
Seq2Seq模型: 从理论到实践(一)
理论结合实践是学习的最佳方式, 本文图片、代码来源于pytorch-seq2seq
Seq2Seq 模型
对于序列预测, RNN及其变种LSTM、GRU等无疑是最好的解决模型. 对于单个RNN、LSTM模型而言, 模型在每个时间步进行提取特征并输出(也可以在某个时间步不显示的输出), 但是其输出序列的长度最大等于输入序列的长度. 在现实任务中, 比如语言翻译, 源语句和目标语句长度不一样, 单个LSTM就无法完成由输入到输出的映射.
既然单个LSTM无法完成, 考虑用两个. 用一个LSTM来编码输入序列得到固定大小的表达向量, 再用另一个LSTM来解码该向量. Seq2Seq 的典型模型为 Encoder-Decoder 模型, 下图为语言翻译的Encoder-Decoder 模型.
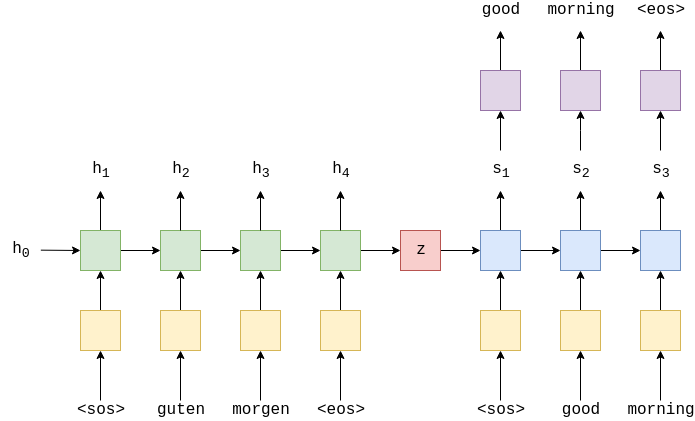
在编码器的每一个时间步,根据当前单词的词向量$e(x_t)$以及上一个时间步的hidden状态.
$$ h_t = EncoderRNN( e(x _t), h _{t -1})$$
在编码器对整个语句编码完成后, 得到 context vector, 解码器将 context vector作为输入. 在解码器的每一个时间步, 输入为目标词的词向量以及解码器上一个时间步的状态.
$$s_t = DecoderRNN(d(y_t), s _{t-1})$$
解码器需要将当前时间步的hidden状态对应到实际的单词, 通过使用全连接层, 输出为词汇表的大小, 每一个位置对应属于一个词的概率.
深入代码
编码器构建
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
# input_dim: 源词汇表的大小
# hidden units LSTM 每一个门的神经元个数
self.hid_dim = hid_dim
# LSTM 层数
self.n_layers = n_layers
# Embedding 初始化时指定词汇表的大小和需要得到的词向量大小
# 前向传播时输入数据为该语句中每个单词在词汇表中的index,会根据index去查找
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
# src shape为 [len src, batch_size]
# src 中每列为一个句子, 值为该句子中每个单词在词汇表中的index, 由于句子拼接成数组要求维度一样, 所以当batch size内句子长短不一样时,
# 将短句子全部填充为最长句子的长度, 填充时以指定的填充单词index填充
# 进行embedding, 得到固定大小的embedded 向量, shape=[len src, batch_size, emb dim]
src = self.embedding(src)
embedded = self.dropout(src)
# LSTM 输入为[len src, batch_size, emb dim], 每一个单词作为一个时间步, 每一个单词的特征大小为embedded 向量大小
outputs, (hidden, cell) = self.rnn(embedded)
# outputs = [len src, batch size, hid dim * n directions]
# hidden = [n layers * n directions, batch size, hid dim]
# cell = [n layers * n directions, batch size, hid dim]
# 返回最后一个时间步的hidden state, cell state 作为学到的 context vector
return hidden, cell
解码器构造
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
# 目标词汇表的大小, 最后的输出层为分类层, 输出属于词汇表中每一个单词的概率
self.output_dim = output_dim
# LSTM 每一个门的神经元个数
self.hid_dim = hid_dim
# LSTM 层数
self.n_layers = n_layers
# Embedding 初始化时指定词汇表的大小和需要得到的词向量大小
# 前向传播时输入数据为该语句中每个单词在词汇表中的index,会根据index去查找
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)
# 全连接层, 对每一个时间步的输出映射为词汇表中每一个词的概率
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x, hidden, cell):
# decoder 每1个batch只输入一个单词, 因此当前输入x shape=[batch_size]
# 例: 当batch_size 为4时, 假如 x=[2,56,5,7], 表示batch[0] 输入单词在词汇表中的index为2(batch[0]... batch[3]即来自4个不同的句子)
# 上一个时间步的状态输出
# hidden = [n layers * n directions, batch size, hid dim]
# cell = [n layers * n directions, batch size, hid dim]
# 由于编码器每次的输入的时间步都为1, 故无法双向
# hidden = [n layers, batch size, hid dim]
# context = [n layers, batch size, hid dim]
# x = [1, batch size]
x = x.unsqueeze(0)
# 得到当前目标单词在目标词汇表中的embedding 表示
# embedded = [1, batch size, emb dim]
embedded = self.dropout(self.embedding(x))
# 解码器LSTM第一次调用时, 传入编码器最后的(hidden,cell)初始化解码器的(hidden, cell)
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
# 由于编码器每次的输入的时间步都为1, 即序列长度 seq len 为1, 且无法双向
# output = [seq len, batch size, hid dim * n directions]
# hidden = [n layers * n directions, batch size, hid dim]
# cell = [n layers * n directions, batch size, hid dim]
# output = [1, batch size, hid dim]
# hidden = [n layers, batch size, hid dim]
# cell = [n layers, batch size, hid dim]
# 得到当前预测的下一个单词分别属于词汇表中每一个单词的概率
prediction = self.fc_out(output.squeeze(0))
# prediction = [batch size, output dim]
return prediction, hidden, cell
Seq2Seq模型
class Seq2Seq(nn.Module):
def __init__(self, src_vocab_size, tag_vocab_size, enc_embed_dim, dec_embed_dim, hidden, layers, drop, device):
super().__init__()
"""
src_vocab_size: 源词汇表大小
tag_vocab_size: 目标词汇表大小
enc_embed_dim: 编码器中的词向量维度
dec_embed_dim: 解码器中的词向量维度
hidden: LSTM 隐层神经元个数
layers: LSTM 层数
drop: dropout
"""
# 需要使用编码器的状态初始化解码器的状态, 因此二者神经元个数和层数必须一样
self.encoder = Encoder(input_dim=src_vocab_size, emb_dim=enc_embed_dim, hid_dim=hidden, n_layers=layers, dropout=drop)
self.decoder = Decoder(output_dim=tag_vocab_size, emb_dim=dec_embed_dim, hid_dim=hidden, n_layers=layers, dropout=drop)
self.device = device
def forward(self, src, tag, teacher_forcing_ratio=0.5):
"""
:param src: src = [src len, batch size] 填充到同样大小的源语句
:param tag: tag = [tag len, batch size] 填充到同样大小的目标语句
:param teacher_forcing_ratio: 使用teacher forcing的概率
:return:
"""
batch_size = tag.shape[1]
tag_len = tag.shape[0]
tag_vocab_size = self.decoder.output_dim
# 存储编码器预测输出 (目标语句的单词数, batch_size, 目标词汇表大小)
outputs = torch.zeros(tag_len, batch_size, tag_vocab_size).to(self.device)
# 编码器对源语句进行编码, 获取hidden, cell state 作为 context vector来初始化解码器的hidden, cell state
hidden, cell = self.encoder(src)
# 第一个输入解码器的为语句开始的标志 <sos>
x = tag[0, :]
# 根据目标语句的大小, 循环方式调用解码器, 每次解码一个词
for t in range(1, tag_len):
# 插入token, 前一个时间步的 hidden, cell states,
# 输出预测, hidden, cell states
output, hidden, cell = self.decoder(x, hidden, cell)
# 保存预测输出
outputs[t] = output
# 决定是否使用 teacher forcing
teacher_force = random.random() < teacher_forcing_ratio
# 获取当前预测的最高概率的token
top1 = output.argmax(1)
# 如果使用 teacher forcing, 使用实际的下一个词作为输入, 否则使用预测的作为下一个输入
x = tag[t] if teacher_force else top1
return outputs
注意: 解码器循环从1开始, 输出 outputs[0] 为0, 输入输出个数如下:
$$ tag= [<sos>, y_1, y_2, y_3, <eos>]$$ $$ outputs = [0, \hat y _1, \hat y _2, \hat y _3, <eos>]$$
<sos> 为语句开始标志, <eos> 为语句结束标志. 所以计算损失的时候忽略掉第一项.
初窥NLP告一段落, 数据加载以及训练就是一些小的细节了, 具体移步原链接.
