
动手搭建神经网络之:简单联合分割、检测网络
coursera deeplearning.ai目标检测课后实践,构建一个简化版单目标yolo目标检测并添加前景对象分割分支
网络结构
MASK-Rcnn主要是将目标分割、分类、以及定位融合在一起,其网络结构结构如下
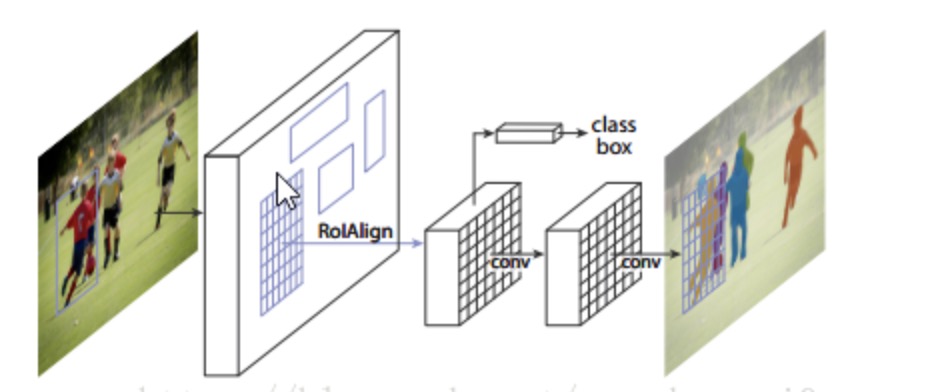
此小练习基于mask rcnn的思想,但直接进行box回归,因为是检测单一的前景目标,因此对应于yolo将图片视为一个cell,进行bounding box的回归,因为这个数据集中部分图片的前景目标包含了几个物体,分类分支无法收敛,因此删除了分类分支.
base model采用预训练的VGG16前5层卷积与池化层,对于分割分支,采用U_net结构恢复空间分辨率,对于回归分支,在VGG16最后一层池化层后添加卷基层与全局平均池化层实现.
网络结构图如下:
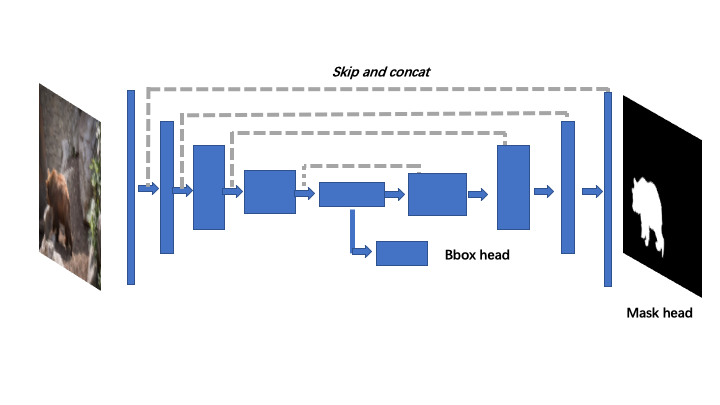
网络搭建
class JointNet:
def __init__(self):
self.input_img = Input(name='input_img',
shape=(512, 512, 3),
dtype='float32')
self.out_channel = 1
self.bbox = 4
vgg16 = VGG16(input_tensor=self.input_img,
weights='imagenet',
include_top=False)
self.vgg_pools = [vgg16.get_layer('block%d_pool' % i).output
for i in range(1, 6)]
def network(self):
def decoder(layer_input, skip_input, channel, last_block=False):
if not last_block:
concat = Concatenate(axis=-1)([layer_input, skip_input])
bn1 = BatchNormalization()(concat)
else:
bn1 = BatchNormalization()(layer_input)
conv_1 = Conv2D(channel, 1, activation='relu', padding='same')(bn1)
bn2 = BatchNormalization()(conv_1)
conv_2 = Conv2D(channel, 3, activation='relu', padding='same')(bn2)
return conv_2
d1 = decoder(UpSampling2D((2, 2))(self.vgg_pools[4]), self.vgg_pools[3], 128)
d2 = decoder(UpSampling2D((2, 2))(d1), self.vgg_pools[2], 64)
d3 = decoder(UpSampling2D((2, 2))(d2), self.vgg_pools[1], 32)
d4 = decoder(UpSampling2D((2, 2))(d3), self.vgg_pools[0], 32)
d5 = decoder(UpSampling2D((2, 2))(d4), None, 32, True)
# mask branch
mask = Conv2D(self.out_channel, 3, padding='same', name='mask')(d5)
# bbox branch
conv = Conv2D(512, (3, 3), padding='same', activation='relu', name='bbox_conv1')(self.vgg_pools[4])
conv_bbx = Conv2D(self.bbox, (3, 3), padding='same', activation='sigmoid',name='bbox_conv2')(conv)
bbox_head = GlobalAveragePooling2D(name='bbox_head')(conv_bbx)
model = Model(inputs=self.input_img, outputs=[mask, bbox_head])
model.summary()
return model
数据生成
训练数据选用了DAVIS2016视频目标分割数据集。对于bbox,采用VOC格式,代码生成左上角坐标及物体宽高,同时,基于yolo思想将单张图片视为单个cell,预测坐标的偏移值,将坐标值归一化,加快收敛,因为DAVIS2016中的一个mask往往包含多个类别,因此没有加分类分支。
网络训练
对于mask分支,采用二值交叉熵,对于bbox回归,采用smoothL1损失。联合训练时bbox分支一般收敛快,mask分支损失可能不下降,偏向于给mask分支更大的权重。本次实验中采用了分阶段训练,首先只训练mask分支,在网络具备分割能力后,冻结vgg16基网络,然后联合训练。
实验结果

