
ViLD(Vision and Language knowledge Distillation): 基于视觉和语言模型的zero shot 目标检测
对于常用的目标检测而言,测试集和训练集的类别时保持一致的,即我们想要检测什么,那么训练集就有该类别的数据. 对于zero-shot 即测试集的出现的目标类别可能没有在训练集里出现过,也就是所谓的open-vocabulary 检测.
论文三问?
- 论文做了什么: 提出一种新的zero-shot 的目标检测方法
- 论文怎么做的: 核心思想–基于two-stage 的目标检测器 + 图像-文本embeddeding匹配, 第一个阶段不针对具体的类别(万能检测器),第二个阶段使用语言模型进行zero-shot的分类,如CLIP
- 论文效果: 在 LVIS 数据集上对新类别的检测效果超过基于有监督学习的方法
ViLD
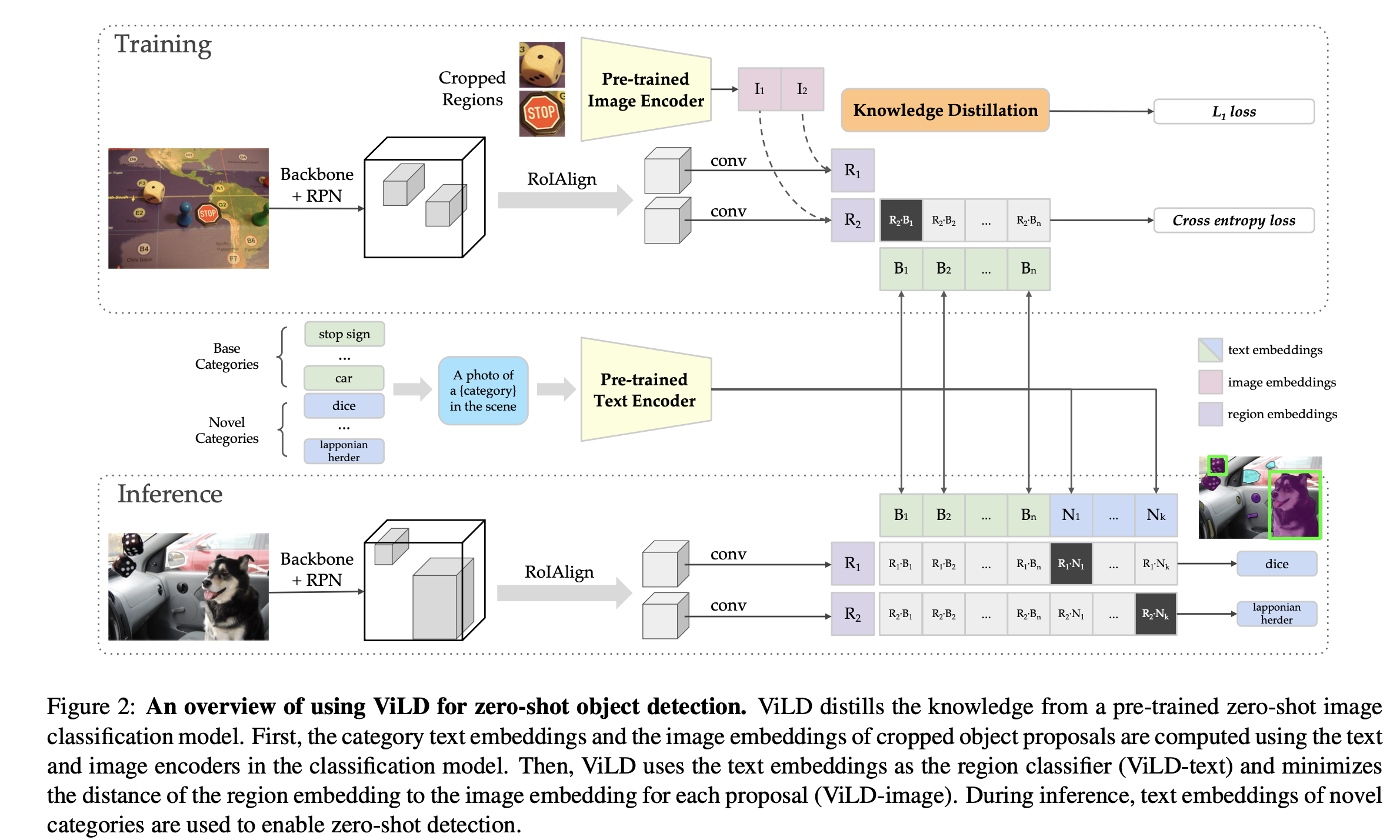
ViLD 总体架构如上图, 无论是训练还是推理,都可以拆分成两个阶段,第一部进行 region proposal 得到检测框,此时的检测框不带类别信息,第二阶段对得到的 proposals 进行分类,分类采用文本-图片embedding匹配的方式.
Object proposals for novel categories
为了在测试时能识别新的类别,论文中使用Mask-Rcnn,将第二个stage的指定类别的模块替换为无类别的通用目标回归、分割模块. 即输出坐标和mask. 针对所有的base类别,对每个ROI只输出一个box和一个mask. (这个地方暂时有个疑问,只输出一个mask可以理解,因为mask rcnn 中的分割输出是80通道的. 不应该一个ROI本来就输出一个box吗?有空看看代码去确认)
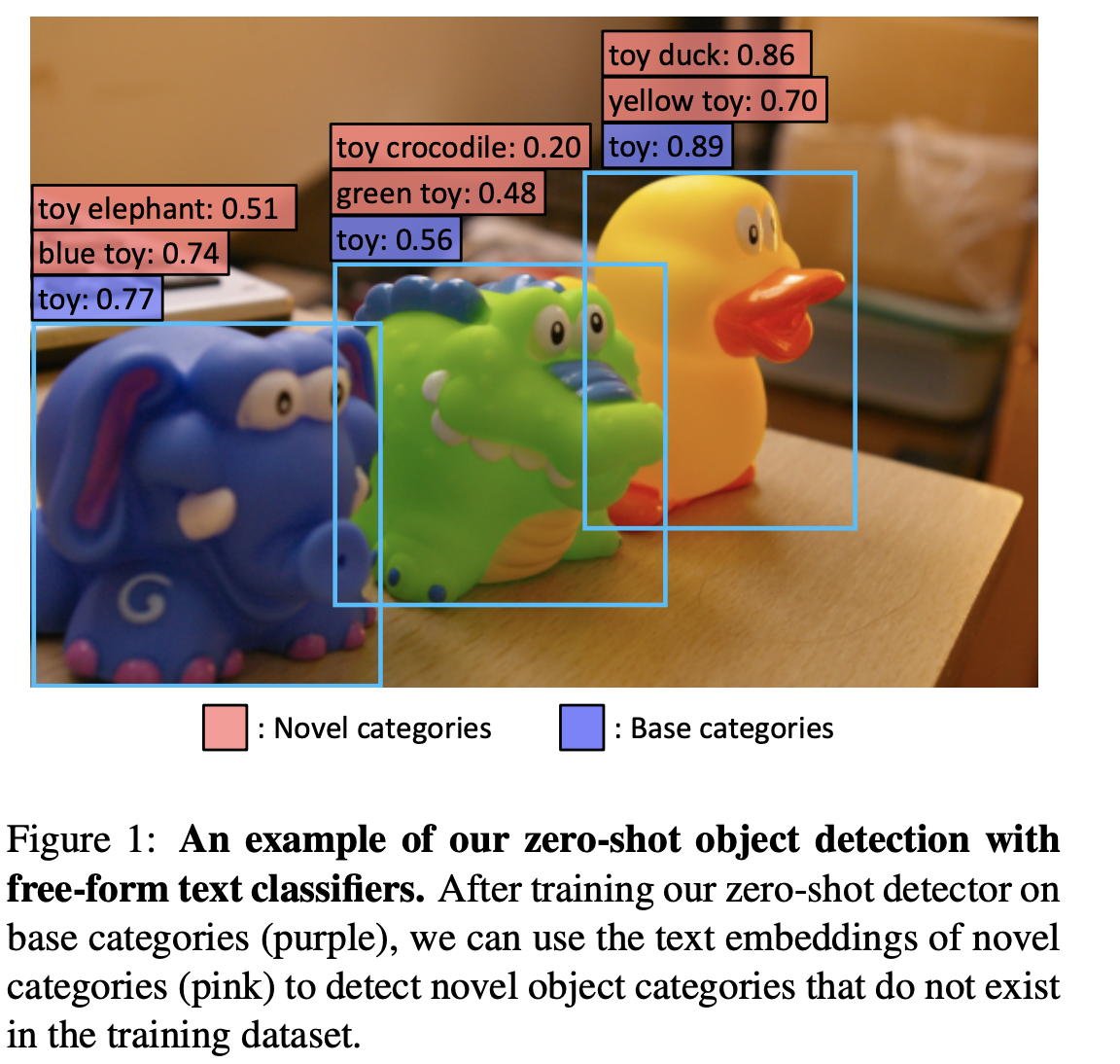
如上图中所示,训练检测器实在基本类别上训练的,测试时可能会对基本类别细分.
Zero-shot detection with cropped regions
通常来说,一旦得到候选目标框,就可以直接使用训练好的zero_shot的图像分类器进行分类. 实际中对于检测出的候选目标区域,会过滤掉背景概率高的区域以及进行NMS只取 Top-K 的区域.作者对于每个proposal取了1 X 和 1.5X的区域进行图片编码, 1.5倍是为了获得更多上下文信息.
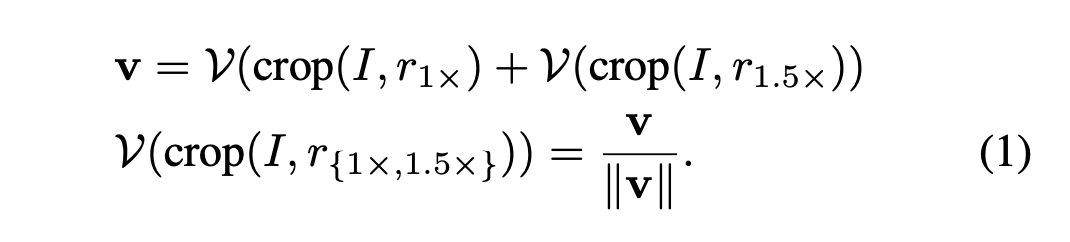
Replacing classifiers with text embeddings
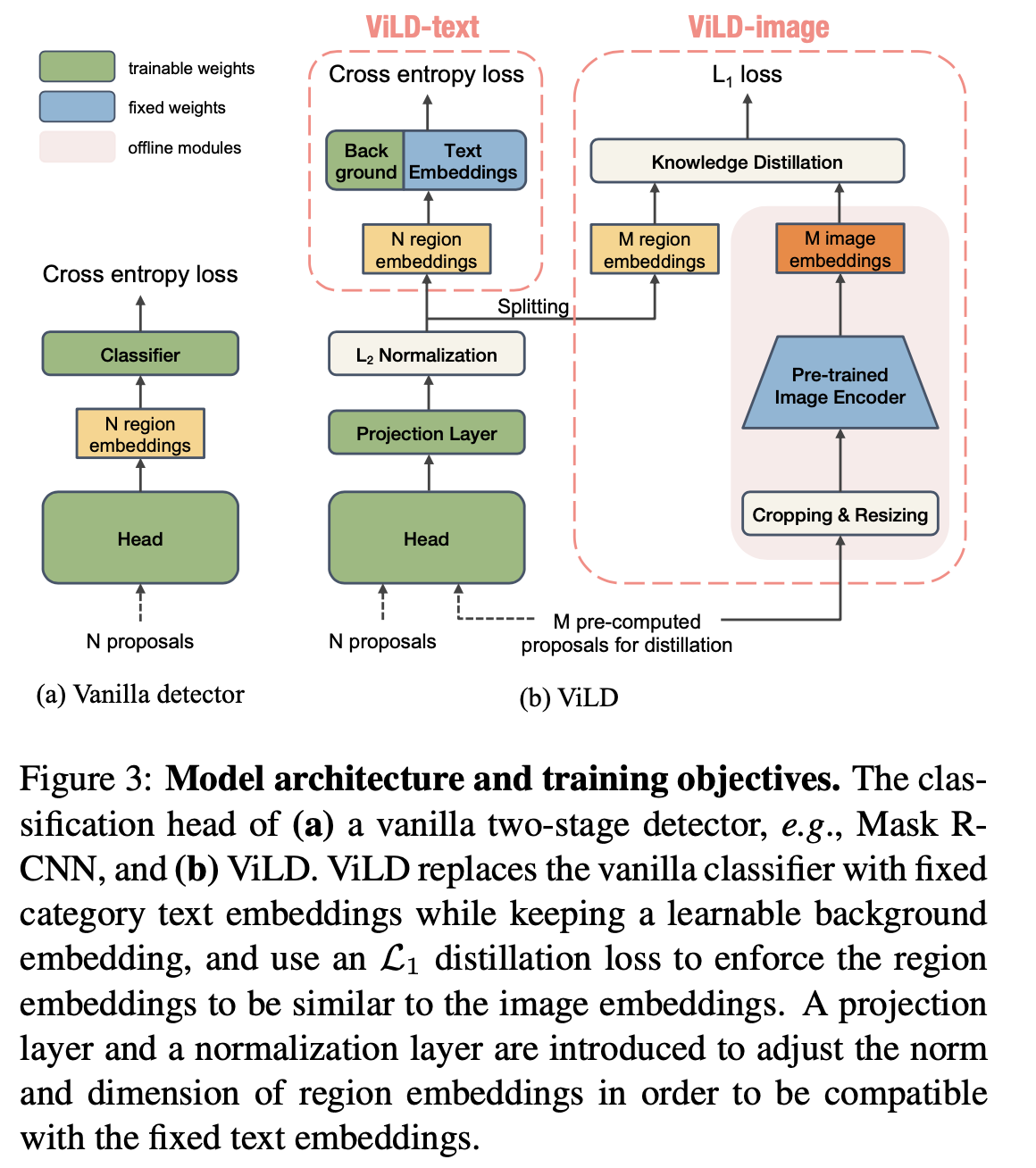
论文使用基于文本embedding 的分类器来分类,因为既然是zero-shot 的目标检测,基于写死固定类别 softmax或者 sigmoid 肯定是不行的,作者采用 CLIP 的思想,计算proposal 的编码和指定类别的文本描述编码的相似度来分类. 详细可看上一篇关于CLIP的文章.
上图中的ViLD-Text被用来分类,对于提取的proposal,作者使用一个轻量级的 region embeddeding 模块来编码,对于基本类别使用文本编码器使用CLIP的 text-encoder(权重固定)提取 embedding 向量,对于背景类,让其自己学习出一个 embedding.
训练时计算 region embedding 和 每个文本编码的相似度, 然后和CLIP 一样构造交叉熵损失.
Distilling image embeddings
上图中的 ViLD-image 用来知识蒸馏,目的就是将 CLIP 的图像编码器的知识迁移到基于region 的编码器. 文中使用CLIP的预训练权重来提取文本编码,那proposal呢,其实也可以直接用 CLIP的图片编码器来编码,但是由于CLIP训练图片编码器是基于全图的,proposal 相对来说和整图存在差异. 而我们不会去训练 CLIP 的文本编码器,直接使用CLIP的文本编码器,但是CLIP的文本编码器和图片编码器是配对训练的. 因此,我们想要训练一个基于 proposal的图片编码器, 这个编码器需要和CLIP的 图片编码器学出的embedding 要保持一致. 通过知识蒸馏来校准.
上图中的 ViLD-Image 对于给定的 M个proposal,分别通过region embedding 和 预训练好的 Image-enocder(比如 CLIP的Image-encoder)得到各自的编码输出,最小化输出的 L1 距离, 目的就是让教师网络(预训练的图像编码器)的知识蒸馏到学生网络(region embedding)
Experiments
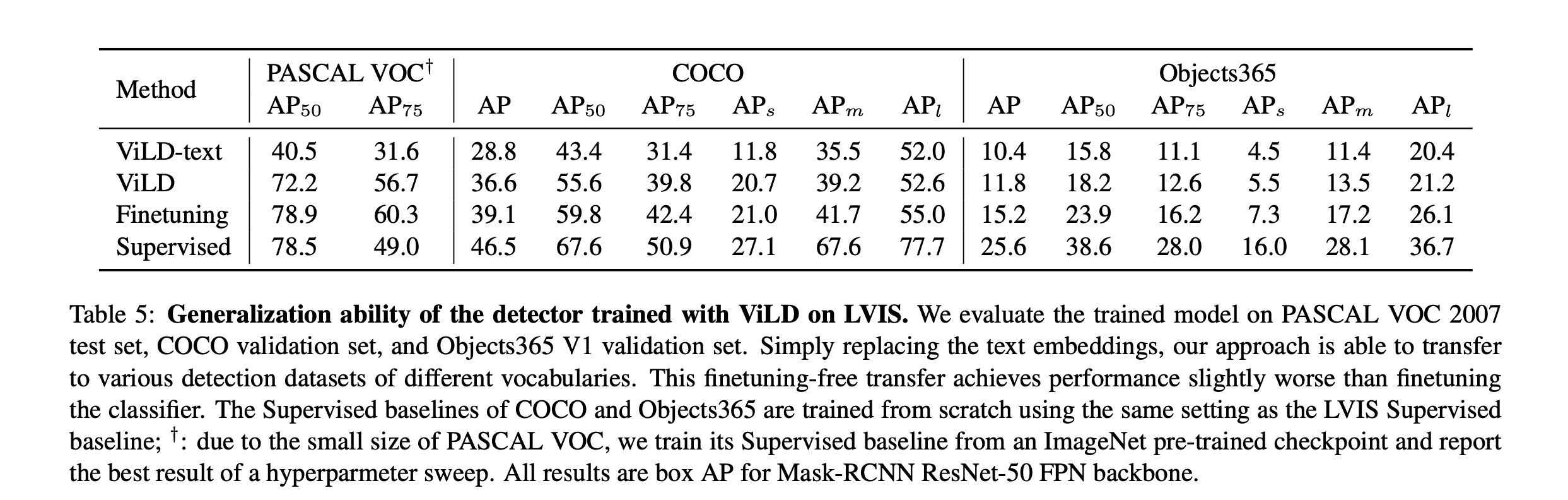
上图是评估结果,可以看出知识蒸馏后效果提升很大. 和有监督的对比差10个点左右.

上图是以这种方式做检测-识别的另一个优势,可以得到更细粒度的目标描述.
总结
该论文是对于zero-shot 目标检测的一个新的思路,最近的zero-shot 的识别也基本都是基于文本 embedding的思路去做的, 文中也说了可以改进的地方也有不少.
REF
Zero-Shot Detection via Vision and Language Knowledge Distillation
