
Keras多标签分类网络实现
简谈多分类与多标签分类
简单的说,输入一张图片进行分类: * 这张图片里面的物体(通常认为只有一个物体)属于某一个类,各个类别之间的概率是竞争关系,取最高概率标签为物体的类别。所以,多分类最后的激活为softmax函数。 * 实际情况下,一个图片只能有一个物体未免太限制了,能不能一次性判断出图片里面多个物体,比如既有人又有车,网络输出含有每个物体的概率,其概率是非竞争的,这就是多标签分类。
数据准备
我自己做的是一个8标签的分类,当然了一张图片里面最多也就同时包含4个左右的物体
数据目录如下:
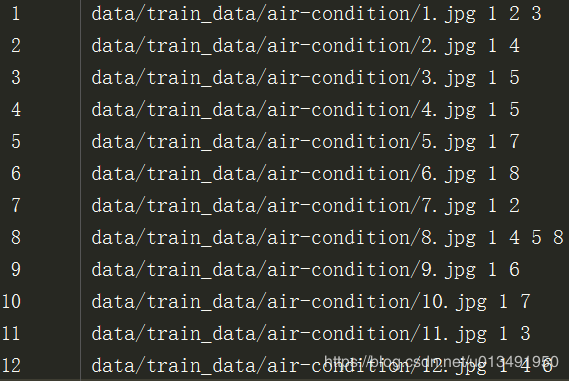
 按以下格式写的data_train.txt,我是从txt中读取图片路径加载训练图片的
按以下格式写的data_train.txt,我是从txt中读取图片路径加载训练图片的
数据生成
我没有使用ImageDataGenerator,使用生成器从txt中加载图像。一共有8各类,标签为1x8的向量,图片中包含某个物体,向量对于位置置1。如一张图中包含id为2,5,7三个物体,标签为[0,1,0,0,1,0,1,0]
data_gen.py
import os
import numpy as np
from PIL import Image
def to_multi_label(num_list, num_class):
lab = np.zeros(shape=(1,num_class))
for i in num_list:
lab[0,int(i)-1] = 1
return lab
def generate_arrays_from_txt(path, batch_size, num_class):
with open(path) as f:
while True:
imgs = []
labs = np.zeros(shape=(batch_size,num_class))
i= 0
while len(imgs) < batch_size:
line = f.readline()
if not line:
f.seek(0)
line = f.readline()
img_path = line.split(' ')[0]
lab = line.strip().split(' ')[1:]
img = np.array(Image.open(os.path.join('./', img_path)))
lab = to_multi_label(lab,num_class)
imgs.append(img)
labs[i] = lab
i = i + 1
yield (np.array(imgs),labs)
网络结构
我采用的是比较简单的Vgg-16网络。主要在于最后的激活函数,不能用softmax,使用sigmoid激活相当于对每个类别进行二分类,只是网络在同时进行多个二分类。
model.py
from keras.models import Sequential
from keras.layers import Dense, MaxPooling2D, Flatten, Convolution2D, Dropout, GlobalAveragePooling2D
def vgg_16(num_class, weights_path=None, has_fc=True):
model = Sequential()
model.add(Convolution2D(64, (3, 3), activation='relu', padding='same', input_shape=(224, 224, 3)))
model.add(Convolution2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Convolution2D(128, (3, 3), activation='relu', padding='same'))
model.add(Convolution2D(128, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Convolution2D(256, (3, 3), activation='relu', padding='same'))
model.add(Convolution2D(256, (3, 3), activation='relu', padding='same'))
model.add(Convolution2D(256, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Convolution2D(512, (3, 3), activation='relu', padding='same'))
model.add(Convolution2D(512, (3, 3), activation='relu', padding='same'))
model.add(Convolution2D(512, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
model.add(Convolution2D(512, (3, 3), activation='relu', padding='same'))
model.add(Convolution2D(512, (3, 3), activation='relu', padding='same'))
model.add(Convolution2D(512, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), strides=(2, 2)))
if weights_path:
model.load_weights(weights_path)
if has_fc:
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(100, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_class, activation='sigmoid'))
else:
model.add(GlobalAveragePooling2D())
model.add(Dense(num_class, activation='sigmoid'))
# model.summary()
return model
训练模型
损失函数为binary_crossentropy,就是计算输出与标签各个对应位置的损失,有点像图像分割。然后就可以跑起来了,看效果调参什么的。我调了好一些,0.85左右就上不去了,估计还是得换网络结构吧
from model import vgg_16
from data_gen import generate_arrays_from_txt
from keras.optimizers import SGD
from keras.callbacks import TensorBoard
from keras.callbacks import ModelCheckpoint
import os
train_data_gen = generate_arrays_from_txt('./data/train_data/data_train.txt', 32, 8)
valid_data_gen = generate_arrays_from_txt('./data/valid_data/data_valid.txt', 32, 8)
model = vgg_16( 8,'./model/vgg_16_without_fc.h5')
sgd = SGD(lr=1e-6, momentum=0.9, decay=1e-6, nesterov=True)
model.compile(optimizer=sgd, loss='binary_crossentropy', metrics=['accuracy'])
tensor_board = TensorBoard(log_dir='log/ecpo1')
ckpt = ModelCheckpoint(os.path.join('./model/ecpo1', 'vgg.h5'), verbose=1, period=1)
model.fit_generator(train_data_gen, steps_per_epoch=100, epochs=50, verbose=1, callbacks=[tensor_board, ckpt],
validation_data=valid_data_gen, validation_steps=5)
不得不说,keras真是我这种懒人喜欢用库啊,♪(・ω・)ノ 如果文中有说错的地方,还请指出,谢谢
