
图像修复2: Generative Image Inpainting with Contextual Attention
之前介绍过NVIDIA的图像修复方法, 使用的img-img的方法. 由于GAN网络在图像生成方向的大放异彩, 今天review一下, Adobe的图像修复算法
贡献
- 提出上下文 attention 层以在较远的空间位置显示的关注相关的特征块
- sota
网络结构
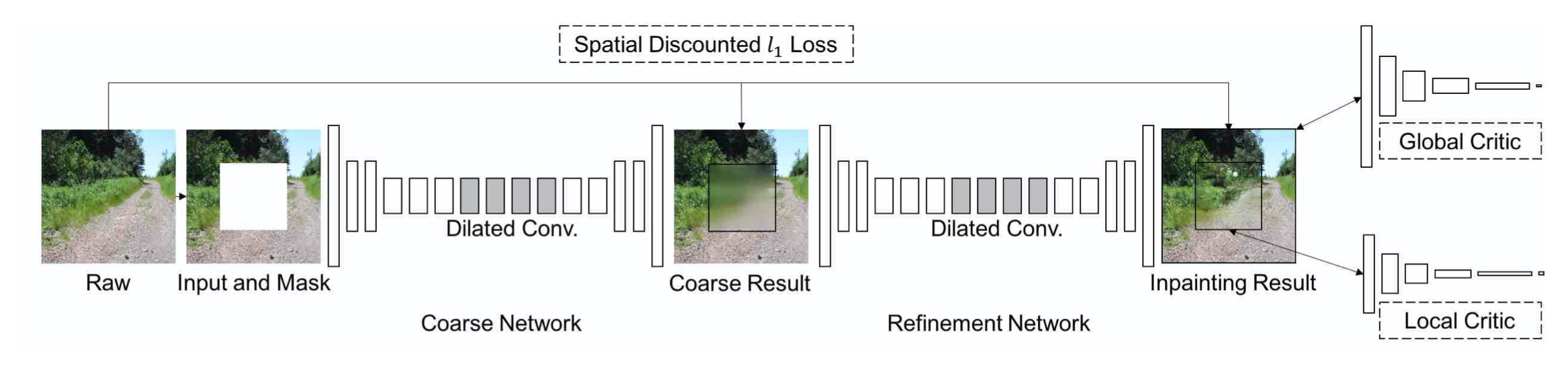
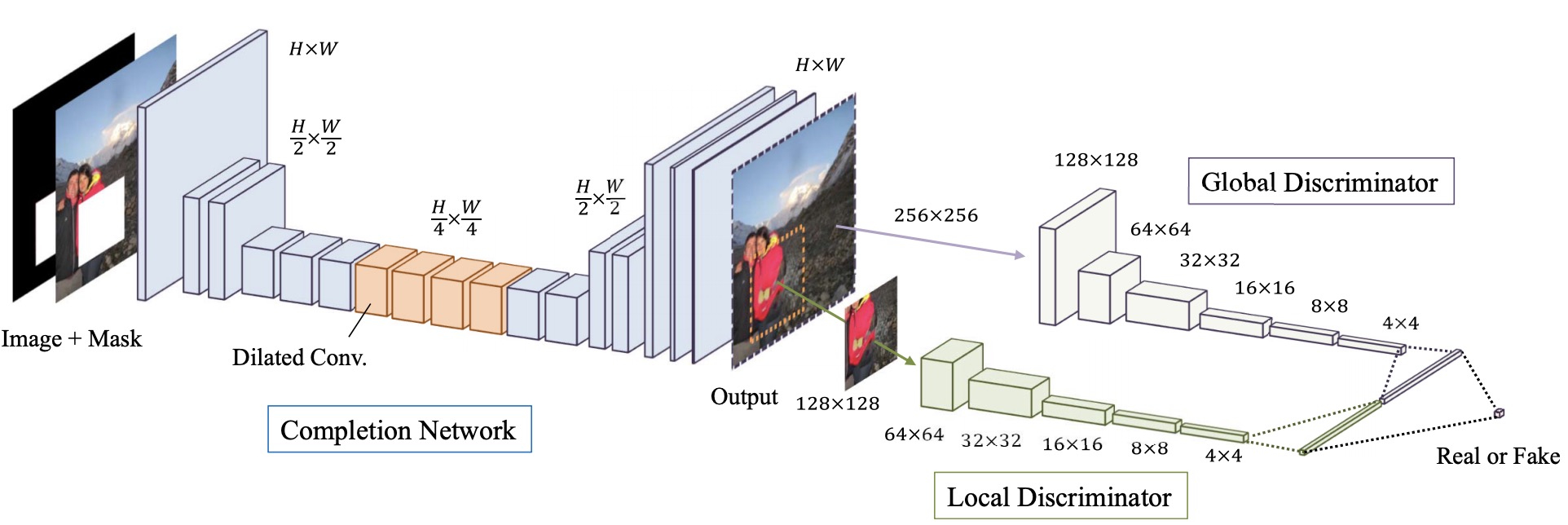
整体网络结构如上图, 生成器输入为带空洞的图片以及mask对, 输出为完整的图片. 作者使用了两个网络来生成图像, 由粗糙到精细, 粗糙部分的输出直接使用重构损失计算loss. 精细部分使用GAN loss. 判别器使用local 与 global WGAN, 整个流程可以参考下图来源(网络的具体设计不同)
Spatially discounted reconstruction loss
对于图像修复问题而言, 给出一个图片修复环境, 被修复部分应该是什么样子并不是唯一的, 若只是用原图作为唯一的GT来计算重构损失的话可能会误导网络的训练过程.
直观而言, 靠近空洞边的像素比靠近空洞中心像素的模糊性更低. 文中使用加权的 mask 引入了Spatially discounted重建损失, mask 的值为 $\gamma ^l$, $\gamma$ 为0.99, $l$ 为当前像素到最近邻已知像素的距离. 每个像素点计算重构损失时乘以对应的权重.
Contextual Attention
上下文关注层学习从已知的背景块中借用或复制特征信息的位置,以生成丢失的图像块.
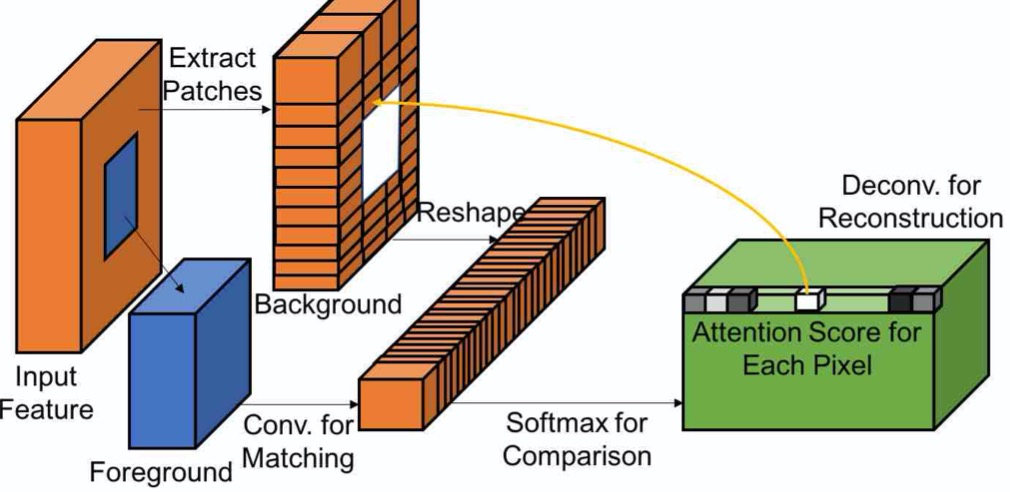
匹配与关注
如上图, 首先在背景中提取特征块(3×3)并将它们重新整形为卷积滤波器. 为了匹配前景块{fx,y }与背景{bx’,y’},我们内积(余弦相似度)进行测量来度量以$(x,y),(x ^·, y ^·)$ 的相似性, 然后用 x’y’的维度与缩放的 softmax 来衡量相似度,得到每个像素的注意力得分:
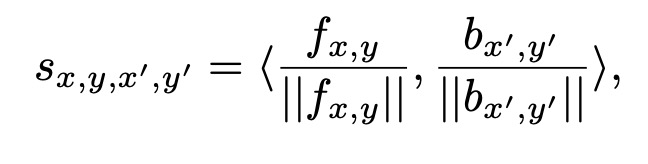
联合修复网络
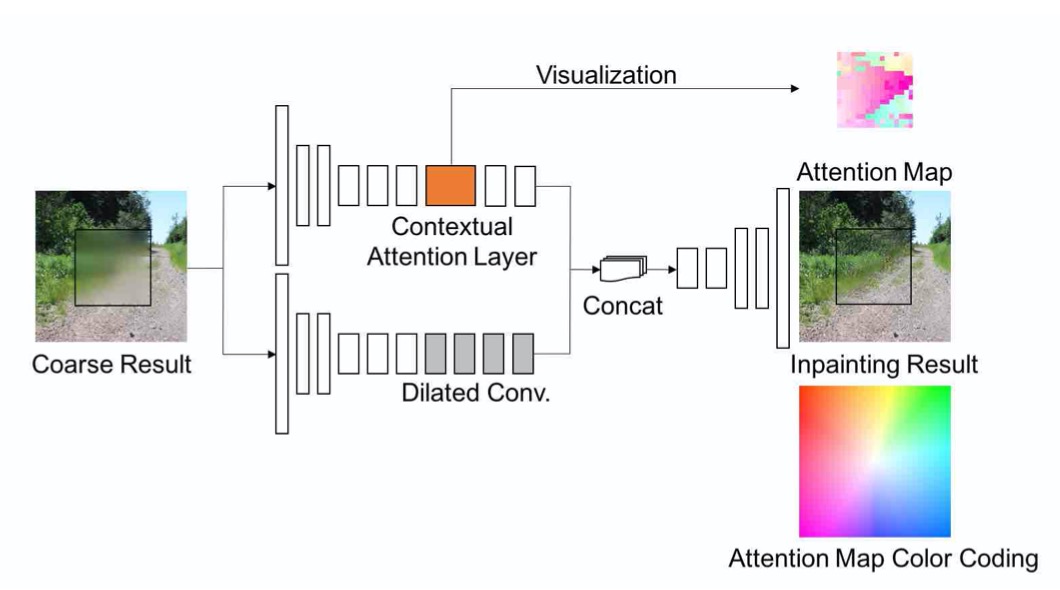
为了集成注意力模块,在精细化生成层引入了两个并行编码器.
result
下图为原论文中的两个结果展示图, 只能说真的👍

使用
对于图像修复, 可以落地之一便是水印修复, 使用迁移学习迁移到实际场景下, 不再使用随机的box, 展现两个我的实验结果, 对比了在修复时原图带不带mask覆盖的对比, 可见保留背景效果更好:

