
Object detection(2): SPPnet
在 RCNN 中说到, RCNN存在的一个问题是需要将region proposal进行warp到固定尺寸,这会带来失真等影响. 这是由于具有全连接的CNN对输入尺寸有限制. SPPnet的初衷即为解决CNN输入尺寸限制的问题.
主要贡献
- 提出 Spatial Pyramid Pooling, 解决CNN限制输入尺寸问题
- 针对于RCNN每个region proposal需要单独提取特征的问题, SPPnet对一张图片只需提取一次特征图
- 目标分类与检测, 结合 SPP 能带来性能的较大提升
Spatial Pyramid Pooling Layer

如上图所示, 对于之前的带有全连接层的CNN而言, 输入尺寸被限制, 在 SPP 之前的做法是先对图片进行 crop 和 warp, 得到固定大小的图像块, 但是此操作会带来失真的影响. SPPnet 通过在全连接层之前接入 Spatial Pyramid Pooling Layer, 将不同尺寸的 feature map 池化为相同大小的特征. 具体如下:
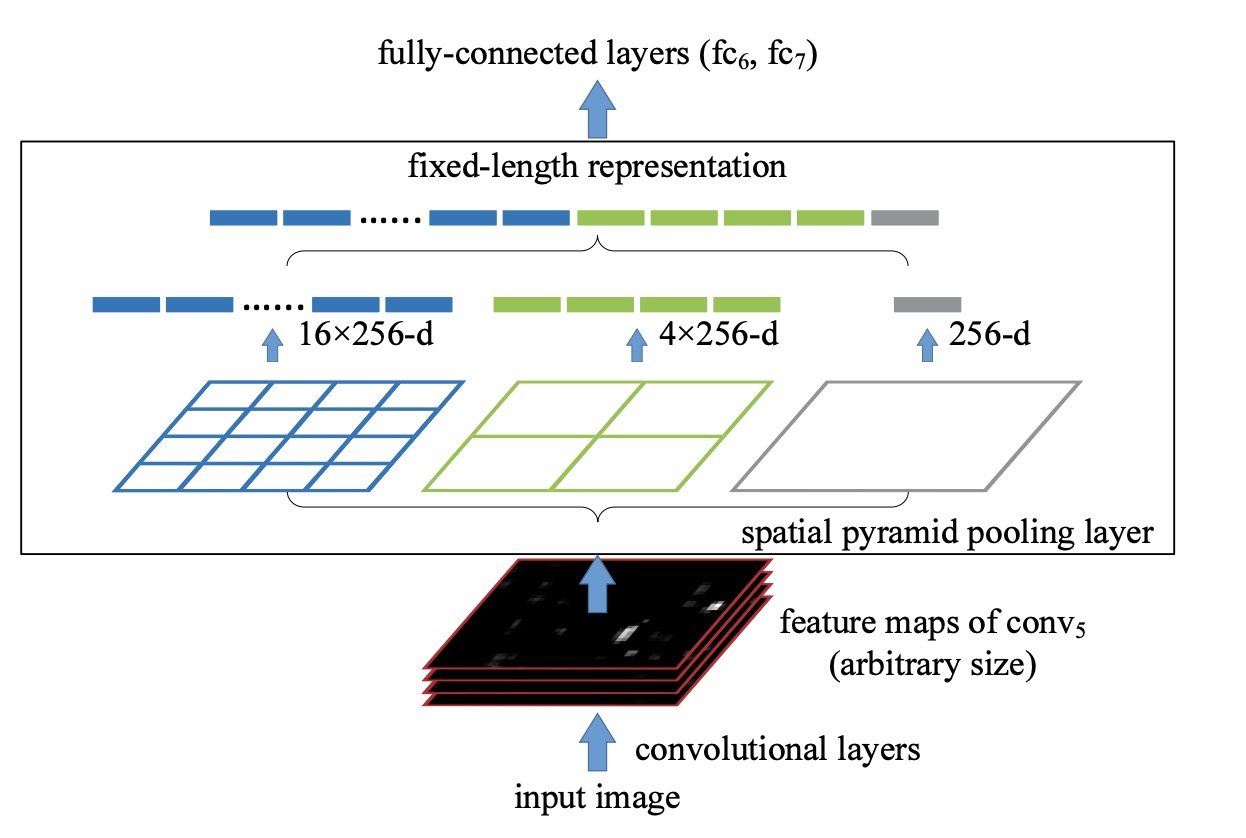
按照传统, 一般在最后一层卷积层和全连接层之间会有一个池层化或没有, 在SPPnet中, 使用多个不同尺度的池化层.
上图使用了三级SPP池化. 假如 conv_5 输出特征图通道数为 256. 池化操作如下:
- 将每个通道池化为 1 个值, 得到 1 * 256 维 vector
- 将每个通道池化为 4 个值, 得到 4 * 256 维 vector
- 将每个通道池化为 16 个值, 得到 16 * 256 维 vector
- 将上诉特征 vector 合并为一个 一维vector, 送入全连接层
因此, 对于不同的输入尺寸, 在进入全连接层前, 通过 SPP layer 能得到相同大小的特征 vector. 上诉每个通道的池化操作不限, 论文中使用的是最大池化.
SPPnet for object detection
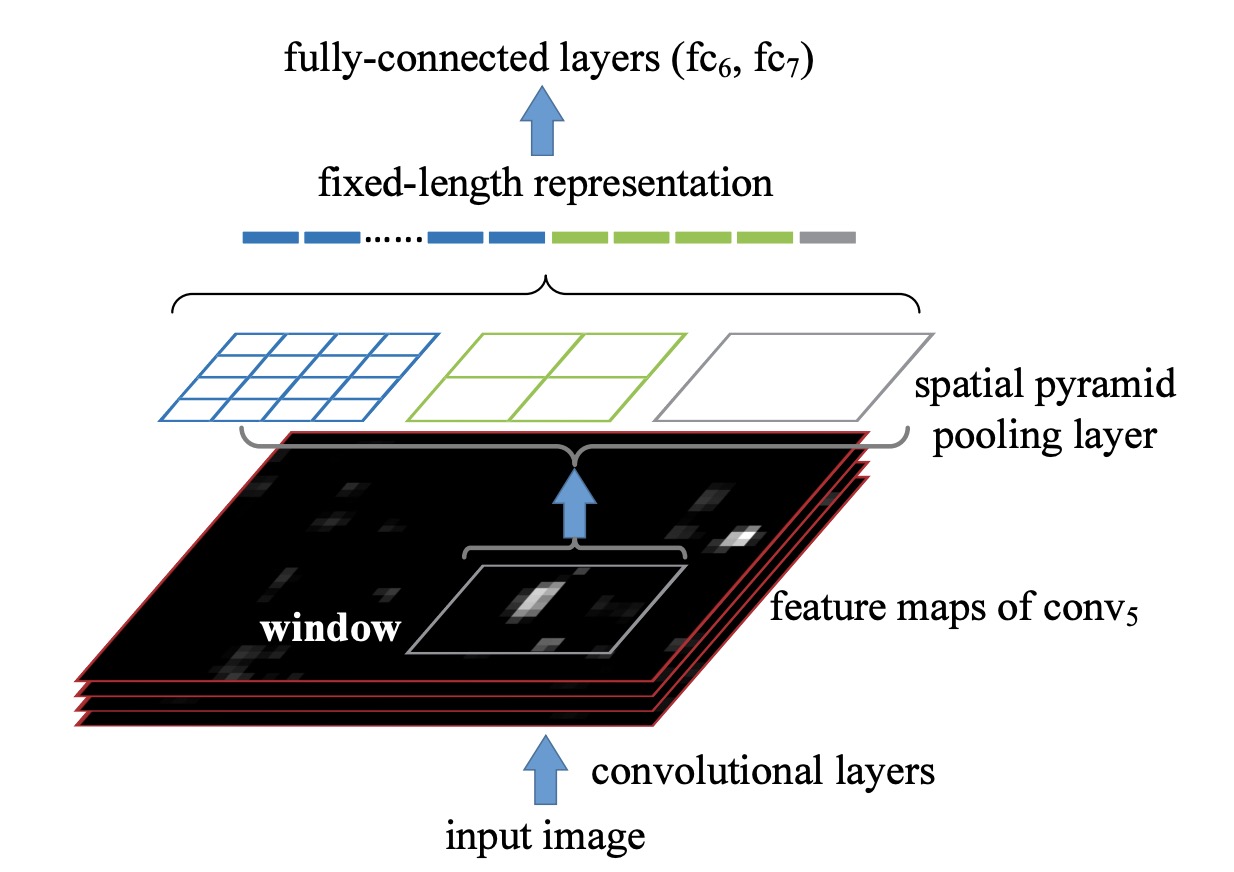
如上图所示, SPPnet 用于目标检测流程如下:
- 通 RCNN 使用 SS 算法得到大约2000个 region proposals
- 输入图像经过 CNN 得到最后一次卷积层的 feature maps
- 将每个region proposal 映射到 feature maps 上–上图中的 window, 将对应 window 所包含的feature maps 送入spp layer, 然后进入fc 层.
相比较于 RCNN, SPPnet仅对全图进行一次卷积, RCNN 是每个 proposal 均要进行一次卷积. 区别如下:
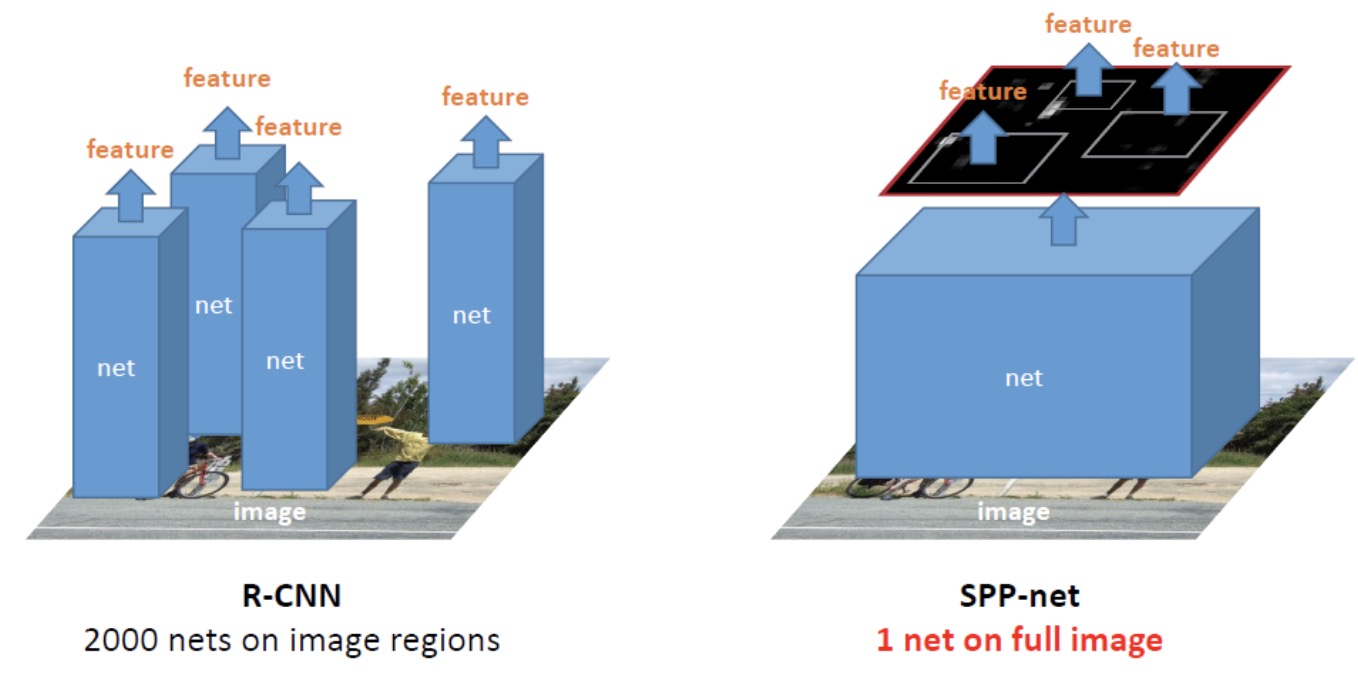
对卷积操作而言, 目标在原图中的位置和feature maps 中的位置是想对应的, 因此对于每个proposal 不用单独用CNN网络提取特征, 只需要全图卷积一次提取对应位置的 feature maps, 具体计算公式例子详见论文. 如下图:

优势与不足
可以看出 SPPnet解决了 RCNN 中频繁进行卷积以及大小限制的问题, 提升了检测的速度与精度. 但是仍然不是端到端的, 后续的分类与边框回归和RCNN 一样. 因此, 为 fast rcnn埋下了伏笔.
ref
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
