
CLIP: Learning Transferable Visual Models From Natural Language Supervision理解与使用小记
CLIP 是 openAI 提出的用以将图像映射到文本描述空间中,连接图片和文本,可以用来提取图像 embedding, 用作zero-shot 迁移。
CLIP 结构
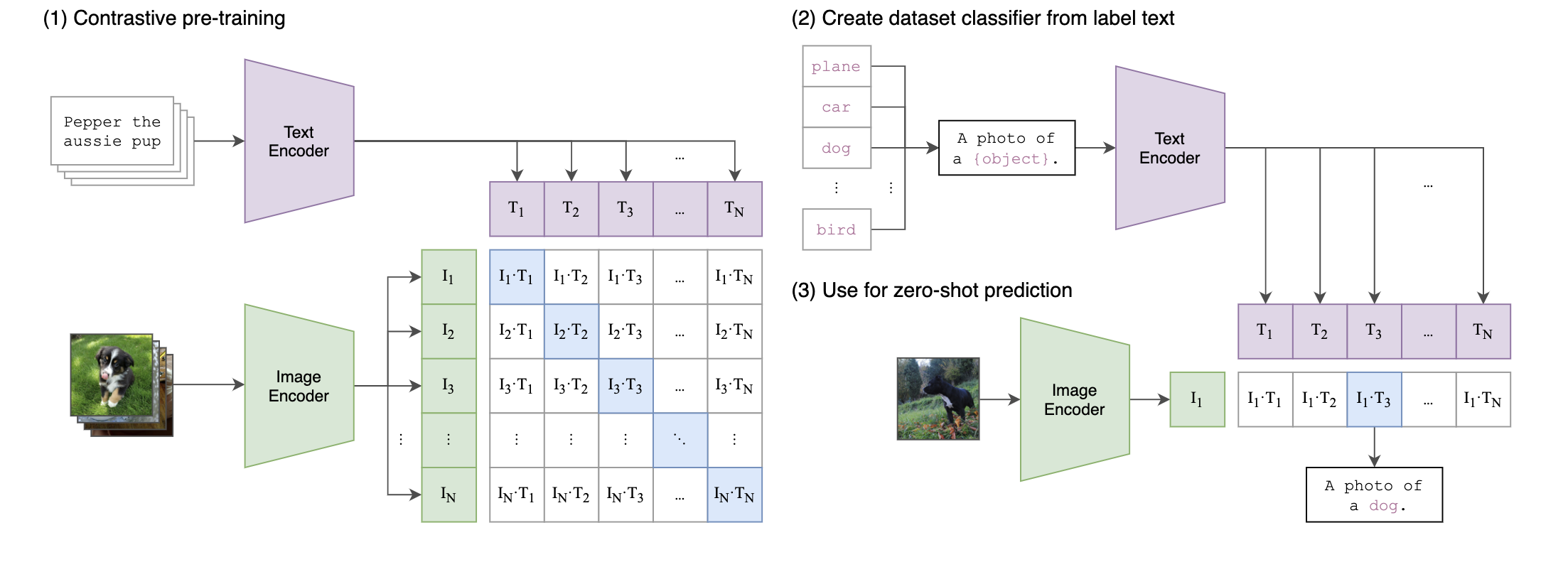
CLIP 总体结构如上图:
- 通过对比学习,使用网络上海量的 <图片,文本描述> 数据训练图像编码器和文本编码器,得到两个编码器
- 从给定的文本标记中构建一个分类器,按照给定的格式,使用文本编码器生成文本的embedding 向量
- 给定一张测试图片,通过图像编码器得到图像 编码向量,将图像编码向量与所有的给定的文本编码向量计算相似度匹配,即进行了分类.
CLIP 训练
CLIP使用的是已经在互联网上公开提供的文本-图像对。自我监督学习、对比方法减少对标注图像的依赖。

CLIP 训练伪代码如上图:
- 分别将图片和文本通过编码器进行编码
- 分别针对文本和图像使用可学习的映射矩阵精文本特征和图片特征进行投影
- 将投影后得到的矩阵进行点积,等价于计算cosin 相似度
- 然后横向、纵向计算交叉熵损失,和 n-pair mc loss 一致,只是额外增加纵向的约束
CLIP 就是将图像对的对比学习更换到图片-文本对的对比学习
CLIP demo
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("/Users/linyang/Downloads/sewer.jpeg")).unsqueeze(0).to(device)
text = clip.tokenize(["a photo of suck", "a photo of weding", "a photo a sewer", "a photo of stool"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs)
上诉官方demo, 可以用来进行zero-shot 的图像识别, 自己指定文本描述。
