
Anchor free 目标检测修炼之路: DenseBox : Unifying Landmark Localization with End to End Object Detection
DenseBox 是与yolo, faster rcnn同期的目标检测网络, 与yolo v1一样采用 anchor-free的思想, 网络结构采用FCN来实现目标检测
主要创新点
- 使用单个的全卷积网络实现目标检测, 在图片的所有位置直接预测目标bounding box 与类别
方法
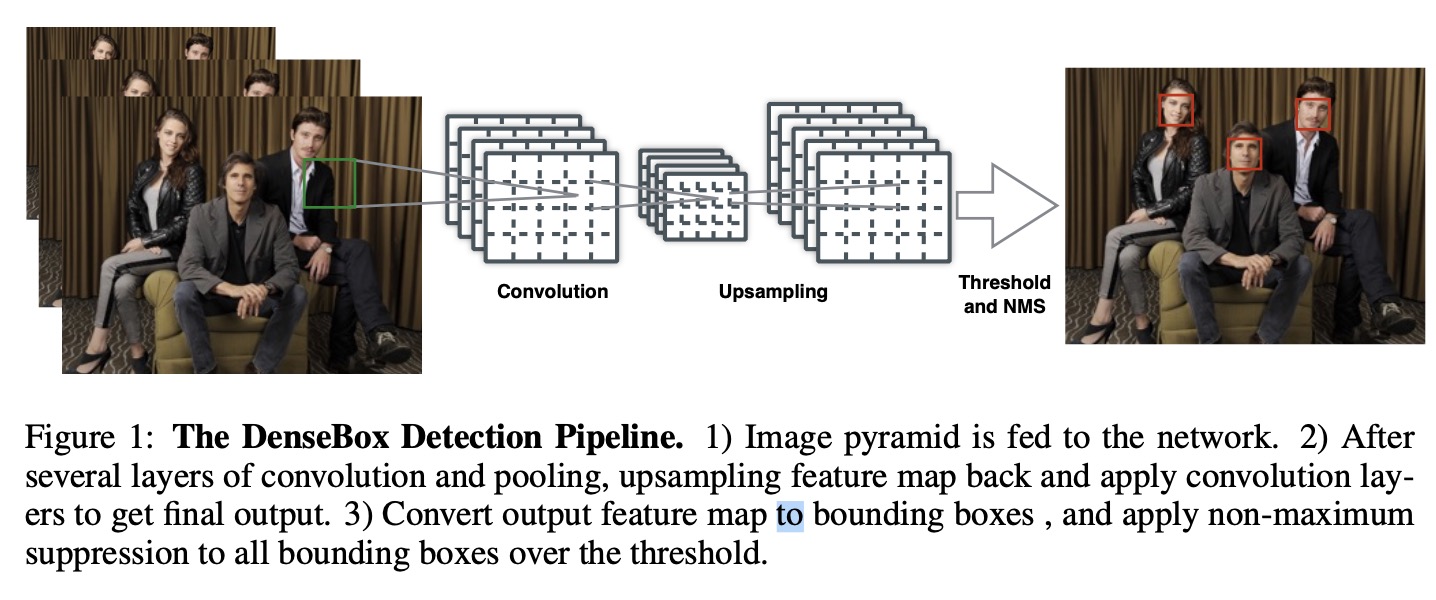
如上图所示, 主要流程为:
- 生成图像金字塔, 送入网络
- 经过卷积池化, 最后上采样加卷积层得到最终的输出
- 将最终的卷积层输出转换为bounding box, 应用 NMS 得到最终的输出
Ground Truth Generation


网络输出为5通道 60 * 60, 第一个通道是包含目标的置信度, 第一个通道ground truth map的正标签区域由半径为r的圆填充,圆的中心点位于bbox的中点, 半径r bounding box 大小成比例,缩放系数设置为 box 在输出空间大小 * 0.3. 另外四个通道分别表示输出特征图当前位置到最近邻bounding box 的左上和右下的距离.
如果一个裁剪块中出现多张人脸, 将相对于最中间的人脸比例在0.8 到1.25 之间的设置为正样本.
对于densebox, 由于输出每一个点都描述为一个bounding box, 最多可检测 60 * 60 个目标
model
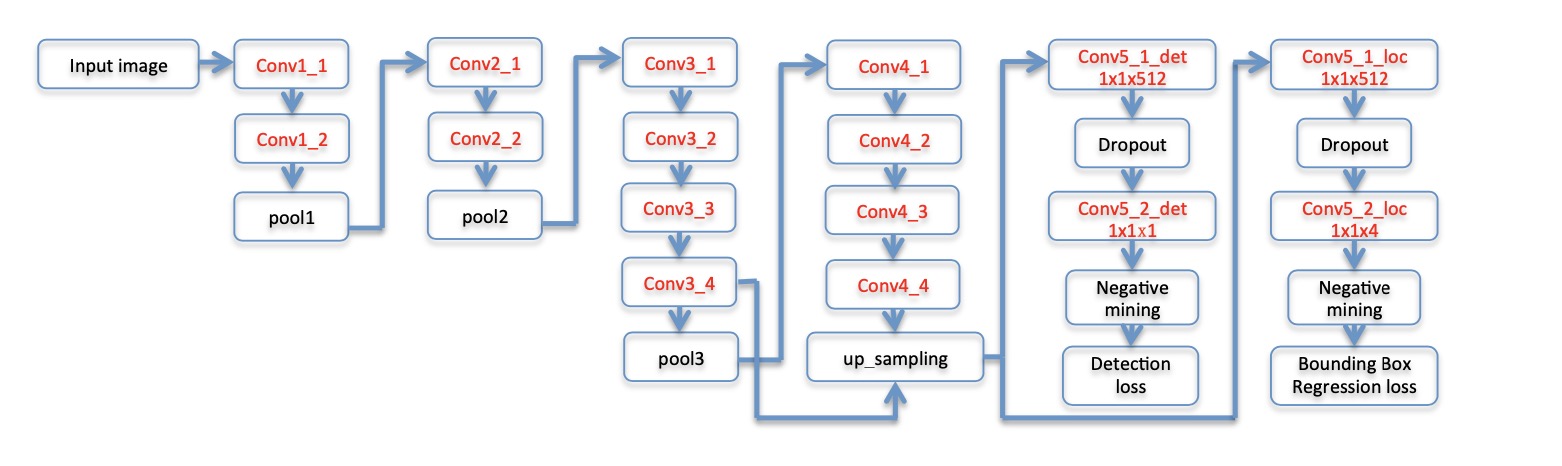
模型采用了VGG19, 以及特征混合.
loss
典型的多任务损失, 分类与回归分开计算
其它细节
- 在输出空间, 对于与正样本或负样本距离小于2像素的, 不计入损失
- hard negative mining, 根据损失排序取top 1% 作为hard negative, 训练时正负样本一比一, 负样本一半来自 hard negatvie sample, 另一半从非 negative sample随机选取
Refine with Landmark Localization.
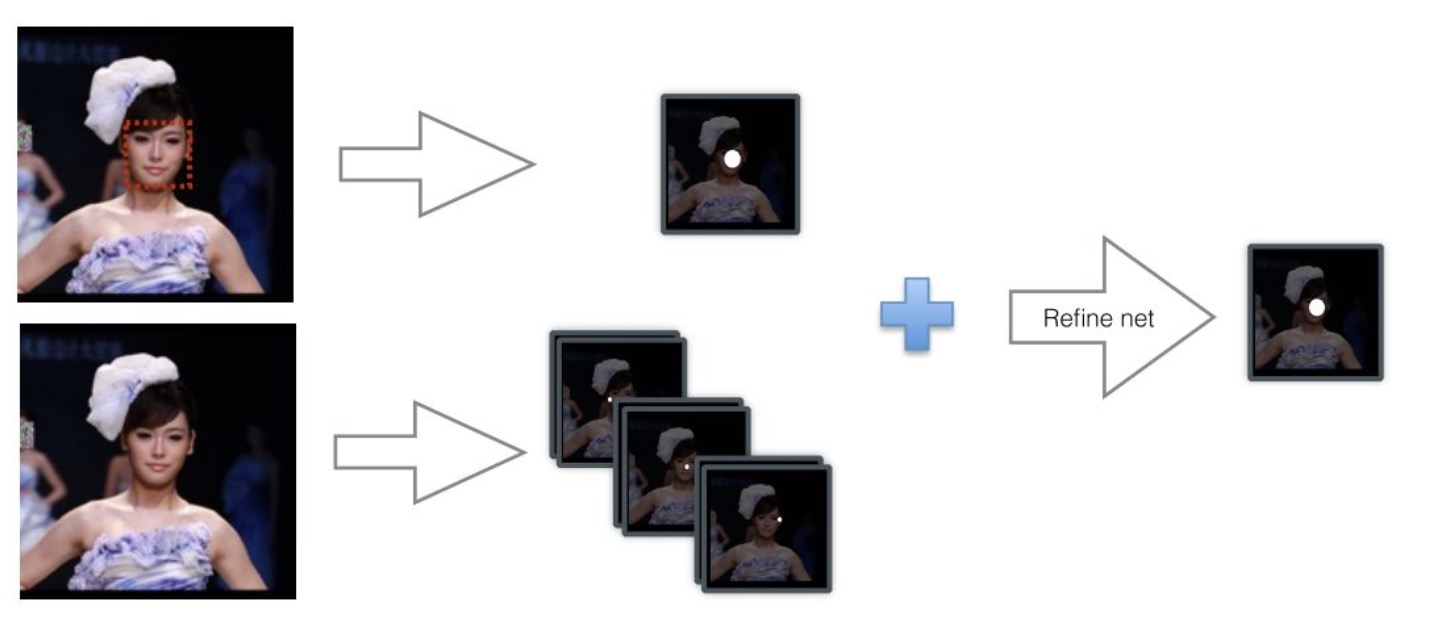
在FCN结构中添加少量层能够实现landmark localization,然后通过融合landmark heatmaps和score map可以进一步提升检测结果
