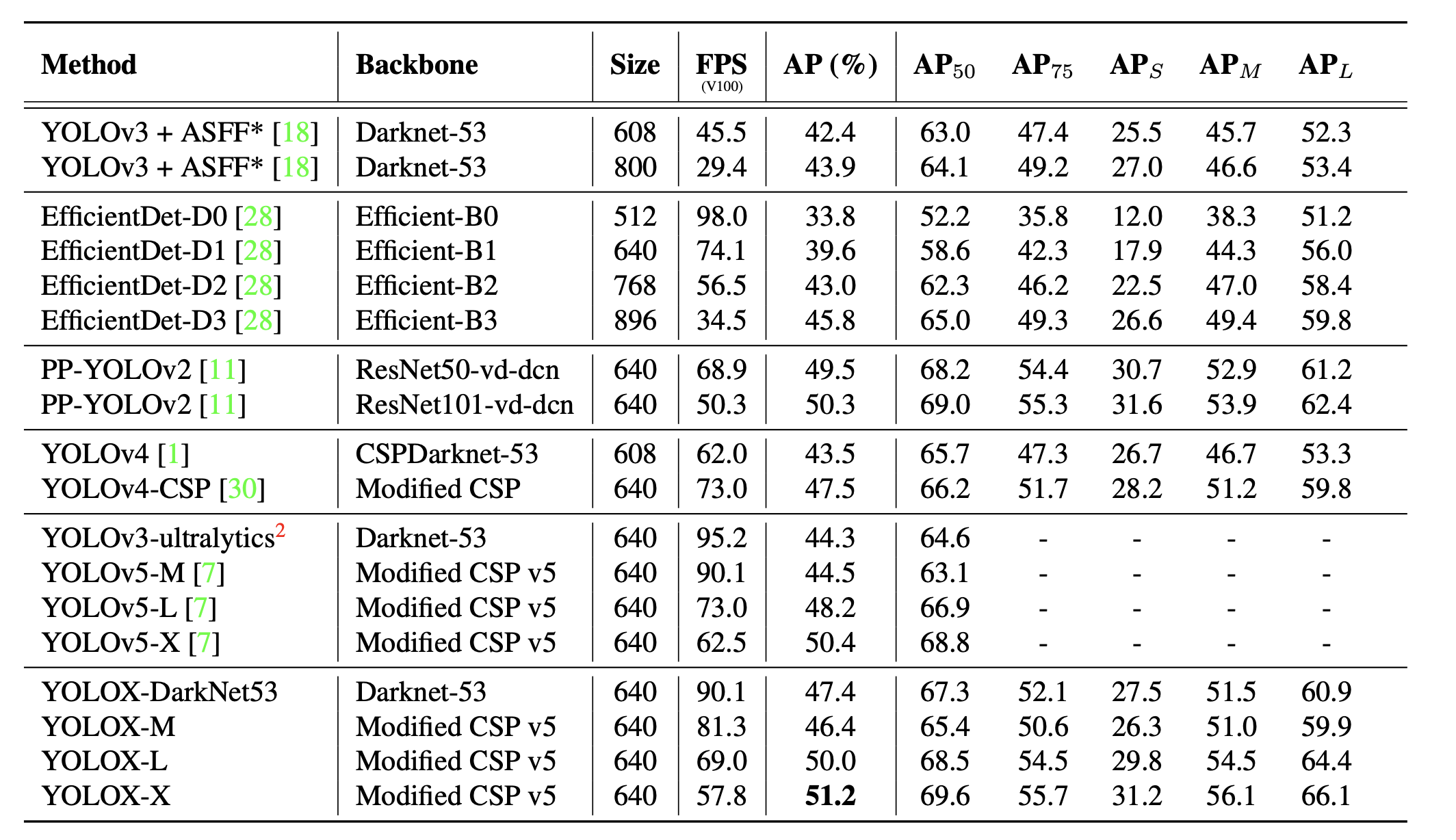
Yolox阅读笔记
yolox 是旷世今年推出的一个新的YOLO检测器技术报告,核心是将YOLO与anchor free方式实现,性能超过了之前的YOLO系列。此笔记记录YOLOx做了哪些改良.
Yolox 的构成
yolov3 baseline
darknet53 作为backbone,增加 SPP结构; 训练策略有:EMA,cosine lr schedule, IoU loss and IoU-aware branch. RandomHorizontalFlip, ColorJitter and multi-scale for data augmentation.
decoupled head
原始的一系列YOLO算法中回归器、分类器合在一起。在RetinaNet里面已经验证了分开能提高性能,这也很明显,各司其职,参数增加,提升性能。如下图
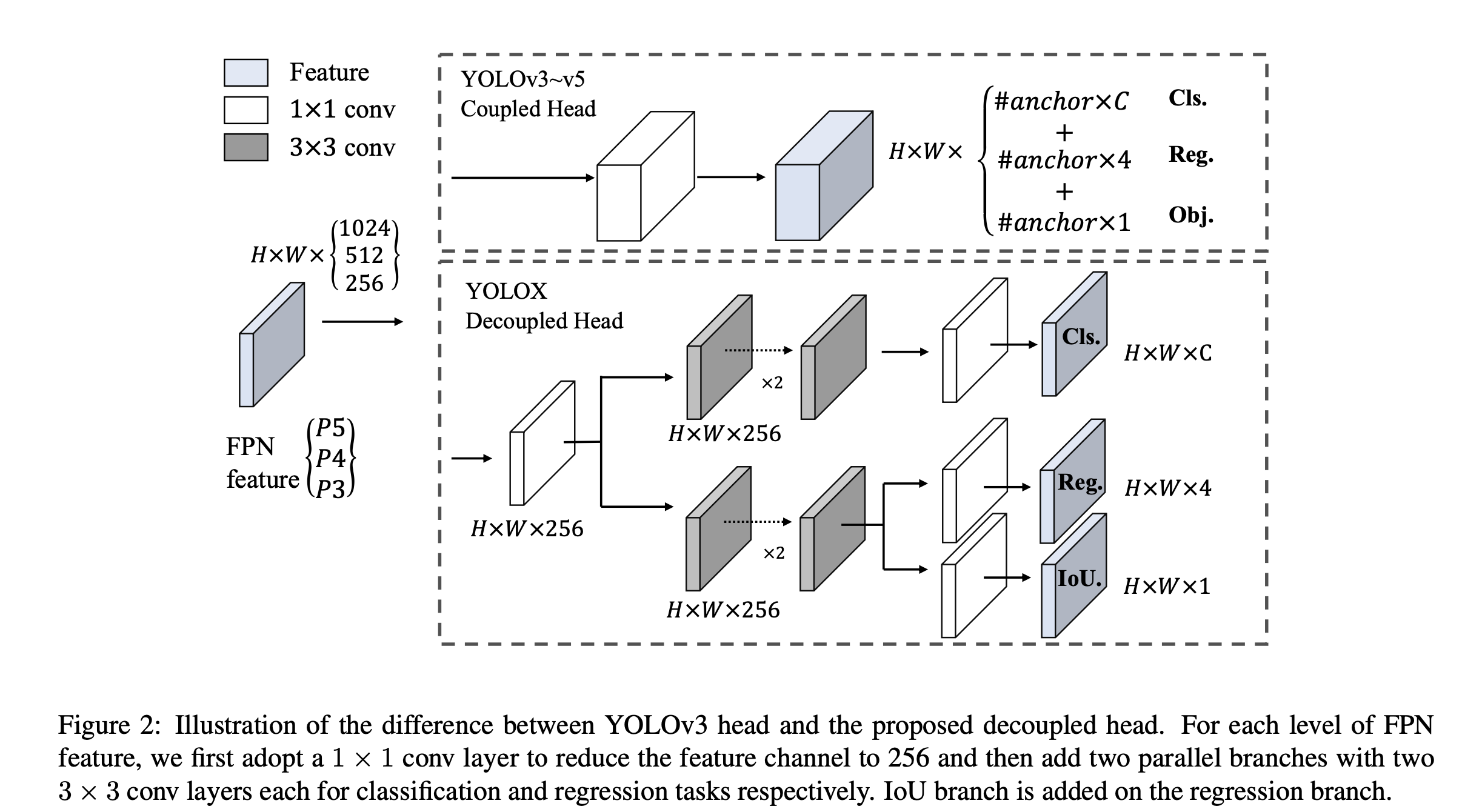
yolox 将回归、分类、IOU预测都解耦作为单独的分支。
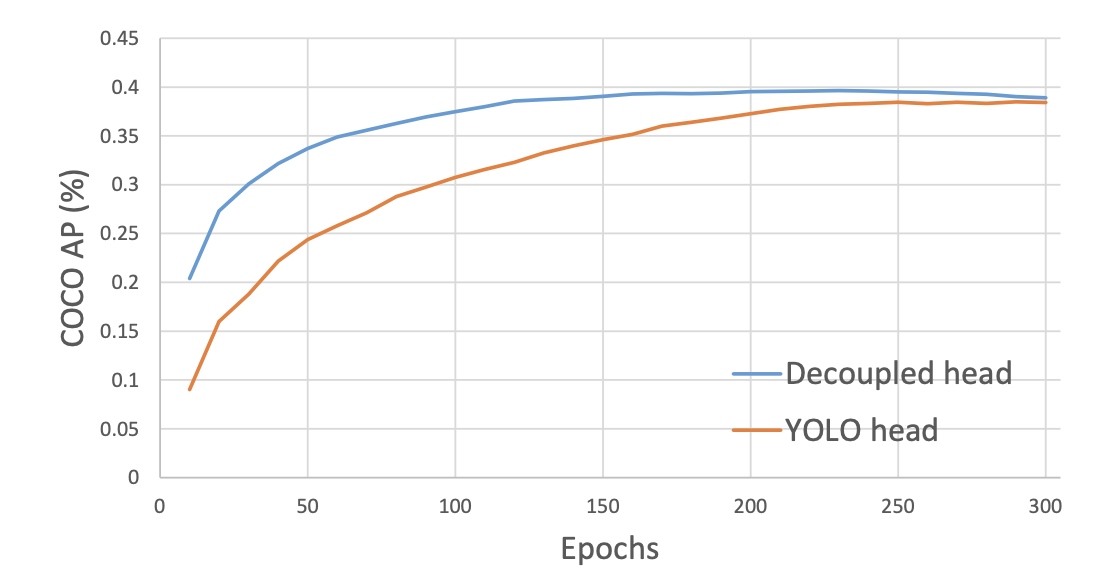
从上图可以看出,解耦后能加快收敛,前期各司其职。但是随着训练轮次的增加,最后二者达到的AP趋于一致.
Strong data augmentation
Mosaic and MixUp
Anchor-free
这是YOLOx 最大的区别,还能叫YOLO吗?😄
yolox anchor free 实现细节:
每个位置只预测一个目标,且直接预测四个值,分别是相对网格左上角的偏移以及预测框的高和宽。
正样本分配:
- 物体中心点所在位置设为正样本,一个点最多一个正样本. 以此种方式分配正样本 AP 可达 42.9
- Multi positives– 以上诉正样本为中心点,取四周9个为正样本,这个和YOLOv5 的分配机制一样,增加正样本数量,加快收敛,AP提升到 45
- SimOTA: 该样本分配方式基于旷世的OTA论文的改进,具体这儿不抠细节了,AP能提升到 47.3
simOTA
- 先验框 和 GT 初步过滤,得到哪些先验框可能有正样本
- 筛选出的框与GT 计算cost, 包括分类 + IOU cost
- 指定 k 个框,每个gt 选出IOU 前 K 大的框,然后 k 个IOU 求和向下取整,即当前GT 应该分配的框个数,取cost 里面最小的k个与当前gt 匹配
- 如果某个框匹配多个GT,选择cost 最小的GT 与之匹配
vs sota
对比YOLOv5
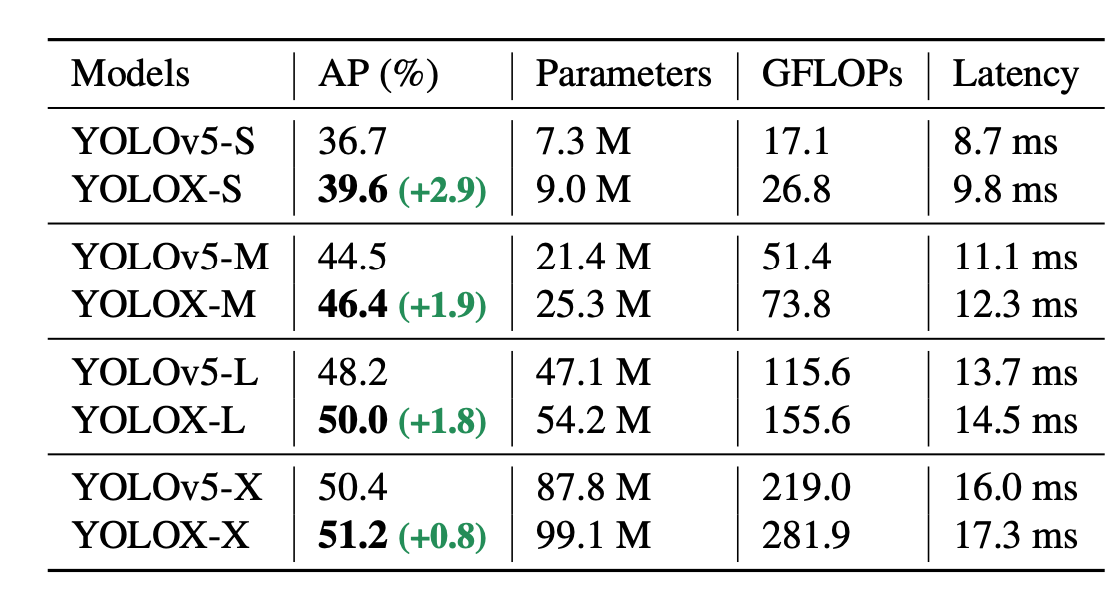
vs sota