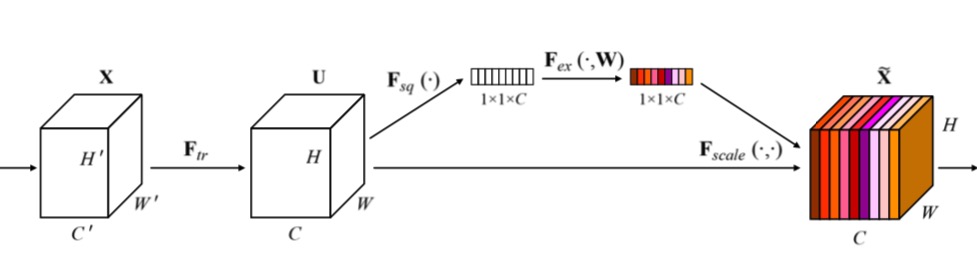
Squeeze-and-Excitation Networks(SENet)是CVPR2018公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提

yolo-v1作为anchor free 的目标检测方法, 虽然已经较老,但深入理解其原理还是很有必要的. 对于个人而言, 完全从头实现目标检测算法是必不可
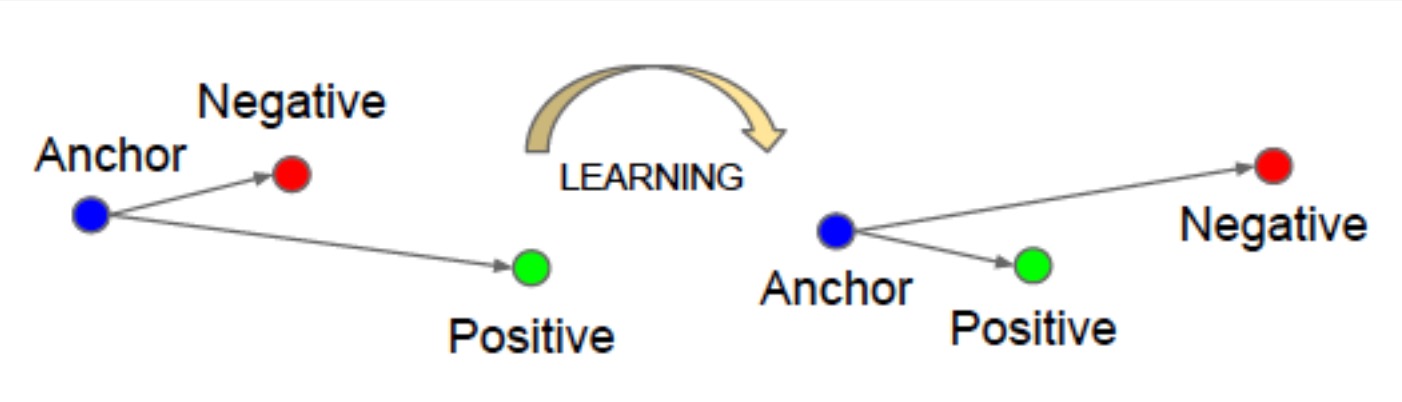
主要创新点 FaceNet 将 face verification(判断是否是同一个人),recognition(判断是何人)和clustering(寻找相似人脸) 任
DCGAN 在 Ian Goodfellow 提出GAN 以来, 在图像领域GAN 可谓被玩的声名大噪. DCAGN 主要是针对卷积实现GAN时, 提出一系列架构设计规则, 使其训练更稳定. 主要有以下
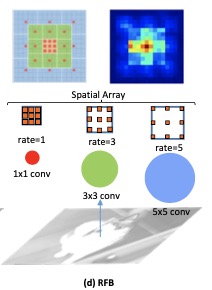
RFB 模块主要是针对在保持轻量级网络的速度快、计算量小的情况下, 提升检测的精度, 模块如其名, 从感受野角度入手, 增强轻量级网络的特征表示, 主要用来
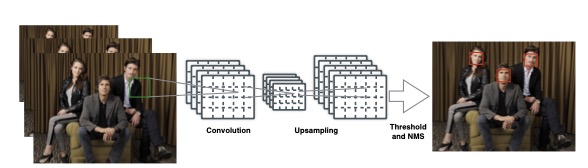
DenseBox 是与yolo, faster rcnn同期的目标检测网络, 与yolo v1一样采用 anchor-free的思想, 网络结构采用FCN来实现目标检测 主要创新点

Dlib由C++编写,提供了和机器学习、数值计算、图模型算法、图像处理等领域相关的一系列功能, 对Python 也提供了便利的接口, 但C++ 版功
目标检测主要有两种实现,一是faster-rcnn为代表的proposal two-stage 系列,二是以YOLO为代表的one-stage 的回归网络. 主要区
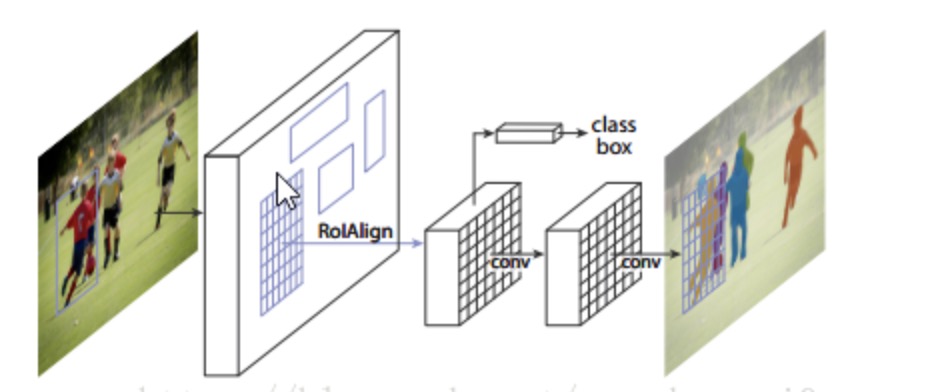
coursera deeplearning.ai目标检测课后实践,构建一个简化版单目标yolo目标检测并添加前景对象分割分支 网络结构 MASK-Rcnn主要是
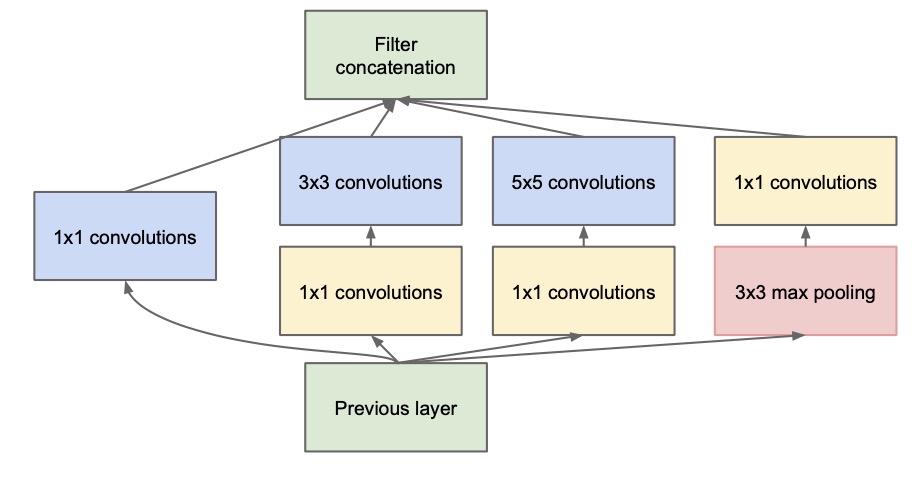
对卷积神经网络而言,提升网络的深度与宽度能够显著提升网络的性能,但是网络越大意味着参数量的增加,会使网络更加容易过拟合。同时,增加网络的大小
