
对于图像超分辨率重建, 第一个使用CNN实现的是SRCNN, 类似于编码器解码器结构. SRGAN是第一个使用GAN网络解决超分辨率重构的网络 创新
说到语义分割, 不得不说一下U-net, U-net首先针对于医学图像分割提出, 由于其卓越的性能, 目前大部分医学图像分割都是基于U-net或者U
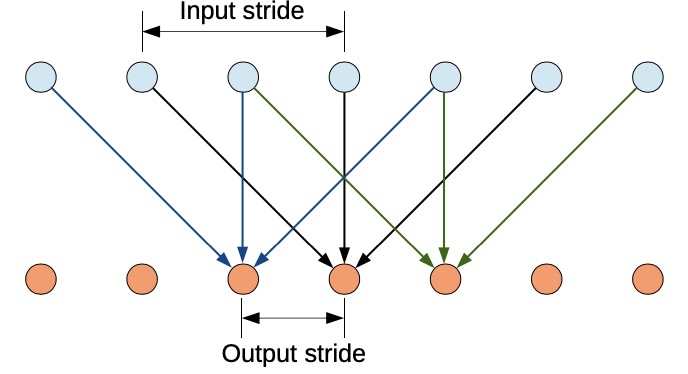
deeplab 为一个系列, 因此将其放在一起进行个回顾 Deeplab-v1 与deeplab-v2 将deeplab-v1与deeplab-v2放在一起, 主要是因为二者总体结构
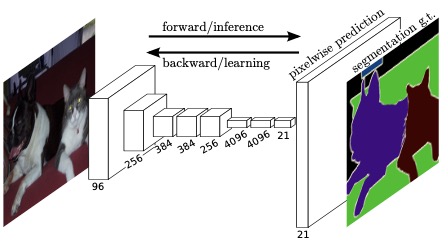
研究生阶段自己对分割这边还是很熟悉的, 工作后发现很多网络只能说出原理和整体框架, 面试时问的很细节, 再次将经典分割网络仔细review一遍. 主

之前做人脸检测使用的是retinaface做的, 刚好最近被问到MTCNN, 以前没有细看, 正好做个笔记. MTCNN是2015年提出的用于人脸检

主流的目标检测算法大多数是基于anchor box的, one-stage 的yolo-v2, yolo-v3, ssd…以及two-stage 的faster rcnn
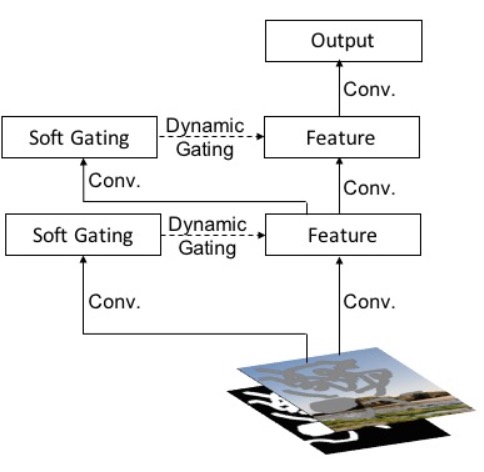
此文与图像修复2中review过的论文一样, 出至Adobe同一人之手. 主要创新点 提出门控卷积解决普通卷积将所有输入像素都视为有效像素的问题,
在目标检测中, 存在正负样本类别不平衡的现象, 特别是对于单阶段的目标检测算法. 如果每张训练图片中目标个数还很少的话, 背景区域就占了绝大部分, 分

最近闲暇时自己在pytorch实现并训练了yolo-v2, 对yolo-v2的实现做一个简单的总结, 主要是loss 层, 别的地方都没啥难度 关于y

该篇论文来源于Intel, 如其名用来加速目标检测. 主要针对于 one-stage 的目标检测算法. 主要创新点 对于 one-stage 的目标检测算法而言, 由于其设置了大量的 default box, 然后
