
Image Caption模型
图像描述生成作为结合CV与NLP的跨模态学习任务, 在人工智能领域也是热门的研究点.
模型
Image caption 是在给定照片的情况下生成人类可读的文字描述的具有挑战性的人工智能问题, 它既需要计算机视觉领域的图像理解,又需要自然语言处理领域的语言模型。
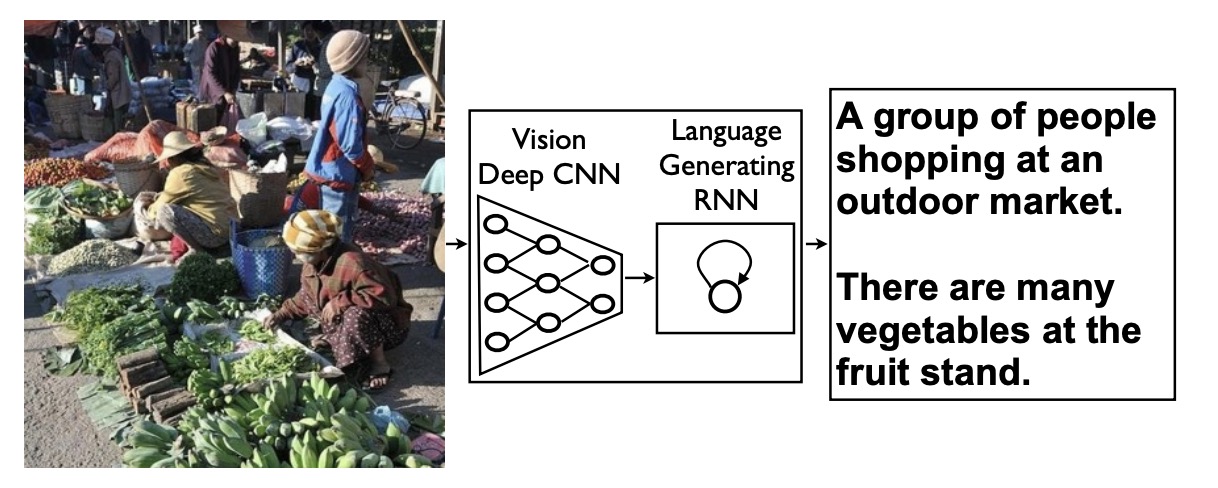
如上图,直观思路是对输入图片使用CNN进行特征提取,然后使用语言模型进行解码生成文本描述.
其模型可分为以下三种(参考自Jason Brownlee):
模型一
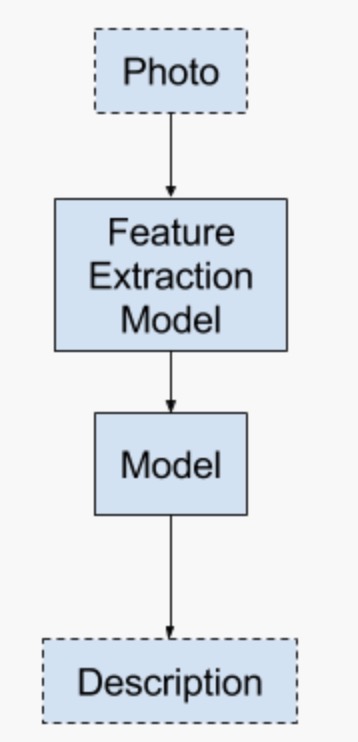
这种模型希望直接生成整个文本序列, 即预测序列中每个单词在整个词汇上的概率分布,同时生成的单词没有顺序性.
模型二
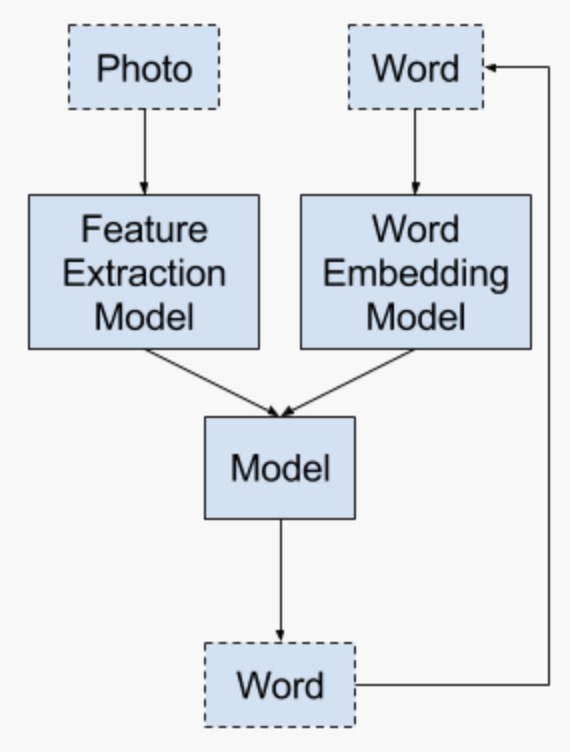
这种模型其实就是seq2seq模型, 编码器为CNN,解码器采用RNN及其变种,每一个时间步预测一个单词。
模型三
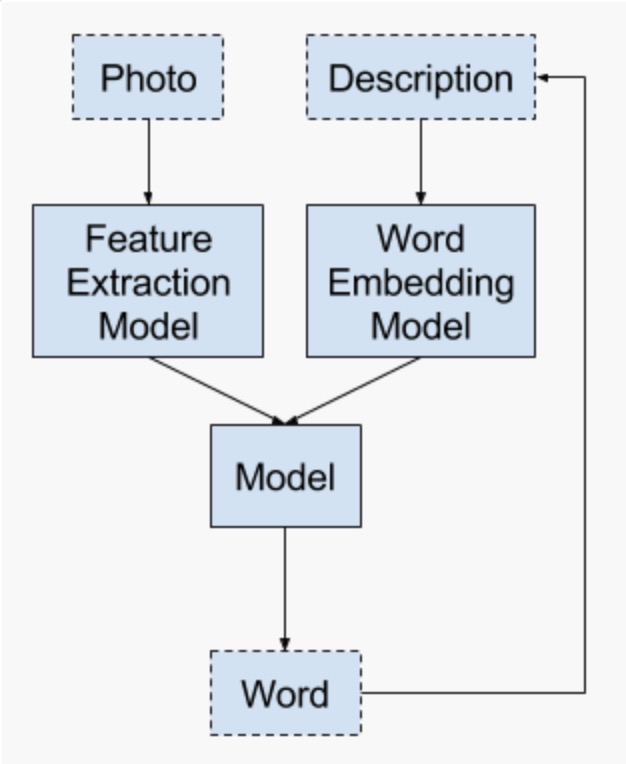
模型三与模型二的区别在于,模型三使用生成的序列构造embedding 向量去预测下一个token,模型二只用当前时间步的去预测下一个token.
毫无疑问,直观上来说模型三是首选模型.
