
Swin Transformer:层次化视觉Transformer 笔记
cver 不读swin transformer,遍读transformer也枉然. 个人读完论文感觉最大贡献在于: 将多尺度引入到了transformer, 可以像CNN网络那样输出不同分辨率的特征图,作为分类或检测等的backbone,可以自由结合上FPN,PAN等, 但是说什么降维打击,有点吹嘘过头了感觉
主要创新点
- 引入层次化的思想到transformer 中, transformer 实现输出多分辨率的特征图
- 将全体的patch attention 改为 局部的基于window的attention
结构总览
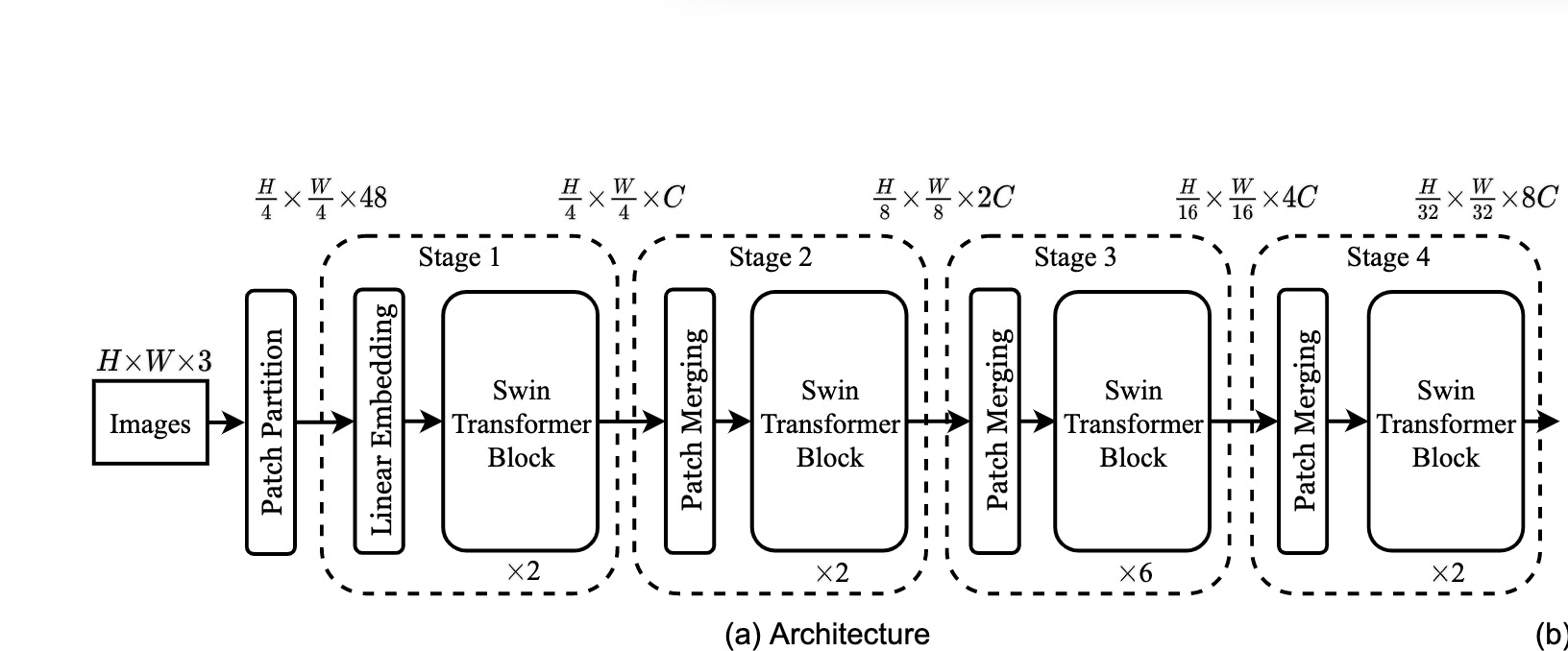
整个Swin Transformer架构,和CNN架构非常相似,构建了4个stage,每个stage中都是类似的重复单元。
- 首先,通过patch partition将输入图片HxWx3划分为不重合的patch集合,其中每个patch尺寸为4x4,那么每个patch的特征维度为4x4x3=48,patch块的数量为H/4 x W/4;
- stage1部分,先通过一个linear embedding将输划分后的patch特征维度变成C,然后送入Swin Transformer Block;
- stage2-stage4操作相同,先通过一个patch merging,将输入按照2x2的相邻patches合并,这样子patch块的数量就变成了H/8 x W/8,特征维度就变成了4C,然后使用linear embedding将4C压缩成2C,然后送入Swin Transformer Block
因此 swin transformer 的结构和经典的CNN网络backbone的结构一致,可以输出多个分辨率下的特征图。即可以作为目标检测、分割的backbone.
swin transfoemer block 结构
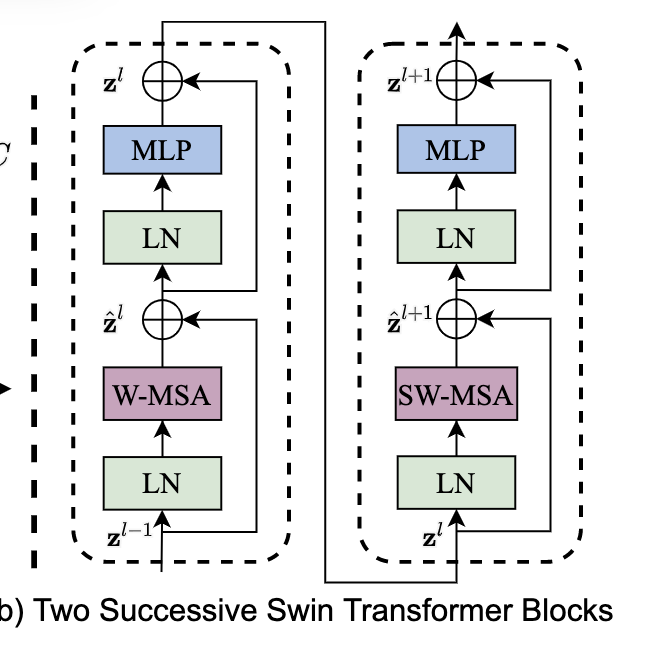
swin transformer block 的结构如上图所示,两个block 是连续的。将标准transformer中的多头自注意力模块替换成本文提出的基于窗口的自注意力模块(W-MSA)或偏移窗口的自注意力模块(SW-MSA),这俩模块的顺序是固定的.
基于self-attention 的shifted window
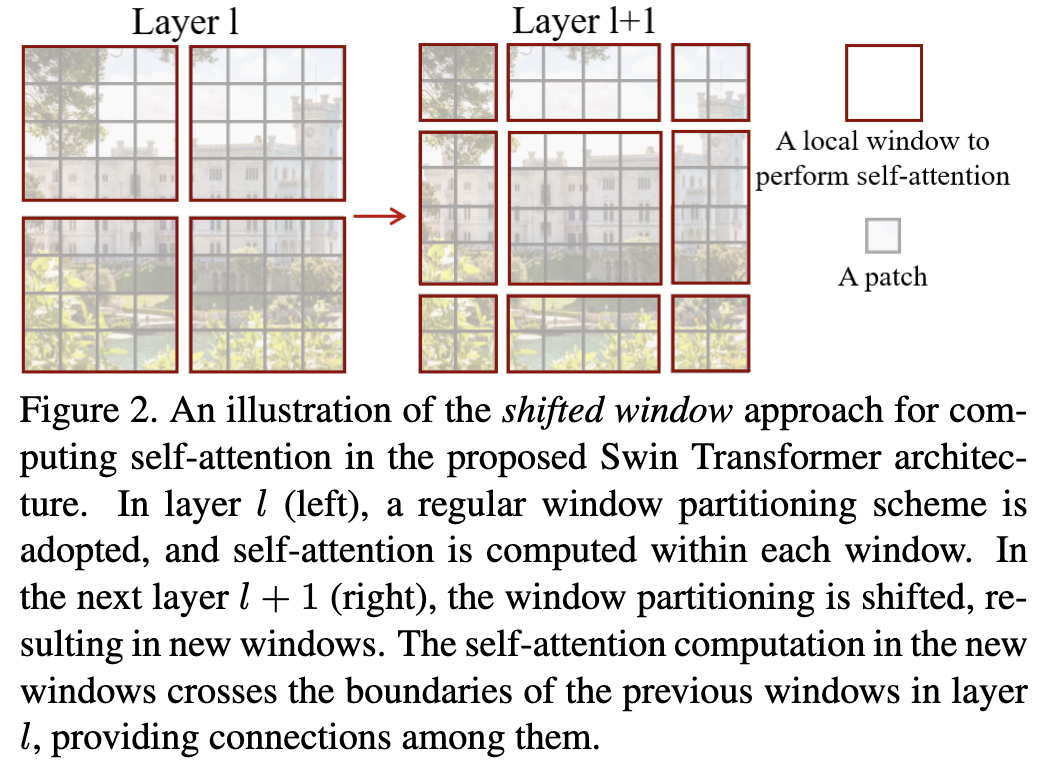
非重叠窗口的 self-attention
对于 ViT 而言,是将整个图片切分成固定数量 patch,然后在每一层的transformer 层所有的patch 都会其它patch计算全局的attention,计算量大. 尤其是分辨率高的情况下.
文中提出新的基于window的 self-attention 计算, 如上图中的左图所示,将图片划分成立4个window,其中每个window 又各自由 4 * 4 个patch组成,因此计算attention的时候只在各个 window 内计算各个patch 的self-attention.
这就有CNN的那种味道了:locality,同时由于在各个stage会不断 merge,相当于下采样,网络越深,window对应的感受野也会越来越大.
Shifted window partitioning in successive blocks
基于window的attention 让各个window之间缺失跨window的联系,使建模能力受限.因此文中提出了 shifted window. 上文中说过 swin-transformer block 是连续出现的,第一个采用 W-MSA,第二个采用 SW-MSA, 如图二所示,第一个是规则的window, 第二个是偏移的window,通过 shifted window 将上一层的不重叠的window建立了联系.
shifted window 批处理优化
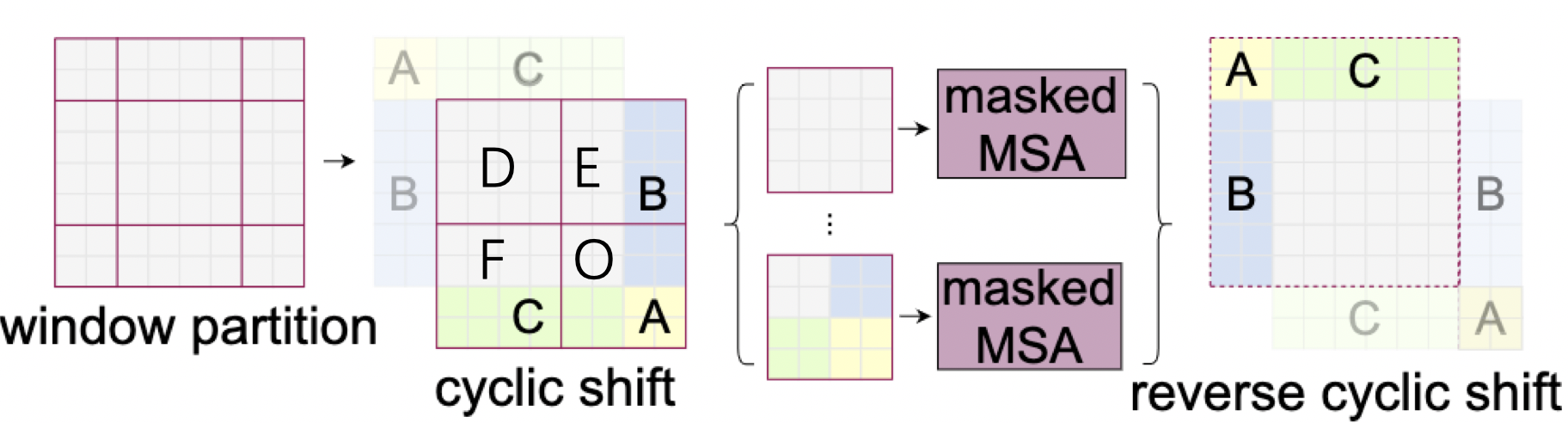
通过shifted window 操作后,各个window的大小不再统一,那么无法进行批处理并行训练. 因此,文中提出了一种偏移方式.
如图二所示,前一层的window 为 2 * 2,每个window 包含 4 * 4 的patch. 后一层进行 shifted window后,变成了3 * 3 的window,且只有最中间的window 包含 4 * 4 个patch,我们希望将所有window都变成包含 4 * 4 的patch. 统一大小. 如上图所示,window partion 经过 cyclic shift 后能得到一个 2 * 2 的window,且各个window均包含 4 * 4 的patch, 但是这样操作后本来不相邻的特征图被放进了同一个window,比如 F和C,E和B,因此需要生成mask,保证虽然它们在一个window内,将它们的attention值mask掉. 只计算各自各个patch的attention.
实验结果对比
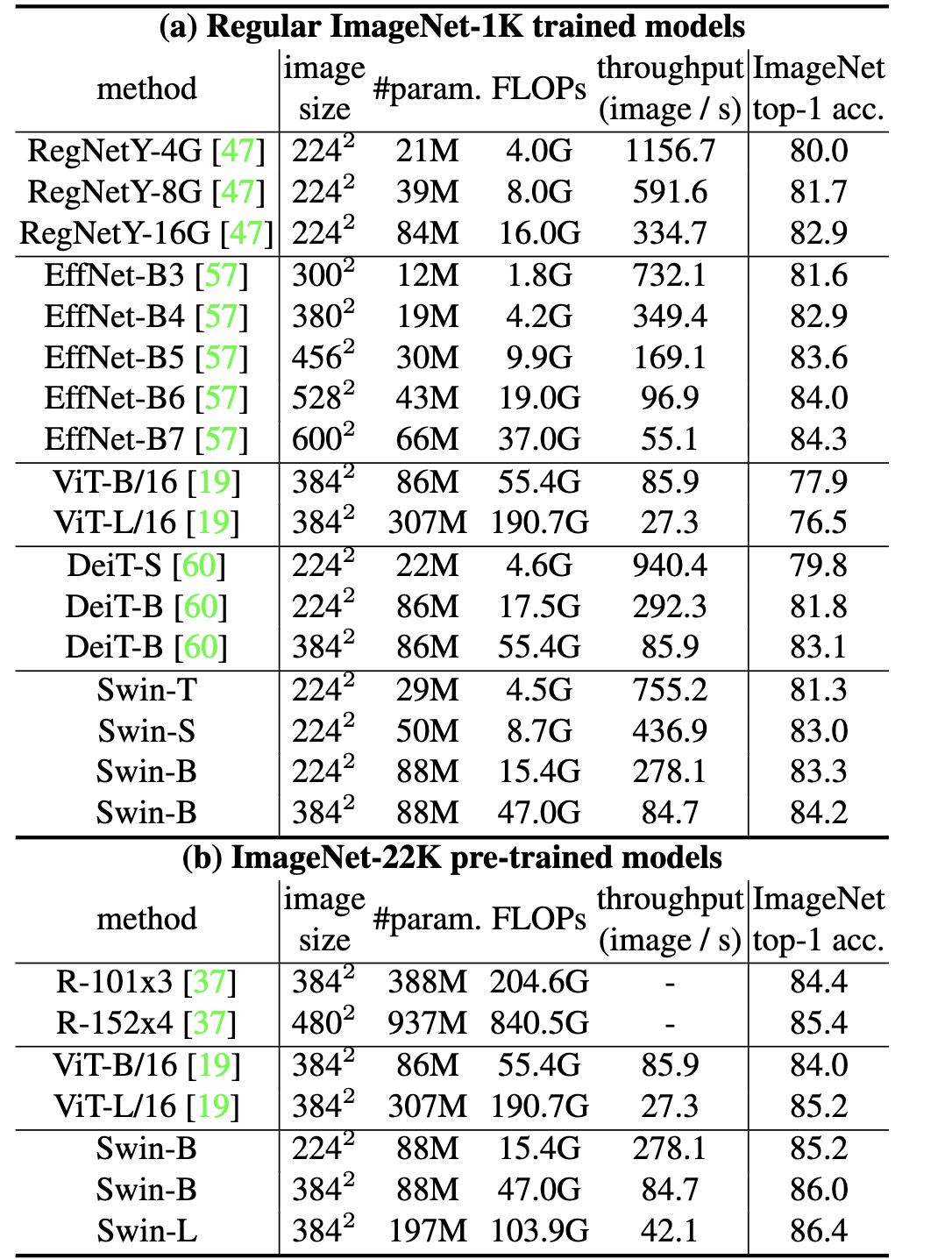
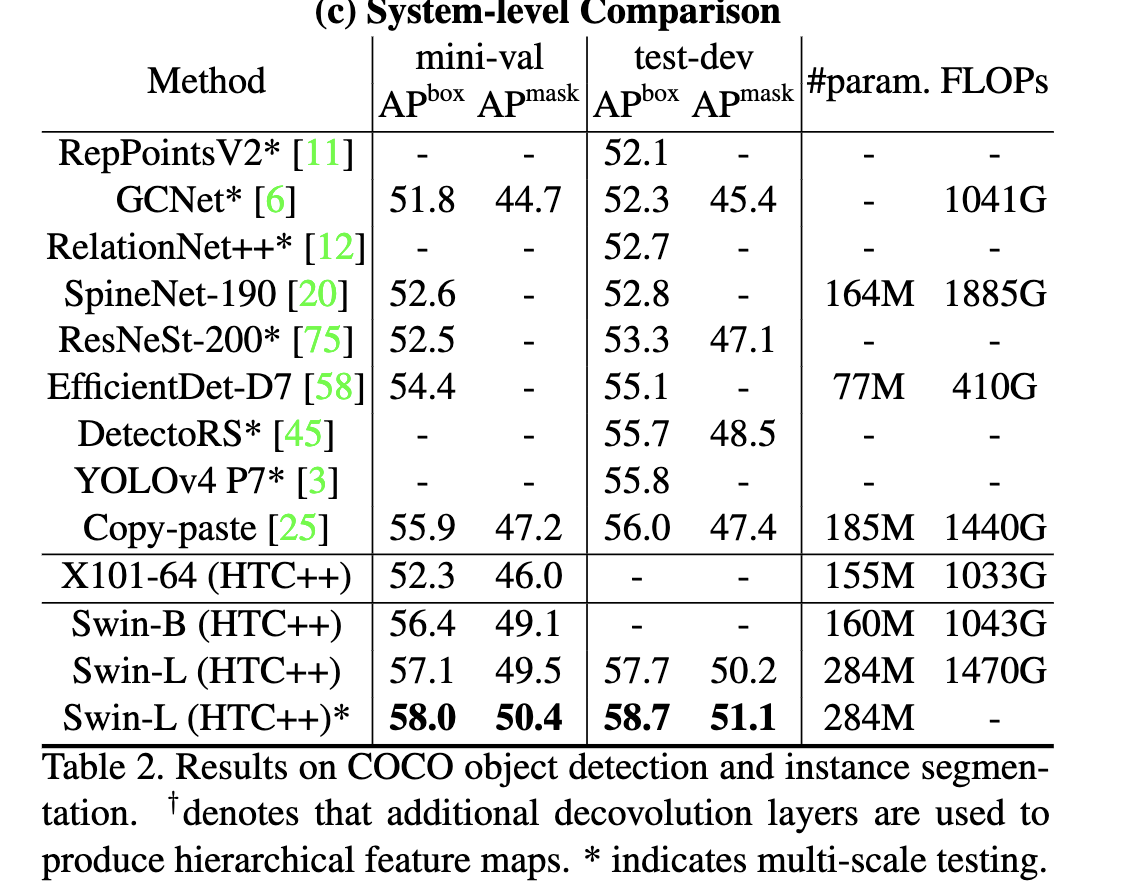
结果还是很可观的.
