
Seq2Seq模型: 从理论到实践(二)
本文图片、代码来源于pytorch-se12seq, 加深个人理解
在上文中使用的编码器-解码器结构如下:
(一)信息压缩问题
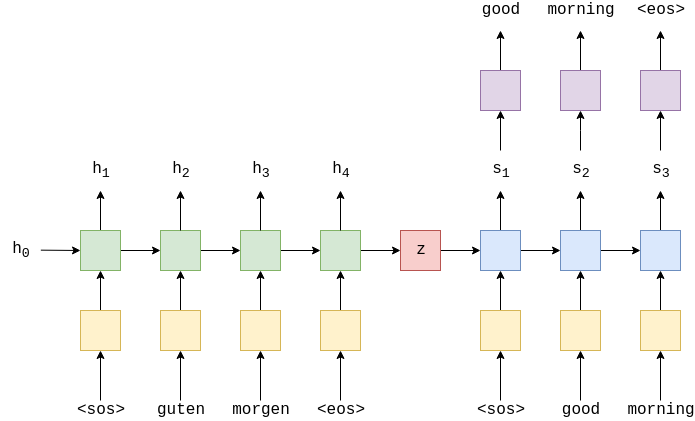
对于上诉的解码器而言, 只有第一个时间步时使用的是初始的 context vector, 对之后时间步的解码完全依赖于上一个时间步的隐状态, 这存在信息压缩, 我们希望每一个时间步都能从原始的context vector中提取信息.
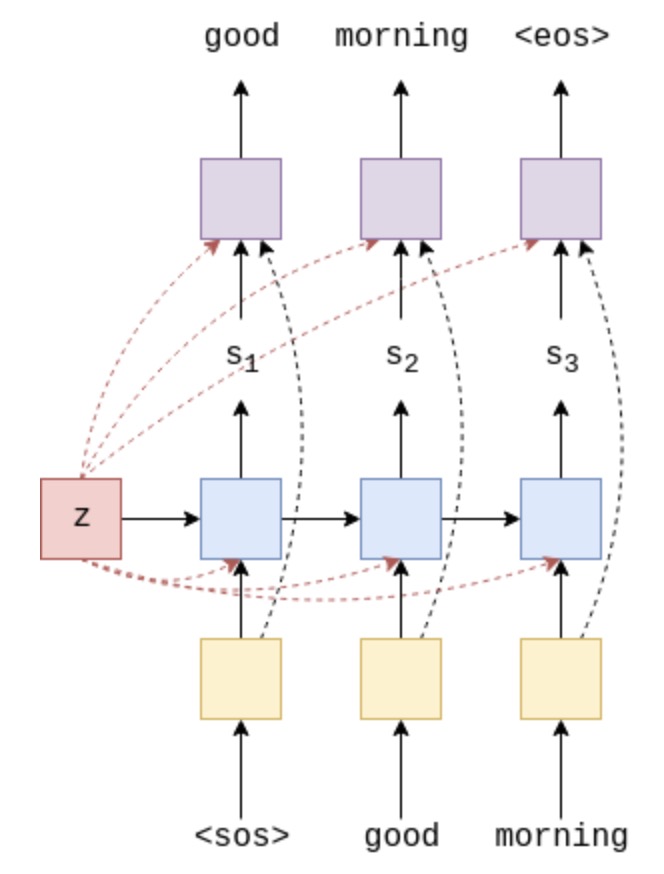
新的解码器结构如上图, 每一个时间步, context vector与embedding vector一起输入RNN结构中, 同时最终的分类层输入为当前的隐状态、embedding vector和 context vector.
采用GRU作为RNN单元实现的Decoder如下:
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, dropout):
"""
:param output_dim: 目标词汇表的大小
:param emb_dim: 词向量大小
:param hid_dim: GRU 隐层神经元个数
:param dropout:
"""
super().__init__()
self.hid_dim = hid_dim
self.output_dim = output_dim
self.embedding = nn.Embedding(output_dim, emb_dim)
# context vector 与 hid_dim 大小一样
# GRU 的输入为 concat [context vector, embedding vector]
self.rnn = nn.GRU(emb_dim + hid_dim, hid_dim)
# 分类层输入为 concat [context vector, embedding vector, hidden dim]
self.fc_out = nn.Linear(emb_dim + hid_dim * 2, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x, hidden, context):
"""
:param x: [batch_size]
:param hidden:
:param context:
:return:
"""
# x = [1, batch size]
x = x.unsqueeze(0)
# 目标token embedding
# embedded = [1, batch size, emb dim]
embedded = self.dropout(self.embedding(x))
# 将embed vector 与 context concat
# emb_con = [1, batch size, emb dim + hid dim]
emb_con = torch.cat((embedded, context), dim = 2)
# GRU 输出
output, hidden = self.rnn(emb_con, hidden)
# cat 当前的隐状态、embedding vector和 context vector
# output = [batch size, emb dim + hid dim * 2]
output = torch.cat((embedded.squeeze(0), hidden.squeeze(0), context.squeeze(0)),
dim = 1)
# 分类
# prediction = [batch size, output dim]
prediction = self.fc_out(output)
return prediction, hidden
(二) Attention seq2seq
上面的模型在一定程度上解决了信息压缩的问题, 存在的问题是:在将输入句子编码为定长的向量后,每次解码时使用context vector,而context vector 中每个词的权重一样。比如对于翻译而言,输出的一个词往往对应于输出的一个或多个词,每次都用整个语句是不合理的。因此,attention的思想就是对源语句的每个词在每次解码时赋予不同的权重,权重越大,贡献越大.
在翻译中的实现: 参照3 - Neural Machine Translation by Jointly Learning to Align and Translate
使用GRU为解码器,解码器 t-1 时间步的hidden state 为,$s _{t-1}$,编码器在整个序列上的 $h_t$ 构成的 $H$. (LSTM、GRU 返回值详见源码, 简单说第一项为每个时间步的hidden state, 第二项为最后一个时间步的hidden state). 解码的每一个时间步,attention 层输出一个attention vector $a _t$,$a_t$中每一个元素值在0-1之间,且 $sum(a_t)=1$.
直观地说,attention层利用我们迄今为止解码的内容 $s _{t-1}$,以及所有我们已经编码的内容 $H$,产生一个向量 $a _t$,代表源语句中我们最应该注意的单词,以便正确预测下一个要解码的单词。
$$a_t=attn(s _{t-1}, H)$$
这可以被认为是计算每个编码器隐藏状态“匹配”上一个解码器隐藏状态的程度。图示如下, 计算第一个attention vector, 由编码器在整个序列上的hidden state 和解码器的 $s_0 =z$计算attention vector $a_t$
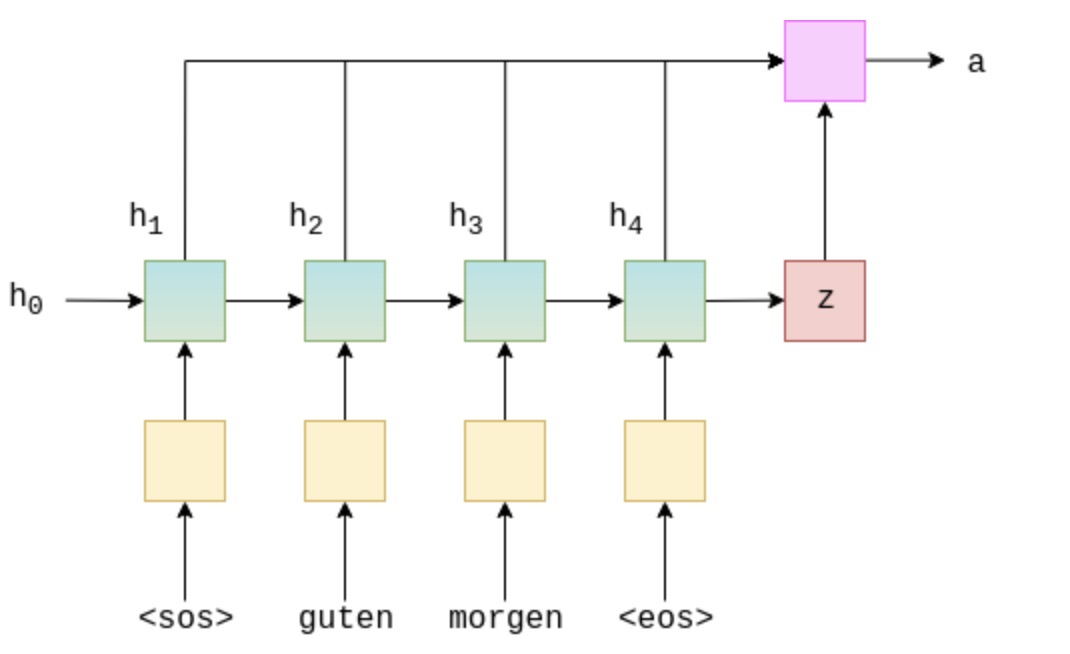
那么 seq2seq 模型结构为:
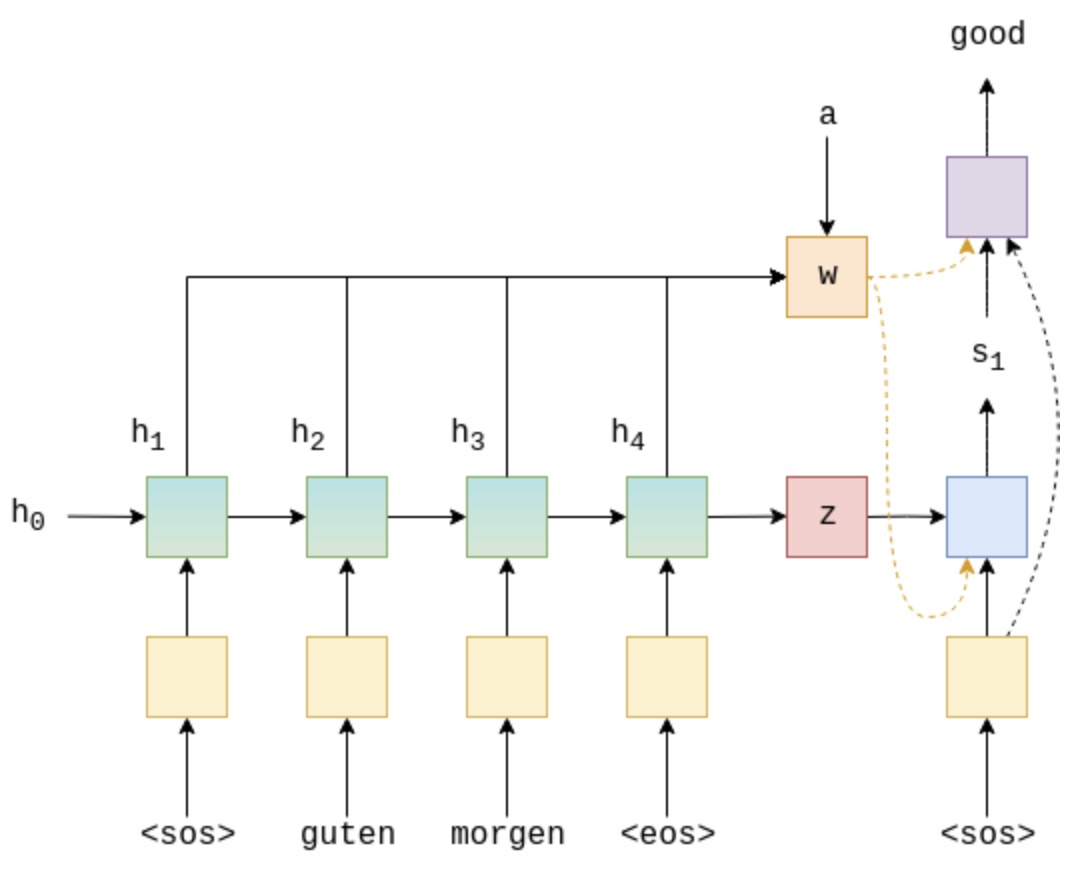
梳理带 attention 的seq2seq流程:
- 编码器部分对输入序列进行编码,输出每个时间步的hidden state作为attention 需要的输入和最后一个时间步的状态作为context vector
- 解码器的每一个时间步, 首先根据上一个时间步得到的hidden state 和编码器所有的hidden state $W$ 得到attention的权值,将 $W$ 加权后和embedded vector输入解码器.
对于seq2seq 模型的attention模型可按以下图理解:
在解码阶段,每一次都会根据当前的hidden state 与输入序列的所有hidden state计算attention值,本质是为了得到当前的hidden state 与输入序列哪些最相关,即 $ s _{t-1} $ 为一个query,去源语句的hidden state 中去查找哪些与它最相关,key, value 是编码器每一个时间步的hidden state,使用 query与每个key计算匹配度,再乘以value,即得到加权的value–attention
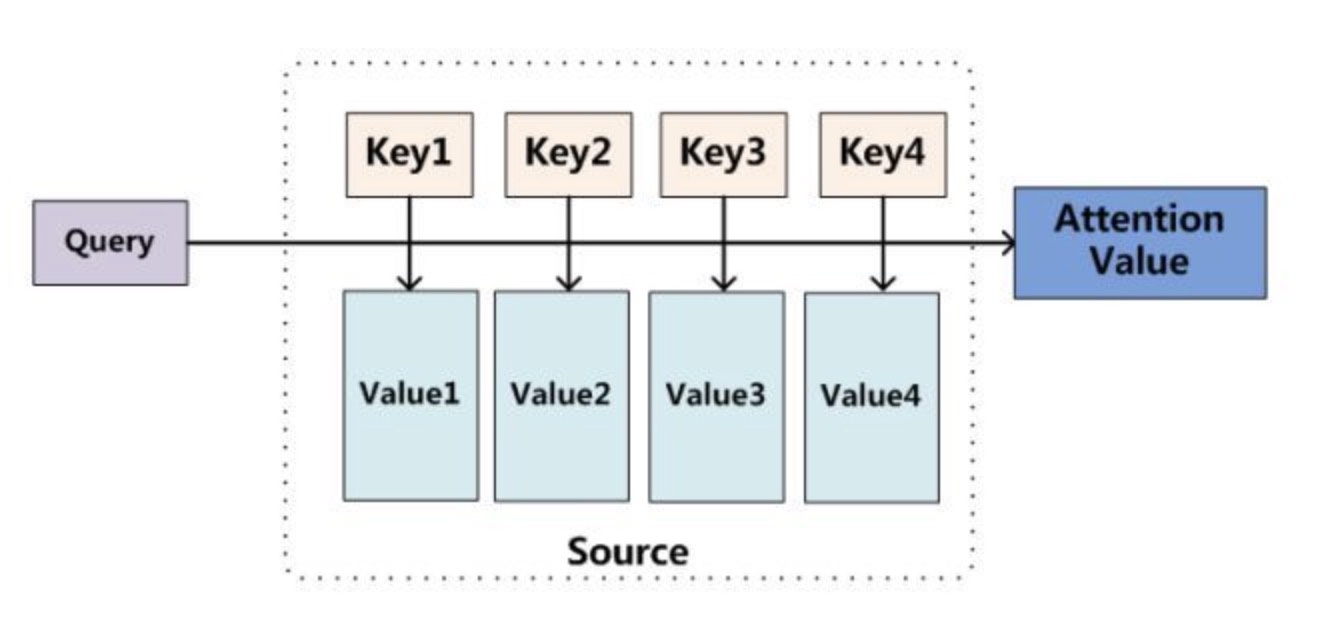
模型通过Q和K的匹配计算出权重,再结合V得到输出, attention 可表示为下式:
$$Attention(Q,K,V)=softmax(match(Q,K)) * V$$
