
yolov6 是美团开源的模型,主要是工业应用,官方说速度精度都比v5 和 x 高, 最近也用到了efficientRep 作为backbone, 记录一下 论文做了

对于常用的目标检测而言,测试集和训练集的类别时保持一致的,即我们想要检测什么,那么训练集就有该类别的数据. 对于zero-shot 即测试集的出

论文三连问 论文做了什么:使用分类数据集来训练检测模型的分类器,使检测器可以识别出上万的类别 论文怎么做的:对于检测标注格式的数据和分类标注格式
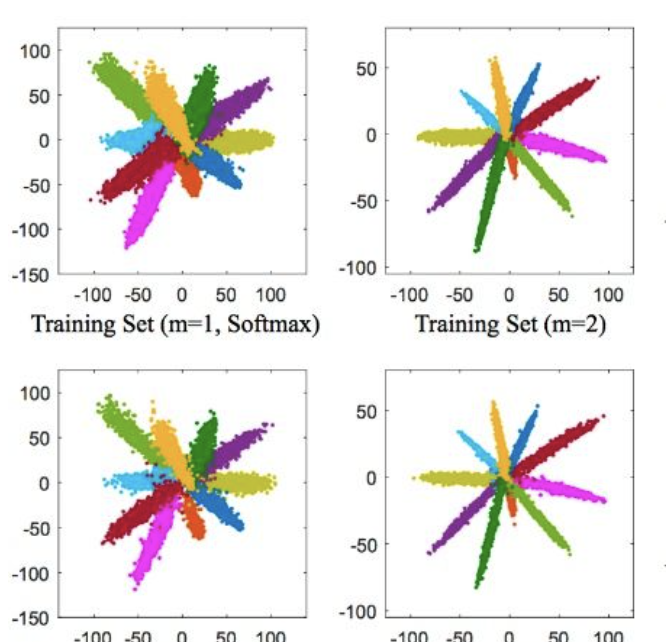
在之前的文章中记录了部分用于重识别的损失,主要是基于欧式距离的损失,本文接着对人脸识别使用的损失进一步做个小结. 首先,针对于识别任务,不论是
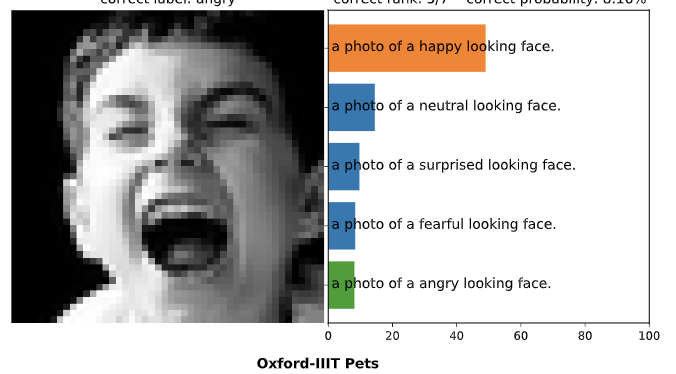
CLIP 是 openAI 提出的用以将图像映射到文本描述空间中,连接图片和文本,可以用来提取图像 embedding, 用作zero-shot 迁移。 CLIP 结构 CLIP 总体结构如上图: 通过对比学
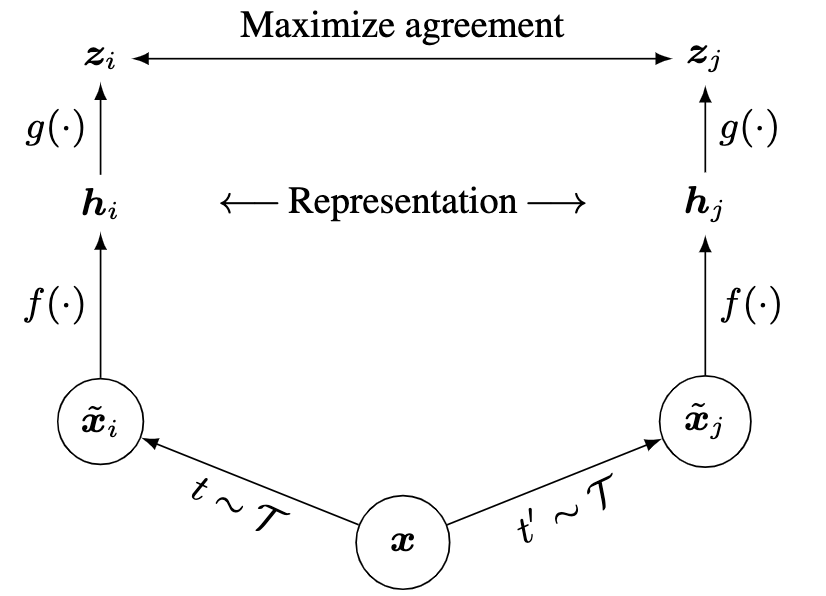
SimCLR 与 MOCO 都是采用自监督、对比学习的形式来训练视觉模型。因为对于主流的CNN网络,模型训练都依赖于人工标注,但是人工标注成本太大,我们能使用的标
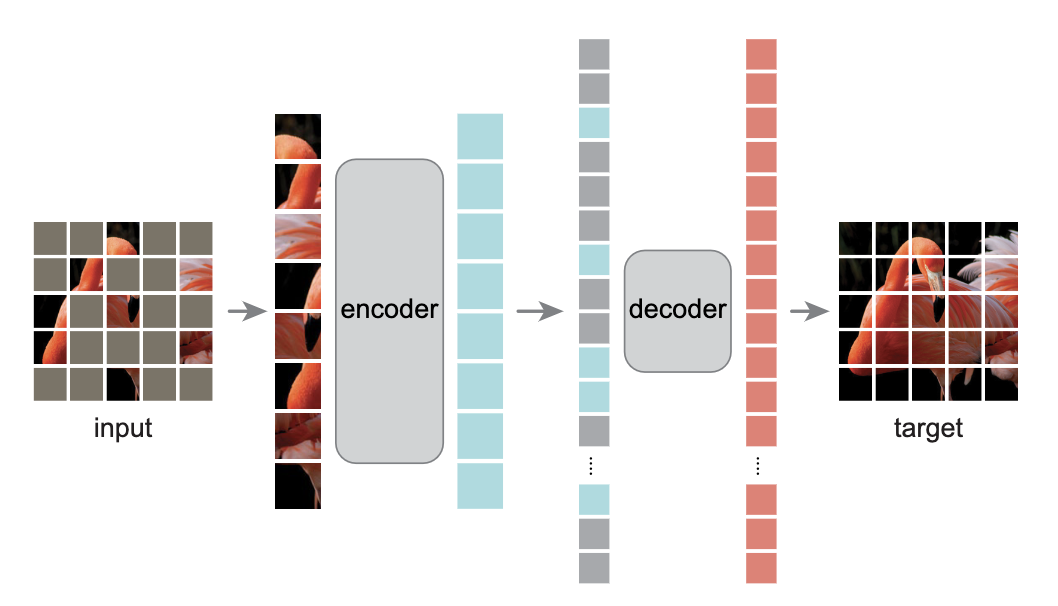
读前三问 论文做了什么:论文以自监督的形式来训练自动编码器用来提取特征,实现无标注的预训练 怎么做的:对输入图片进行mask,采用编码器-解码器
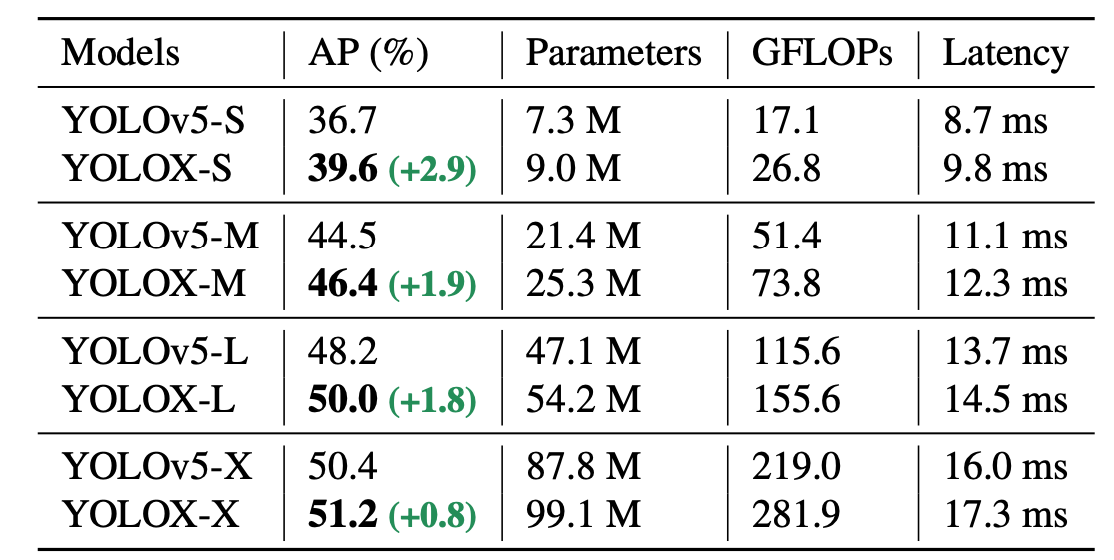
yolox 是旷世今年推出的一个新的YOLO检测器技术报告,核心是将YOLO与anchor free方式实现,性能超过了之前的YOLO系列。此笔记记录Y

灵魂三问 论文做了什么? 该论文是谷歌最近的新作,以语言建模的形式实现目标检测。 论文怎么做的? 将bounding box 和 类别标签离散化为token。
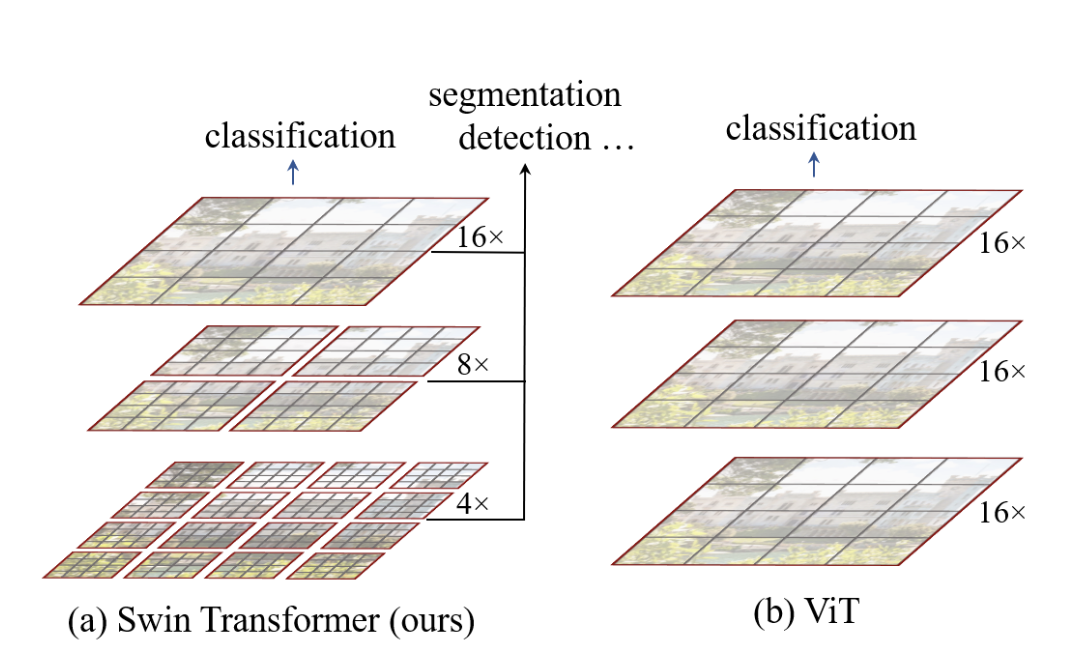
cver 不读swin transformer,遍读transformer也枉然. 个人读完论文感觉最大贡献在于: 将多尺度引入到了transformer
