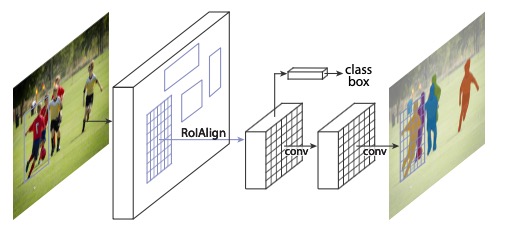
mask rcnn 是何凯明团队在faster rcnn的基础上, 将目标检测与实例分割整合到一起的又一力作, 同时改进了faster RCNN 中 ROI pooling存在的 misalignment

在画风迁移与超分辨率重建以及图像修复等视觉领域, 内容损失又称感知损失, 使用的较多, 在此做个记录, 同时也记录下风格损失 内容损失与提取计算 内容损
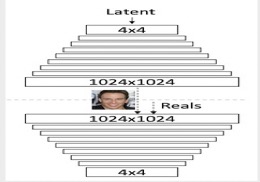
主要贡献 GAN 高清图像生成难的问题 方法 提出新的 GAN 训练方法: 逐渐增加生成器和鉴别器–从低分辨率开始, 逐渐添加新层,以随着训练的进行网络
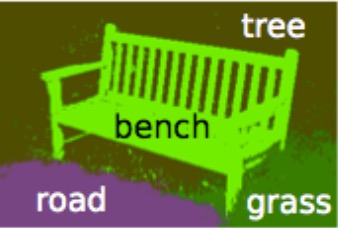
在图像分割中,在FCN之前,流行的是以概率图模型为代表的传统方法. FCN出来之后一段时间,仍然流行的是以FCN为前端,CRF为后端优化. 随着
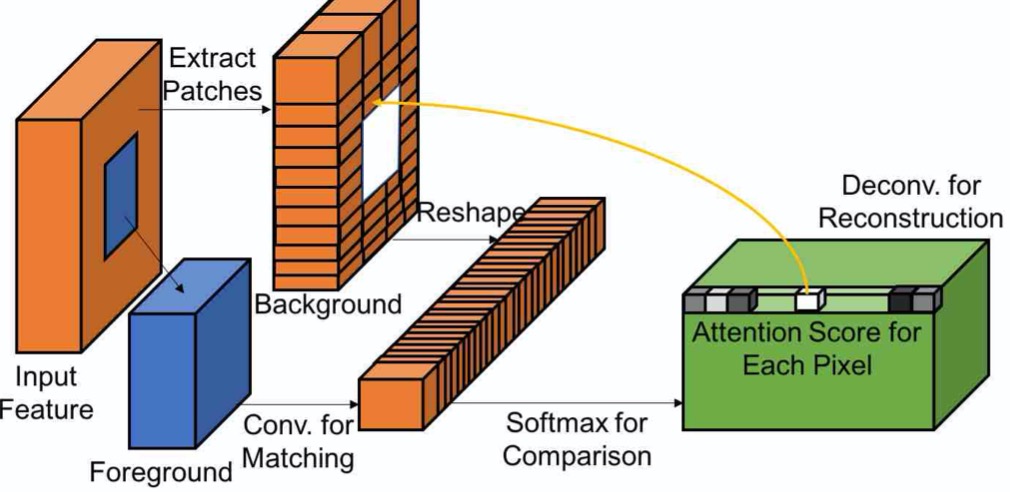
之前介绍过NVIDIA的图像修复方法, 使用的img-img的方法. 由于GAN网络在图像生成方向的大放异彩, 今天review一下, Adobe的
深度学习中的常见归一化方法主要有: batch Normalization, layer Normalization, instance Normalization, group Normalization. 神经网络学习过程的本质就是为了学习数据分布, 如果没有做归一化处理, 那么每一批次训练数据的分

图像修复一直是CV领域的重点与难点, 基于深度学习的图像修复因为其可以学习到丰富的语义信息和潜在丰富的表达能力, 受到研究者们的热捧. 这篇文章主
pytorch可使用flask作为服务器部署,但是由于Python的可移植性和速度比不上c++, pytorch还提供将模型转化到c++端运行
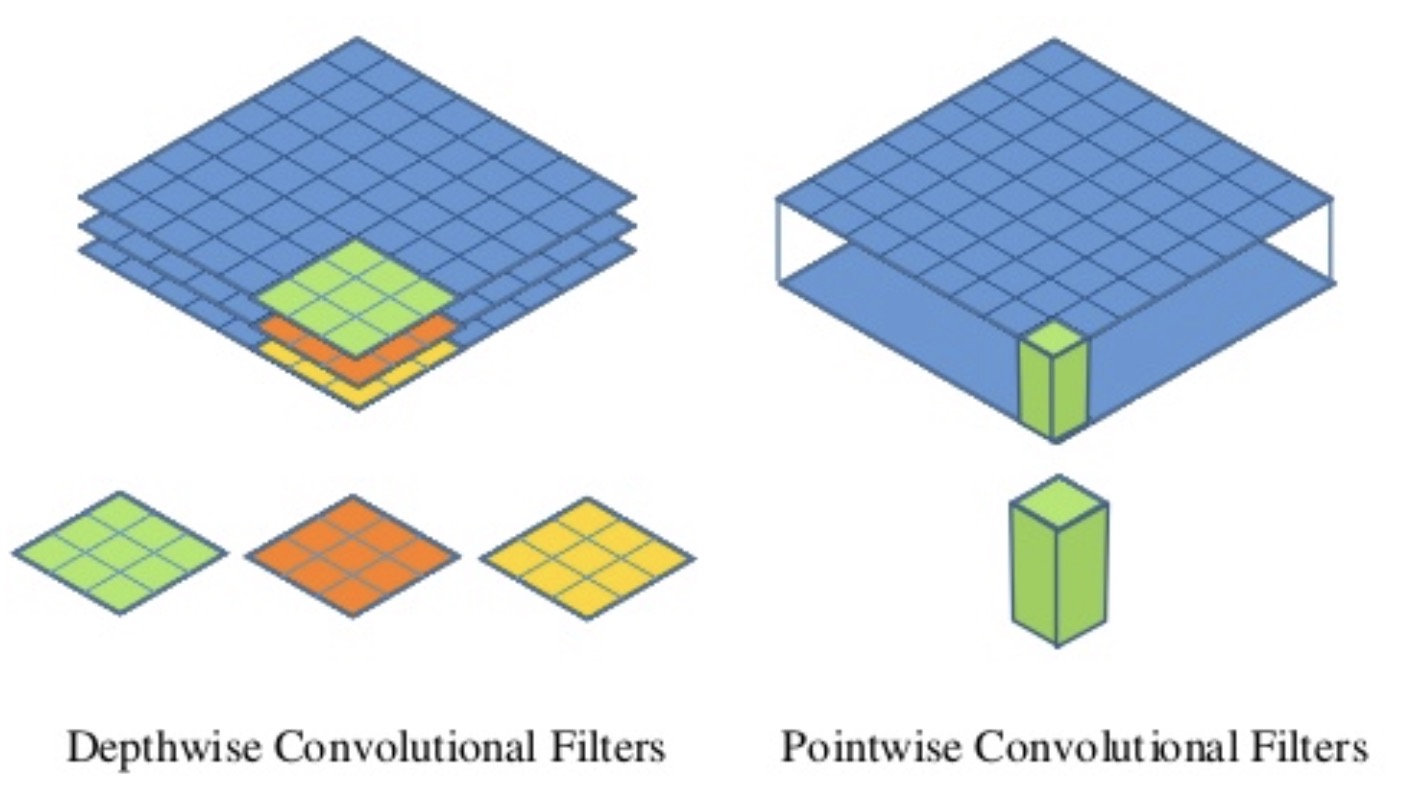
可分离卷积主要包括空间可分离卷积(Spatial Separable Convolutions)、深度可分离卷积(Depthwise Separable Convolutions.

最近看了一下人脸检测的论文, 除了通用的目标检测方法, 看见了这篇论文, 整体上而言和yolo-v3结构是类似的, SSH 设计了不同的检测头. SSH 网络 SSH 网
