
Keras数据集加载小结
对于keras加载训练数据,官方上没有详说。然而网上查各种资料,写法太多,通过自己跑代码测试总结以下几条,方便自己以后使用。
总的来说keras模型加载数据主要有三种方式:.fit(), .fit_generator()和.train_on_batch()。
1.fit():
上函数,各个参数的意义就不解释了
fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None)
从官方文档中可以看出,fit()是需要先把整个数据集加载进来,然后喂入网络,因为minist数据集比较小,这么做是可行的,但对于实际开发而言,这么做是不可行的,需要大量的内存资源,同时不能对数据进行在线提升。
一次性加载整个数据集的示例代码:
任务为猫和狗的二分类,train_data下包含cat和dog两个文件夹,代码将两个文件夹下图片和标签存入numpy数组,返回为训练数据和训练标签。
def load_data():
tran_imags = []
labels = []
seq_names = ['cat','dog']
for seq_name in seq_names:
frames = sorted(os.listdir(os.path.join(root_path,'data','train_data', seq_name)))
for frame in frames:
imgs = [os.path.join(root_path, 'data', 'train_data', seq_name, frame)]
imgs = np.array(Image.open(imgs[0]))
tran_imags.append(imgs)
if seq_name=='cat':
labels.append(0)
else:
labels.append(1)
return np.array(tran_imags), np.array(labels)
##
train_data,train_labs = load_data()
model.fit(train_data,keras.utils.to_categorical(train_labs),batch_size=32,epochs=50,verbose=1)
2.fit_generator()
fit_generator()需要将数据集和标签写成生成器格式
fit_generator(generator, steps_per_epoch=None, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=False, shuffle=True, initial_epoch=0)
1).从txt文件读取图片路径的生成器,不进行数据增强
以下代码从给定路径的txt文本中循环读取图片路径,每次读取一个batch_size的图片,并存入numpy数组返回。其中,当读到文本末尾时,将指针指向文件第一行。
def generate_array_from_txt(path, batch_size,num_class):
with open(path) as f:
while True:
imgs = []
labs = np.zeros(shape=(batch_size,num_class))
i = 0
while len(imgs) < batch_size:
line = f.readline()
if not line:
f.seek(0)
line = f.readline()
img_path = line.split(' ')[0]
lab = line.split(' ')[1]
img = np.array(Image.open(os.path.join('./',img_path)))
lab = keras.utils.to_categorical(int(lab)-1,num_classes=num_class)
imgs.append(img)
labs[i] = lab
i = i +1
yield (np.array(imgs),labs)
##使用如下
gen = generate_arrays_from_txt(txt_path,batch_size,num_class)
model.fit_generator(gen,steps_per_epoch=N, epochs=EPOCN)
## 因为生成器是无限生成数据,所以它不知道一轮要训练多少图片,所以steps_per_epoch为数据集的总数除以batch_size。
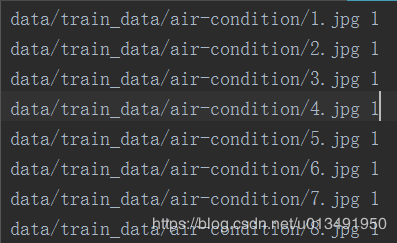
我的txt文本格式如下:前面是图片路径,后面是类别标签,因为从1开始的,所以to_categorical 里面减了1.
2).使用.flow_from_directory(directory)
使用ImageDataGenerator类,ImageDataGenerator类有.flow()与.flow_from_directory(directory)两个加载数据的方法,个人认为第一个偏向于先将数据全部加载(看过的示例代码都是这样的),第二个从图片目录利用生成器返回数据。
2.1 用于分类网络,返回图像以及标签
## 声明一个ImageDataGenerator类对象,并给出你需要进行的数据增强选项
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
##调用.flow_from_director()方法,第一个为数据集路径。生成数据集及标签
train_generator = train_datagen.flow_from_directory(
'./data/train_data',
target_size=(224, 224),
batch_size=32,
class_mode='categorical')
##
model.fit_generator(train_generator,steps_per_epoch=N, epochs=EPOCH)
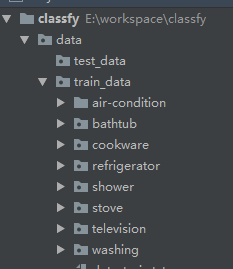
我的数据集目录结构如下:
2.2 用于pix2pix
当用于图像分割、超分辨率重建等需要像素对应像素的任务时,标签也为图片(单通道或多通道)。 示例:加载用于图像分割的图像与mask,mask为单通道灰度图像,目标为白色,其余背景为黑色。
# 分别定义两个ImageDataGenerator对象
image_datagen = ImageDataGenerator(featurewise_center=True,
featurewise_std_normalization=True,
rescale= 1./255)
mask_datagen = ImageDataGenerator(rescale= 1./255)
seed = 1
#训练图片路径
image_generator = image_datagen.flow_from_directory(
'data/data_seg/davis_train',
class_mode=None,
seed=seed)
# 指定mask
mask_generator = mask_datagen.flow_from_directory(
'data/data_seg/davis_label',
class_mode=None,
color_mode = 'grayscale'
seed=seed)
# 将以上两个生成器合为一个
train_generator = zip(image_generator, mask_generator)
#
model.fit_generator(
train_generator,
steps_per_epoch=STEPS_NUM,
epochs=EPOCHS)
对于标签为图像的数据,当用这种方式加载的时候,需将class_mode指定为None,表示不返回标签。对于训练图片和标签要保证顺序不变,一一对应,名字可不同


需要将两个生成器的seed指定为相同的数字,此时两个生成器返回的图片对就一一对应
3) 使用flow(x, y=None)
使用.flow()时,需要将训练数据加载到内存中,每次填充一个Batch_size的数据进网络
train_data, train_labs = load_data()
dataGenerator = ImageDataGenerator(
preprocessing_function=normalize)
gen = dataGenerator.flow(train_data, train_labs, batch_size=8)
model.fit_generator(gen)
4) 使用.flow_from_dataframe()
dataframe中保存的是图片名字和label
import pandas as pd
df=pd.read_csv(r".\train.csv")
datagen=ImageDataGenerator(rescale=1./255)
train_generator=datagen.flow_from_dataframe(dataframe=df, directory=".\train_imgs", x_col="id", y_col="label", class_mode="categorical", target_size=(32,32), batch_size=32)
3.train_on_batch()
类似于TensorFlow的数据填充了,一次喂一个batch_size的数据。
train_on_batch(x, y, sample_weight=None, class_weight=None)
采用2.2中的生成器例子
train_generator = zip(image_generator, mask_generator)
steps = len(train_generator)/ batch_size * EPOCH
step = 0
for train_batch, label_batch in train_generator:
if step == steps:
break
step += 1
train_on_batch(train_batch, label_batch, sample_weight=None, class_weight=None)
4.对生成器返回数据进行处理
使用生成器时,如果需要对图片进行一定的处理,可以在ImageDataGenerator中定义预处理函数,但是要求返回的shape不能改变。 如果要对图片的shape进行改变,可将生成器返回结果再次包装为生成器,如下例:
# 实例化ImageDataGenerator,同时指定预处理函数
datagen = ImageDataGenerator(
preprocessing_function=normalize)
# 定义生成器,每次从datagen中取出一个Batch,然后对数据进行自己的操作
def image_a_b_gen(data_path):
for batch in datagen.flow_from_directory(data_path,
target_size=(768, 1024),
color_mode='rgb',
class_mode=None,
batch_size=batch_size,
shuffle=True):
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:, :, :, 0]
Y_batch = lab_batch[:, :, :, 1:] / 128
yield (np.expand_dims(X_batch, axis=3), Y_batch)
