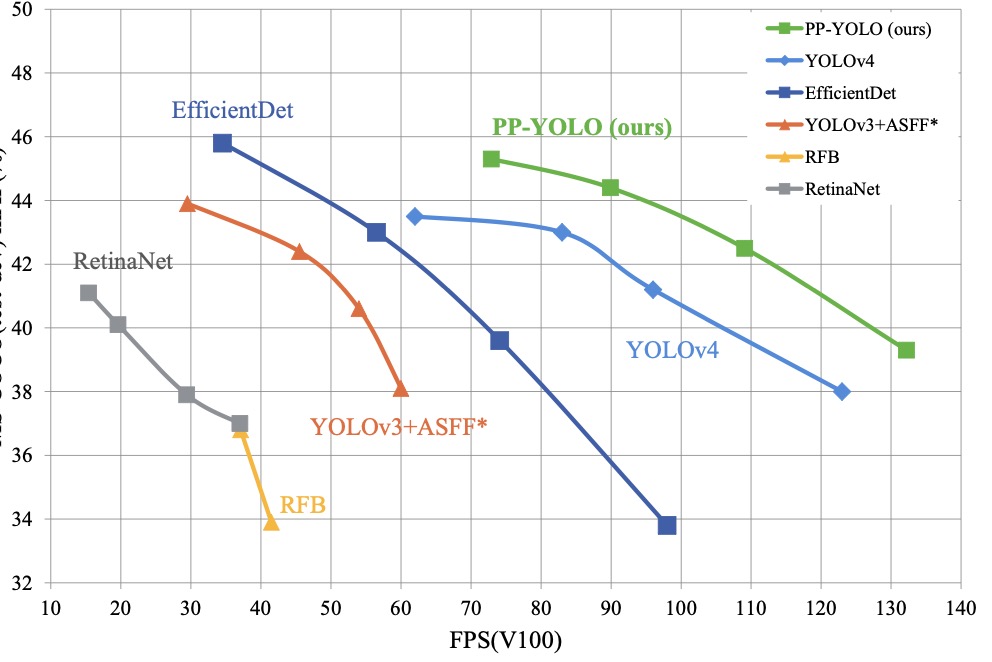
PP-YOLO 是百度在paddle-paddle框架下基于YOLOv3,结合各种trick得到的一个在性能与效率平衡的检测网络。与yolov4、effi
训练过很多目标检测网络,个人觉得yolov5是使用过的收敛最快的网络,训练10多个epoch就能达到很高的P、R. 收敛快的原因也不是网络本身

yolo-v5 非论文,仅工程实现。本文主要记录自己对yolo-v5代码的学习、理解,以及实际服务部署。 网络结构 yolo-v5 包含4种模型结构,分别是yolov5s、
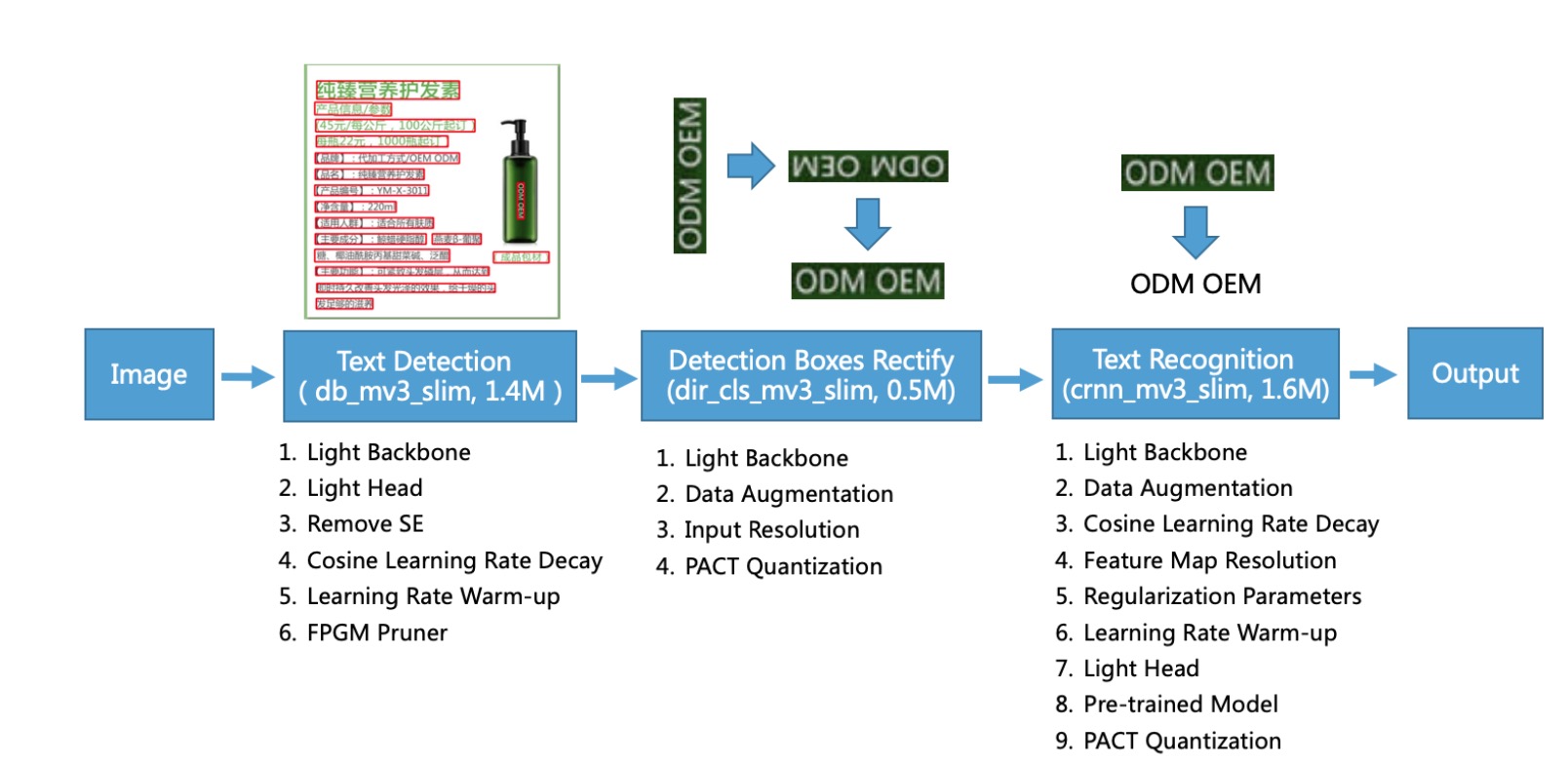
PP-OCR 是百度基于paddlePaddle 框架开源的国产高质量的OCR系统,PP-OCR 论文主要对其中使用的技术作了介绍。本文对PP-OCR 作阅读
对外提供网络接口服务,当单机容量达到极限时,可以从业务拆分和分布式部署两个方面进行分析,来解决接口访问量大,并发量高,海量数据的问题。从单机
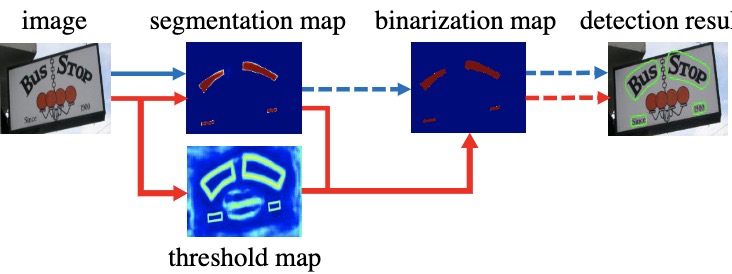
DBNet:Real-time Scene Text Detection with Differentiable Binarization,是一个基于分割的文本检测器,PPOCR中使用其作为检测器,取得了可观的效果
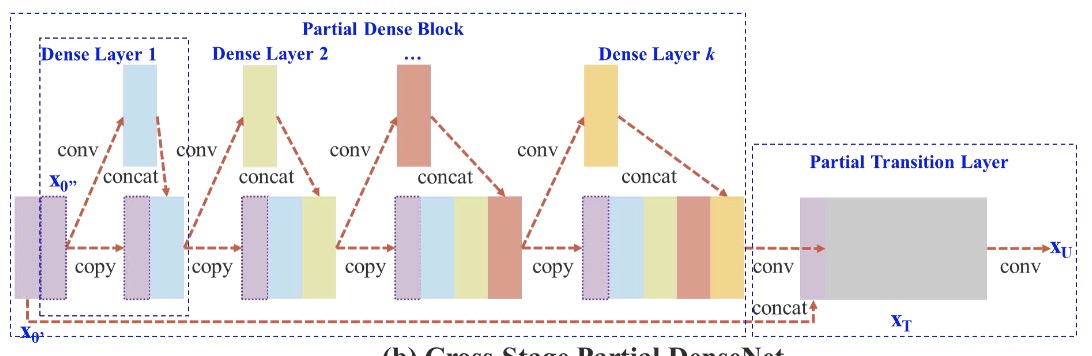
CSPNet出至论文:CSPNet: A New Backbone that can Enhance Learning Capability of CNN, 近来yolo-v4,yolo-v5都使用其作为主干网络的结构,其主要用于降低计算量的
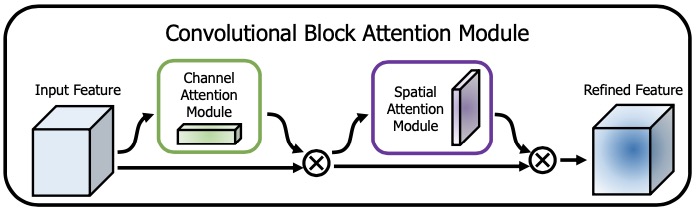
之前谈过SE-net, 对于目标检测或检测用于特征通道的attention, 今天记录一下CBAM模块, 对分类或检测中用来获取通道、空间位置的a
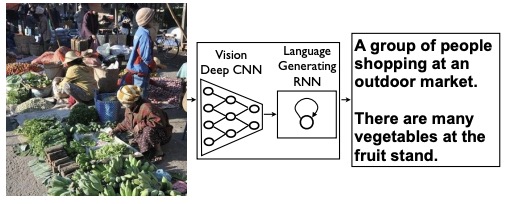
图像描述生成作为结合CV与NLP的跨模态学习任务, 在人工智能领域也是热门的研究点. 模型 Image caption 是在给定照片的情况下生成人类可读的文字描述的具有挑
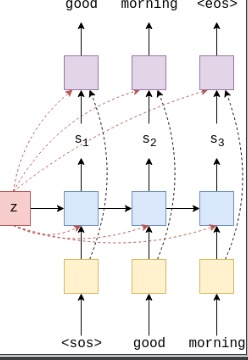
本文图片、代码来源于pytorch-se12seq, 加深个人理解 在上文中使用的编码器-解码器结构如下: (一)信息压缩问题 对于上诉的解码器而言
