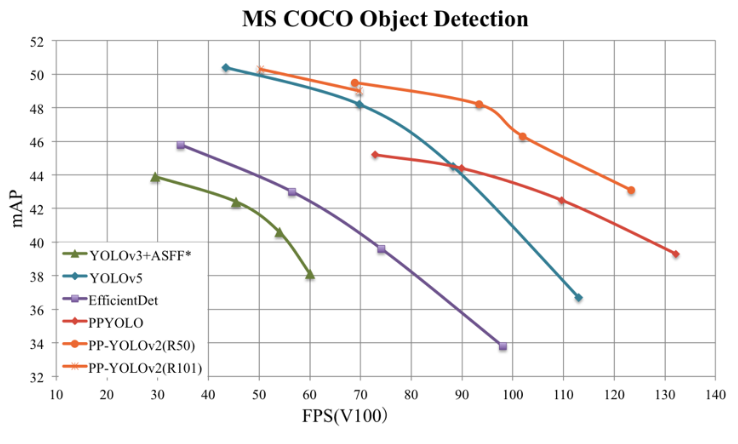
PP-YOLOv2 是百度对于ppyolo-v1 的升级版,主要是引入了各种插件来提升性能。如下图,ppyolov2 在相同的map下能达到更高的FPS. PPyolo-v2 的改进
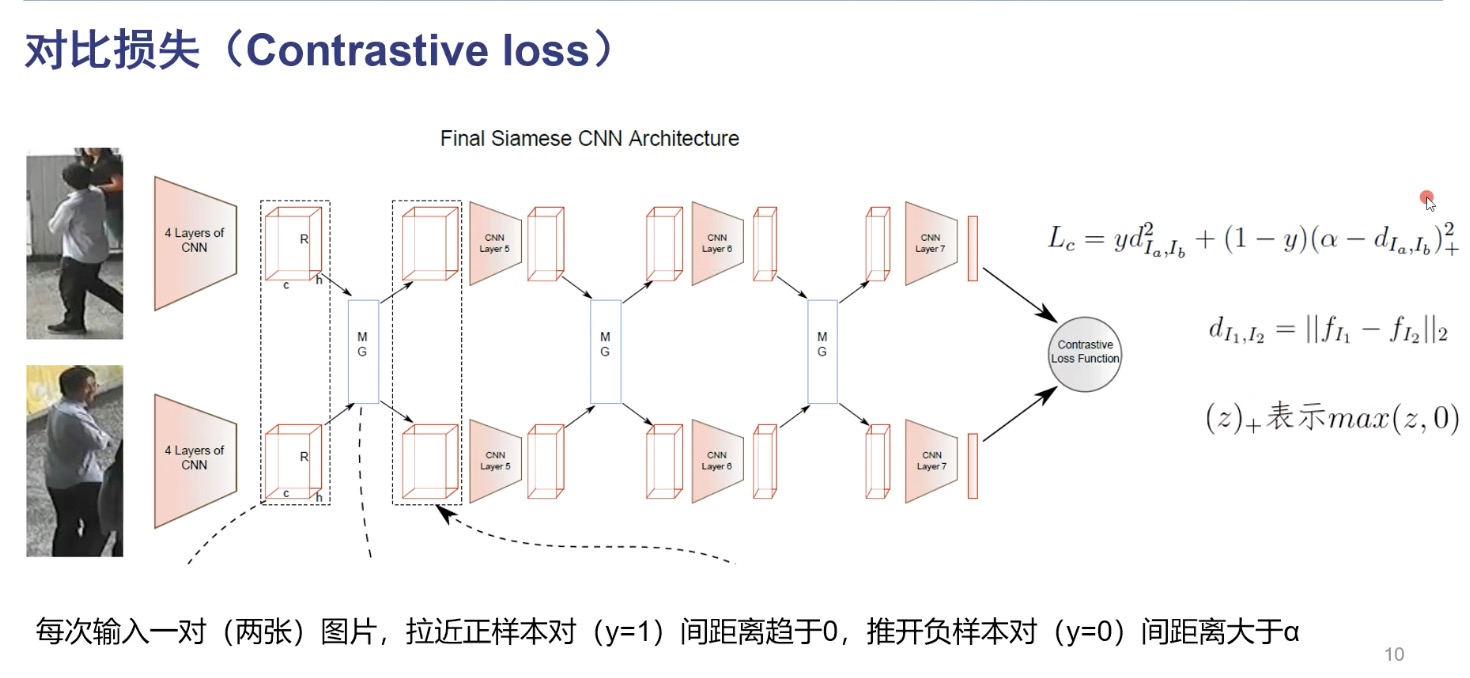
度量学习旨在学习两张图片的相似性,那么久需要设计合适的损失函数能让网络提取到更具有判别能力的特征. contrasitive loss 网络优化目标是最小化损失函数 $L _c$, 输入正
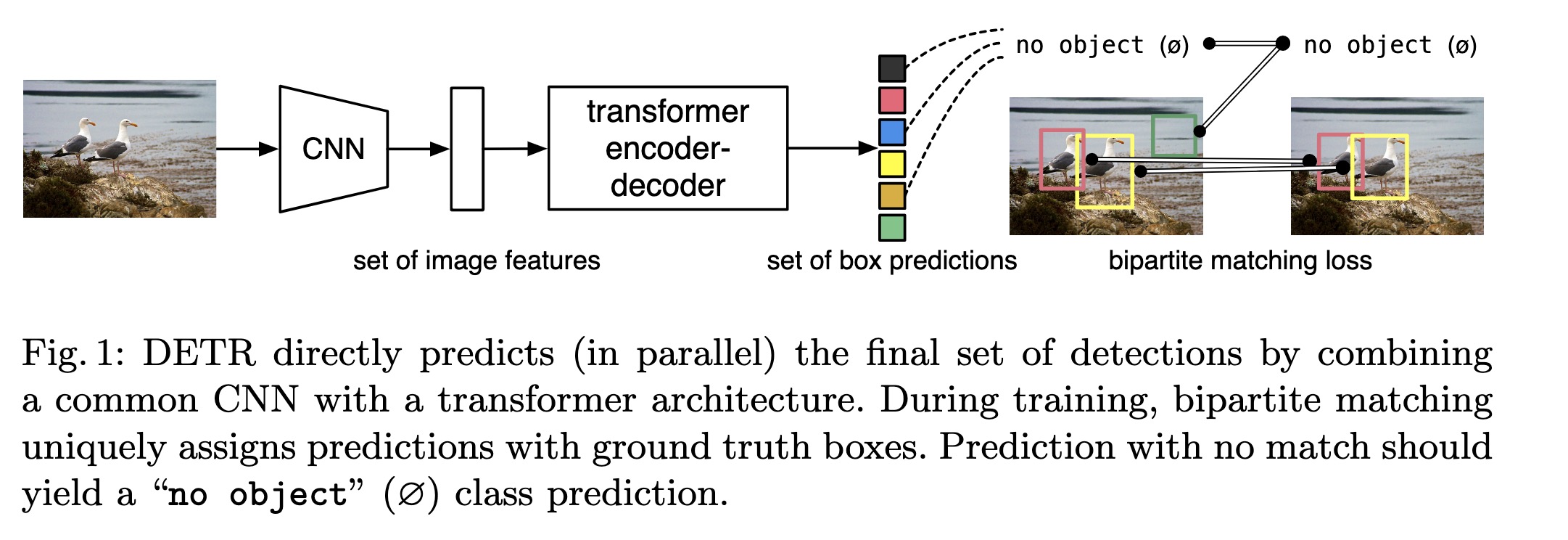
目前transformer在CV领域打的火热,前文记录了transformer用于图像分类的实现,本文主要记录transformer用于目标
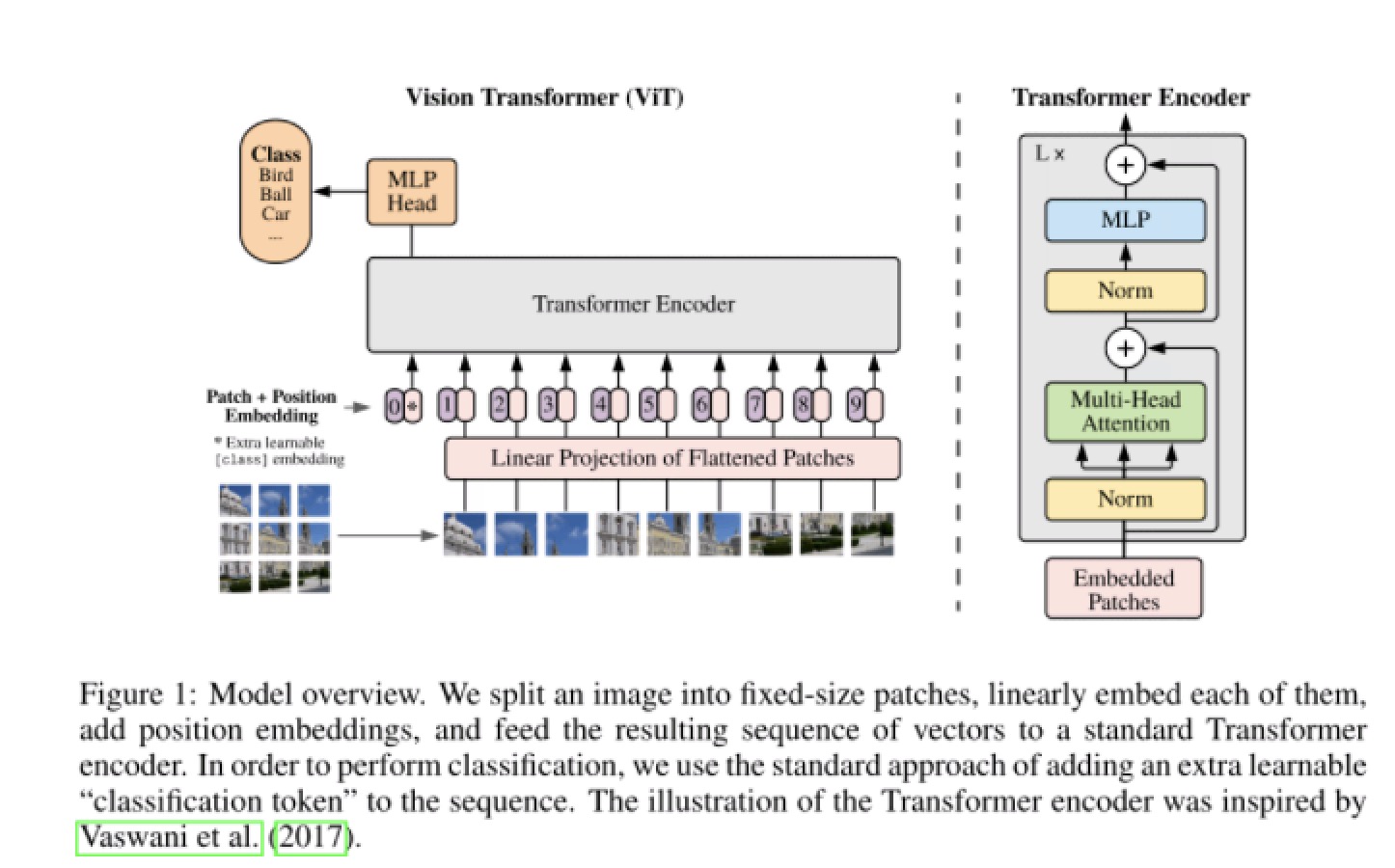
本文主要从代码角度记录使用transformer实现图像分类的流程. 代码vit-pytorch/ 总体结构 结合上图与代码展开: 前向传播过程代码
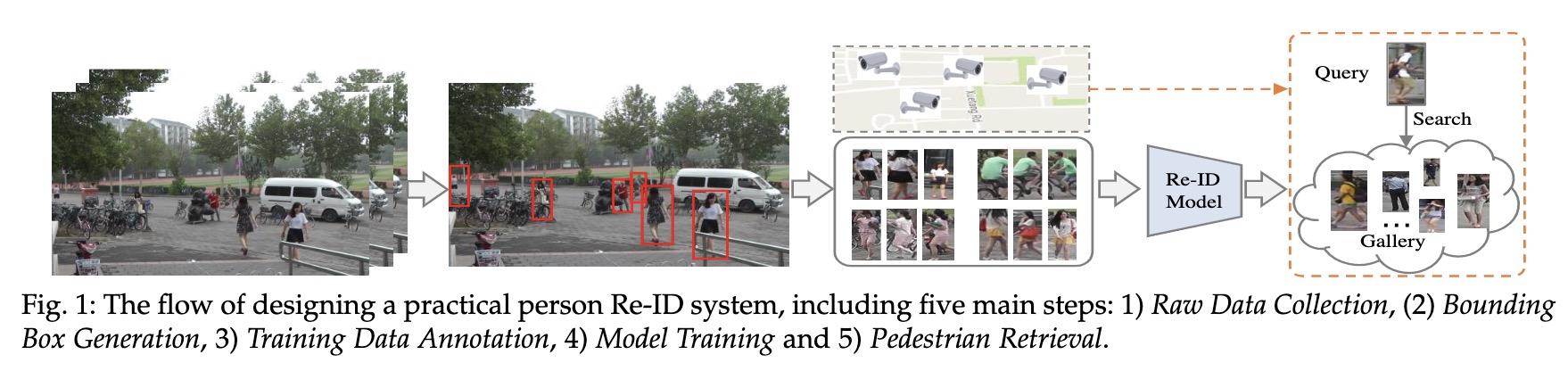
目前团队项目逐渐偏向识别,自己的工作重心逐渐由检测、分类转向reid相关,自己之前对reid也没有深入,因此准备记录自己在reid工作上的成
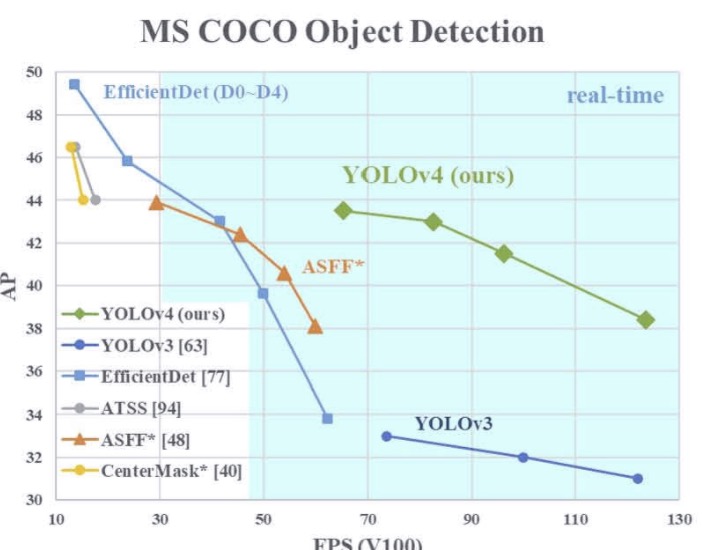
最近对yolov5进行了较为深入的理解,顺便将yolov4给啃一啃,之前只粗略读过论文,这边文章主要从代码进行学习,代码参照 pytorch版
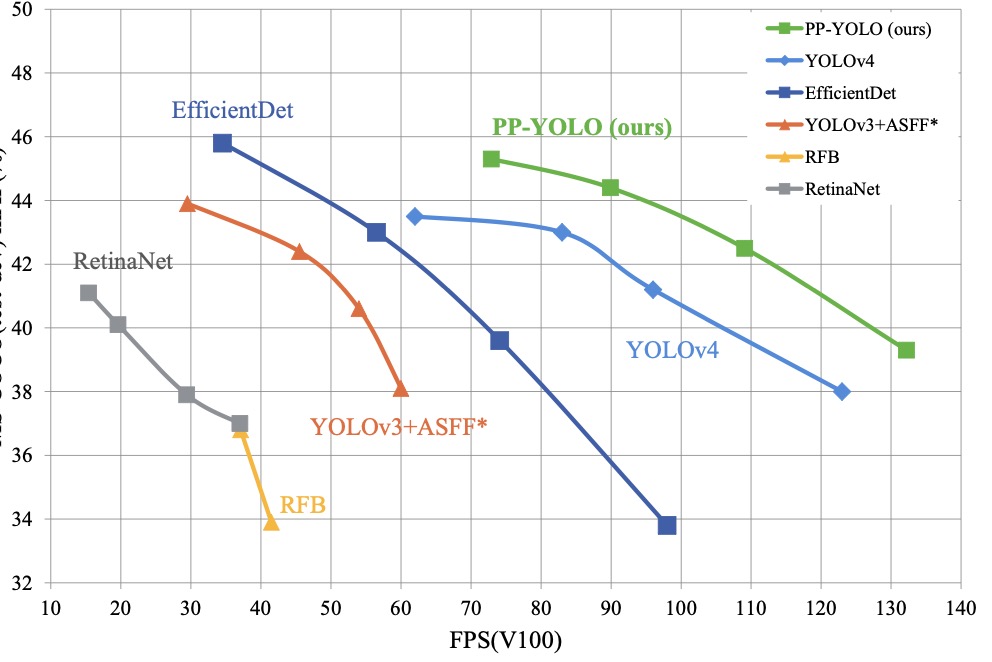
PP-YOLO 是百度在paddle-paddle框架下基于YOLOv3,结合各种trick得到的一个在性能与效率平衡的检测网络。与yolov4、effi
训练过很多目标检测网络,个人觉得yolov5是使用过的收敛最快的网络,训练10多个epoch就能达到很高的P、R. 收敛快的原因也不是网络本身

yolo-v5 非论文,仅工程实现。本文主要记录自己对yolo-v5代码的学习、理解,以及实际服务部署。 网络结构 yolo-v5 包含4种模型结构,分别是yolov5s、
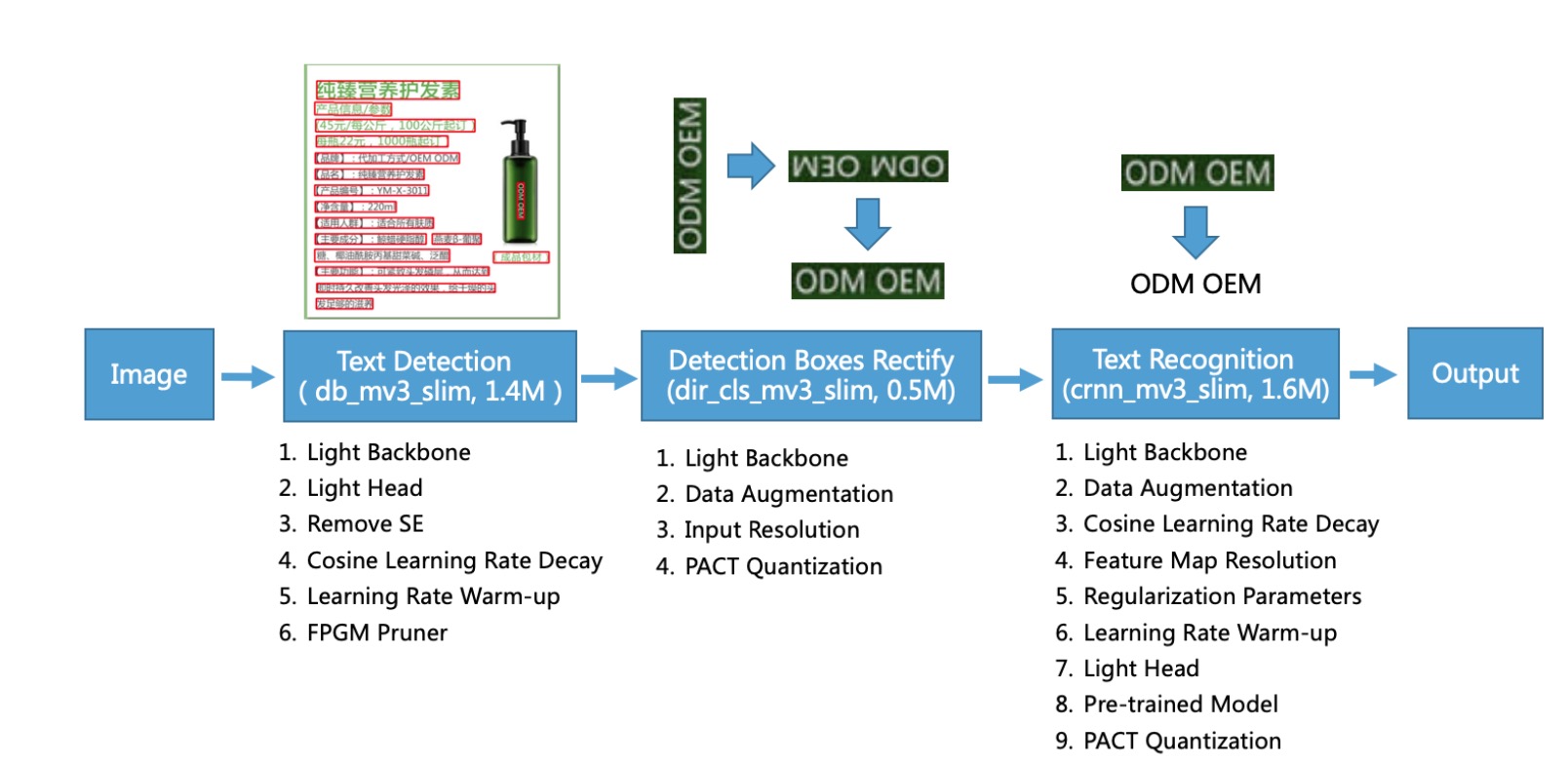
PP-OCR 是百度基于paddlePaddle 框架开源的国产高质量的OCR系统,PP-OCR 论文主要对其中使用的技术作了介绍。本文对PP-OCR 作阅读
