
谷歌Detic: 结合分类数据集进行目标检测模型训练
论文三连问
- 论文做了什么:使用分类数据集来训练检测模型的分类器,使检测器可以识别出上万的类别
- 论文怎么做的:对于检测标注格式的数据和分类标注格式的数据,使用不同形式的损失函数, 前者使用标准损失函数,后者使用作者改进的.
- 论文效果:在 open-vocabulary 数据集上,超过sota OVR-CNN等.
Detic

- 将检测标注数据和分类标注数据混合在一起来训练
- 对于检测格式的数据,按标准的two-stage 检测器训练过程训练,检测器使用的是two-stage 的检测器centernet2, 但是将第二阶段的分类器替换为CLIP的文本-图像编码器来进行 open-vocabulary 分类
- 对于分类标注格式(图片级标签)的数据,使用作者修改的损失函数来训练分类器
Classifier-only training with image labels
论文如何使用 image-label 的数据来训练详细如下:
对于一张给定的来至分类数据集的图片 I,具有 K 个类别,检测网络首先抽取 N 个 proposal区域,对于 proposal 区域由以下几种方式进行监督.
一: 将整张图片作为 一个proposal, 对应的bounding box 为 B=(0, 0, w, h)
损失为 L-image-box, 其中 W 为分类的weights,c 为该ROI对应的类别
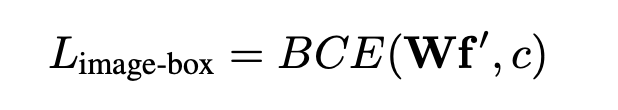
二: 实际上 image-box 可以使用更小的boxes替代,作者另外使用了两种,分别是最大前景目标置信度的proposal和最大尺寸proposal.
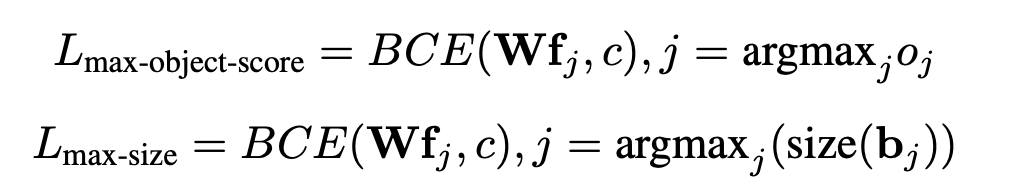
对于以上三种损失,max-size 效果最好,默认总体损失如下
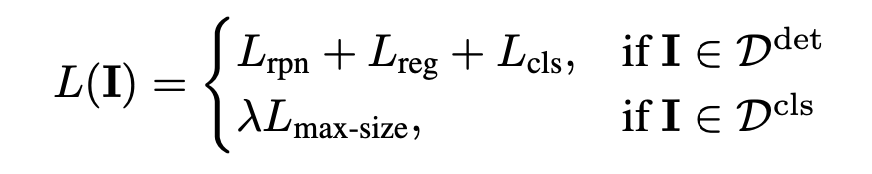
从损失看来针对分类数据的图片为单标签分类数据集, 多标签的不行. 有的弱监督使用的数据中会存在多个类别,弱监督方式主要在进行 region-label的匹配.
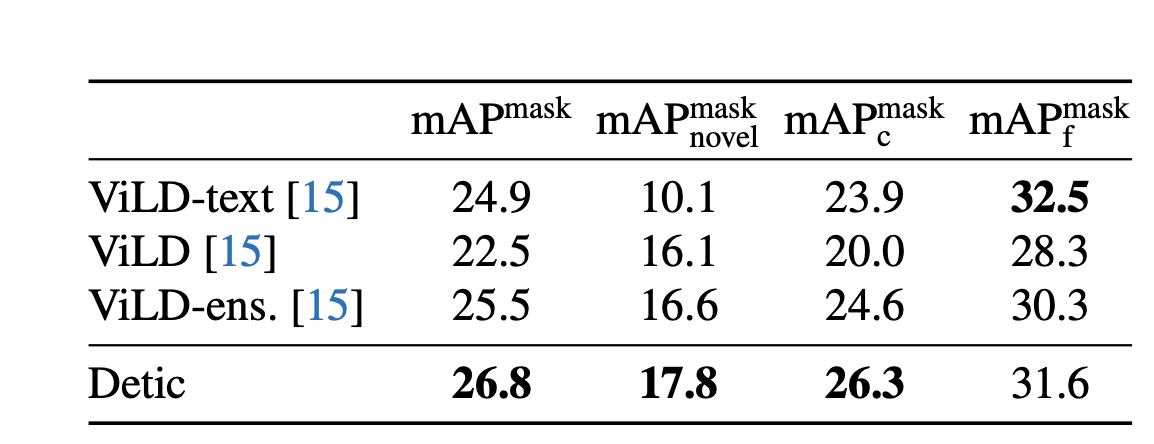
experiment
对比 ViLD

总结
本文主要在于如何使用分类数据来训练检测模型,使用的数据最好是单标签分类数据. 同时可以看出 zero-shot目标检测主要基于two-stage 目标检测构建, 接下来准备再复习一下目前主流的two-stage的检测器, 从论文到代码.
