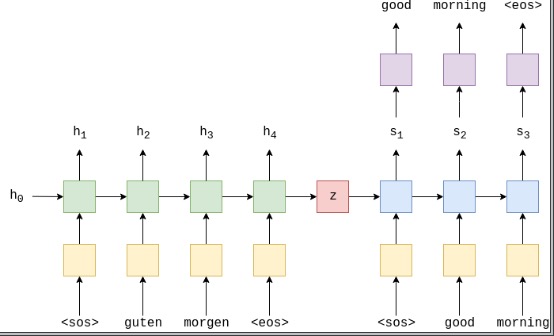
理论结合实践是学习的最佳方式, 本文图片、代码来源于pytorch-seq2seq Seq2Seq 模型 对于序列预测, RNN及其变种LSTM、GRU等无疑是最

最近开始深入OCR这块, 以前倒是训练过开源的Keras-CRNN, 但是它和原文还是不一样, 今天参照Keras-CRNN代码和CRNN论文用p
今天被问到了OCR相关的NMS,个人一直偏向于通用目标检测的NMS,正好补补课,扩展一下OCR方向的知识. 对通用目标检测或者人脸检测等得到的
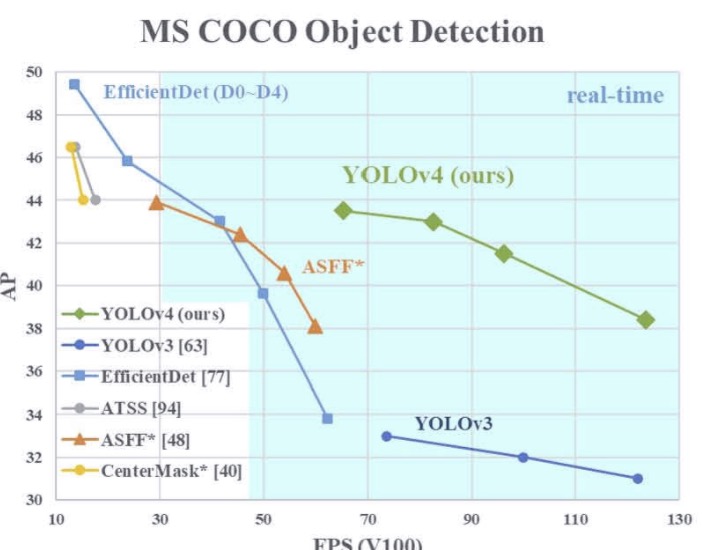
最近目标检测又出了yolo-v4,作为一个做目标检测的不可不膜拜膜拜。首先由于约瑟夫大神已经退出CV,yolo-v4 的一作是DarkNet的
在目标检测中, IOU 可以被用来评估预测框的性能,IOU越大预测框越准。IOU可表示两个框的距离,IOU越大距离越小. 对于目标检测坐标损失虽然一般
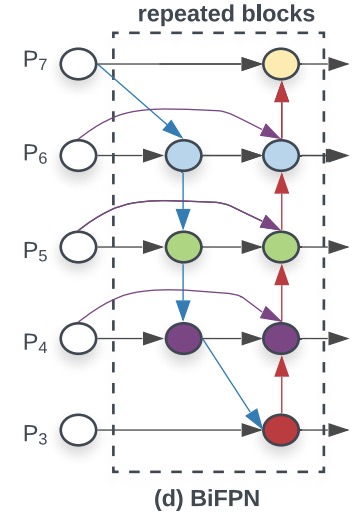
最近谷歌放出了 EfficientDet 论文与代码, 在COCO上取得了最好的MAP, 本文对 efficientDet 做个简要的总结, 同时对efficientNet也做个回顾. Efficie

看了Jason Brownlee博士的Keras CBIR demo, 自己也动手用pytorch写一个. CBIR CBIR 为基于内容的图像检索. 用于在图像数据数据库上检索具有

对于图像超分辨率重建, 第一个使用CNN实现的是SRCNN, 类似于编码器解码器结构. SRGAN是第一个使用GAN网络解决超分辨率重构的网络 创新
说到语义分割, 不得不说一下U-net, U-net首先针对于医学图像分割提出, 由于其卓越的性能, 目前大部分医学图像分割都是基于U-net或者U
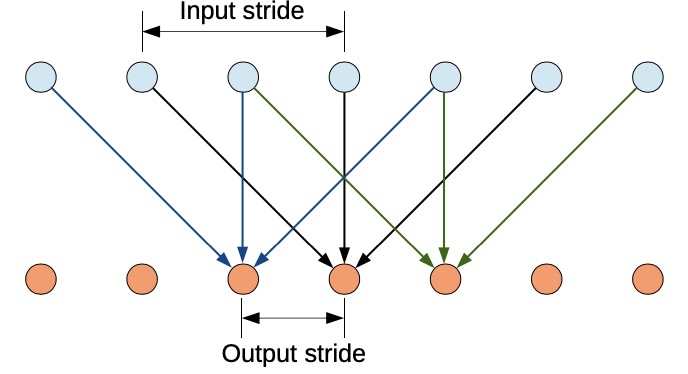
deeplab 为一个系列, 因此将其放在一起进行个回顾 Deeplab-v1 与deeplab-v2 将deeplab-v1与deeplab-v2放在一起, 主要是因为二者总体结构
