_x, c_y$ 为当前grid cell的索引, $t_x, t_y$ 被约束到(0, 1)之间. 一是加快收敛, 其二保证中心约束在当前 grid cell内, 保证 box 中心落在哪个 grid cell 内,哪个负责检测.
YOLO-v2 每个 grid cell 设置了 5 个 anchor box, 在训练时 ground-truth 与哪一个 anchor box 的IOU 最大, 谁就负责检测该目标.
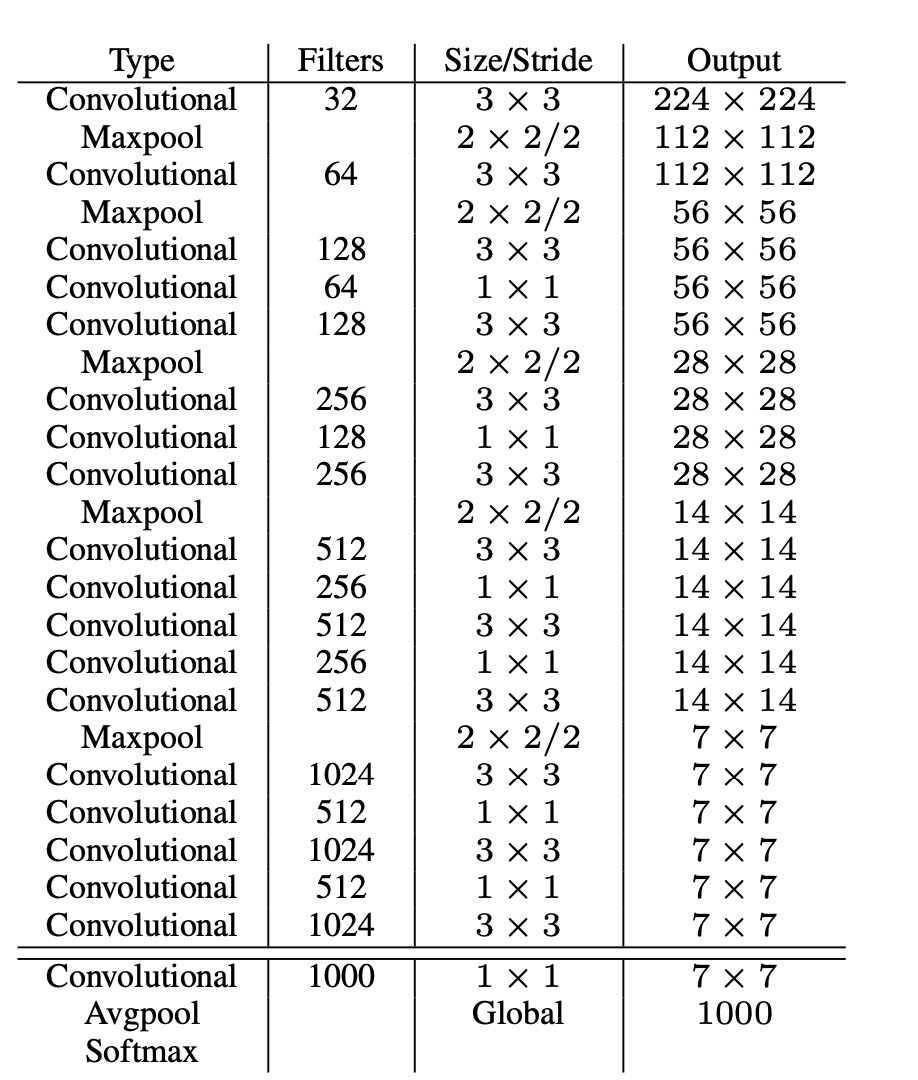
6: Darkent-19
提出了darknet, 网络结构如下:
YOLO-v3
YOLO-v3 主要在 yolo-v2 上增加了多尺度, 提升了对小目标的检测能力. yolo-v3 主要从以下几方面做了改进.
1: Bounding box prediction
yolo-v3 对每个bounding-box 使用逻辑斯特回归预测是否包含物体.将与gt IOU 最大的先验框此项设为1. 如果先验框和 gt 的IOU 不是最佳的但是超过一定的阈值(文中设为0.5)则忽略此预测. 即不计入 loss. 对每一个 gt 只分配一个先验框, 如果一个先验框没有被分配任何 GT, 那么不计算此框不计算坐标预测和分类损失, 只计算 objectness 的损失.
2: Class Prediction
对于分类, 作者改用了逻辑斯特回归, 不再使用 softmax. 一是 softmax 对于获得好的性能并不是必要的, 其二: 对于有些数据集, 各个 label 并不是互斥的(比如 woman 和 Person).
3: Predictions Across Scales
为了提升小目标的召回, 作者采用了类似特征金字塔网络的思想, 在三个尺度下分别进行预测.
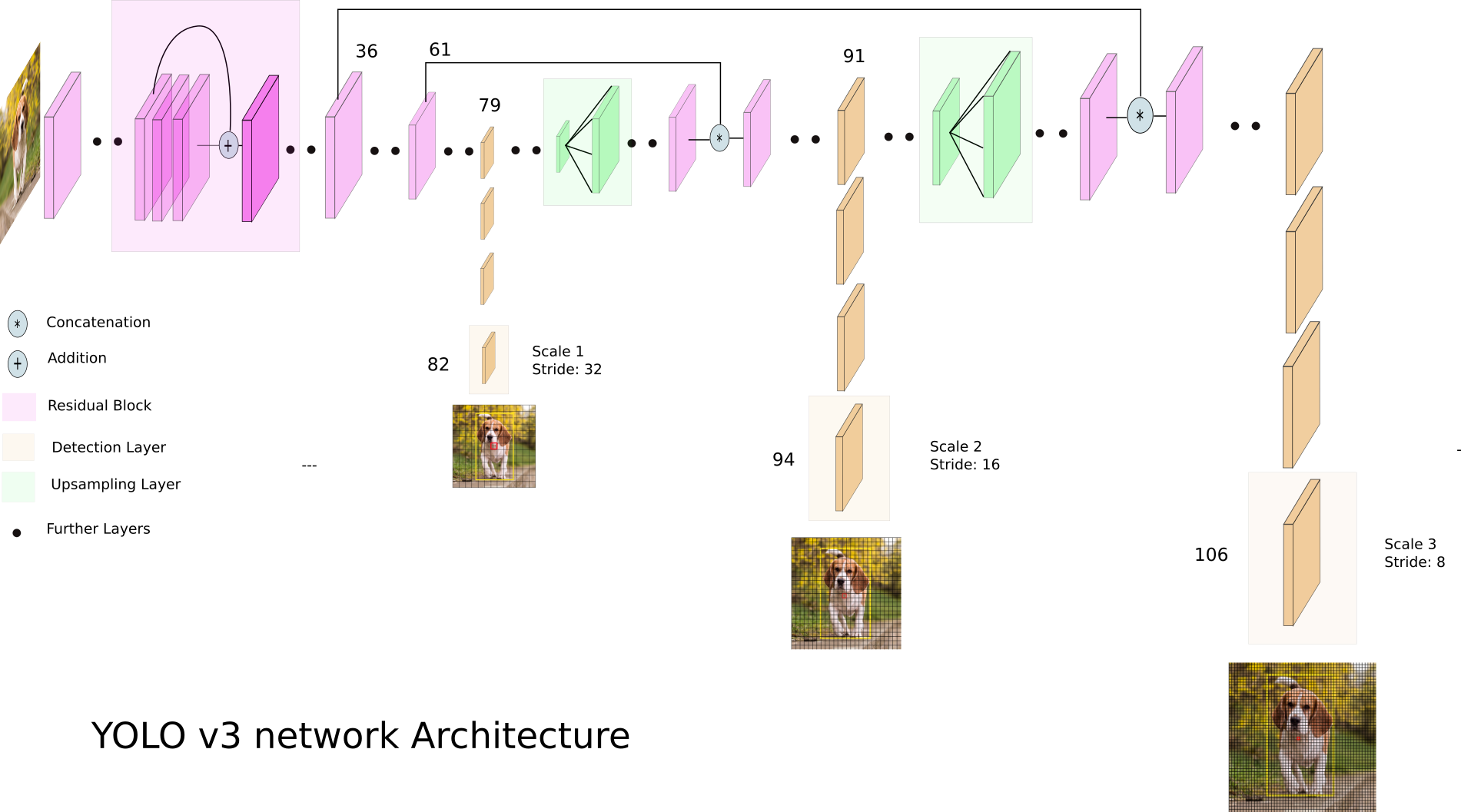
yolo-v3 分别通过将输入图像的尺寸分别下采样32、16和8 倍, 输出各个尺度的检测结果. 每个尺度下分别分配三个长宽比的 anchor box, 其最小尺度分配最大的三个anchor box, 以此类推.
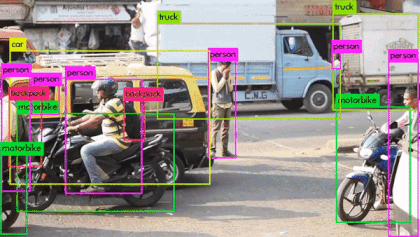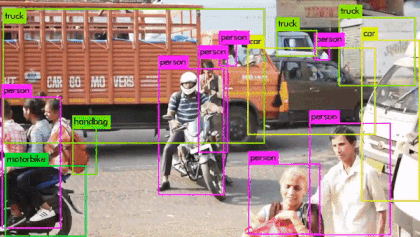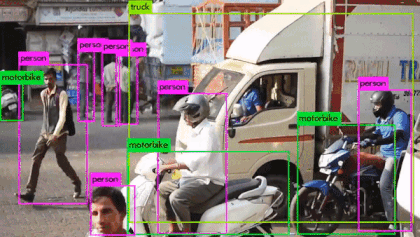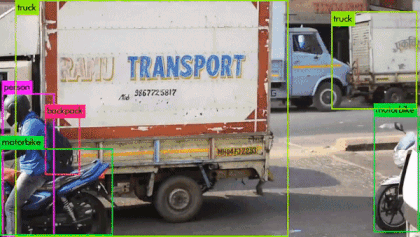
1: 第一次检测是由第82层进行的, 输出特征图大小为 13 x 13: 对应到原图, 如下图

此层输出 13 * 13 的特征图, 每个像素点对应到原图区域更大, 分配最大的anchor box, 主要检查大目标. 一共可输出 13 * 13 * 3 = 507 个bounding box.
2: 第二次检测由第94层进行, 输出特征图大小为 26* 26. 负责检测中等大小的目标, 一共可输出 26 * 26 * 3 = 2028 个 box. 如下图:

3: 第三次检测由第 106 层进行, 输出特征图为 52 * 52. 主要负责检测小目标, 因此分配最小的anchor-box. 一共可输出 52 * 52 * 3 = 8112 个box.

yolo-v3 在三个尺度下共输出bounding box 10647个, 预测的 box 数量超过 yolo v2的10X, 当然速度会慢一些.
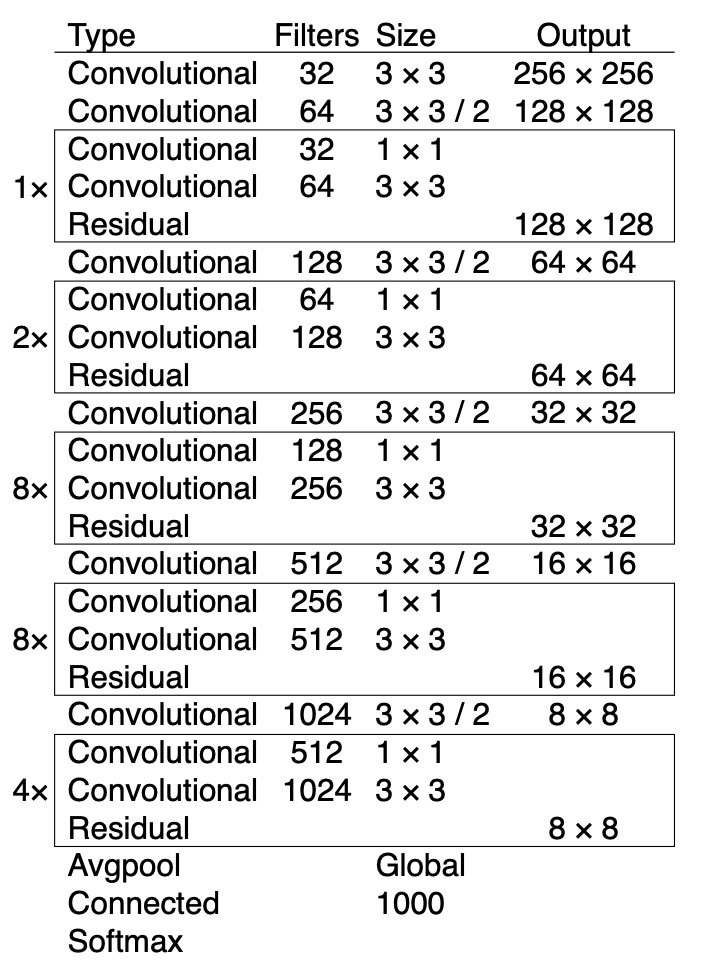
4: Darknet 53
yolo-v2 使用的是darknet-19, v3中提出了 darknet-53 作为特征提取网络. 结构如下:
5: yolo-v3 网络图