
PP-Ocr阅读小结
PP-OCR 是百度基于paddlePaddle 框架开源的国产高质量的OCR系统,PP-OCR 论文主要对其中使用的技术作了介绍。本文对PP-OCR 作阅读总结, 顺便复习一下OCR相关知识.
OCR系统结构
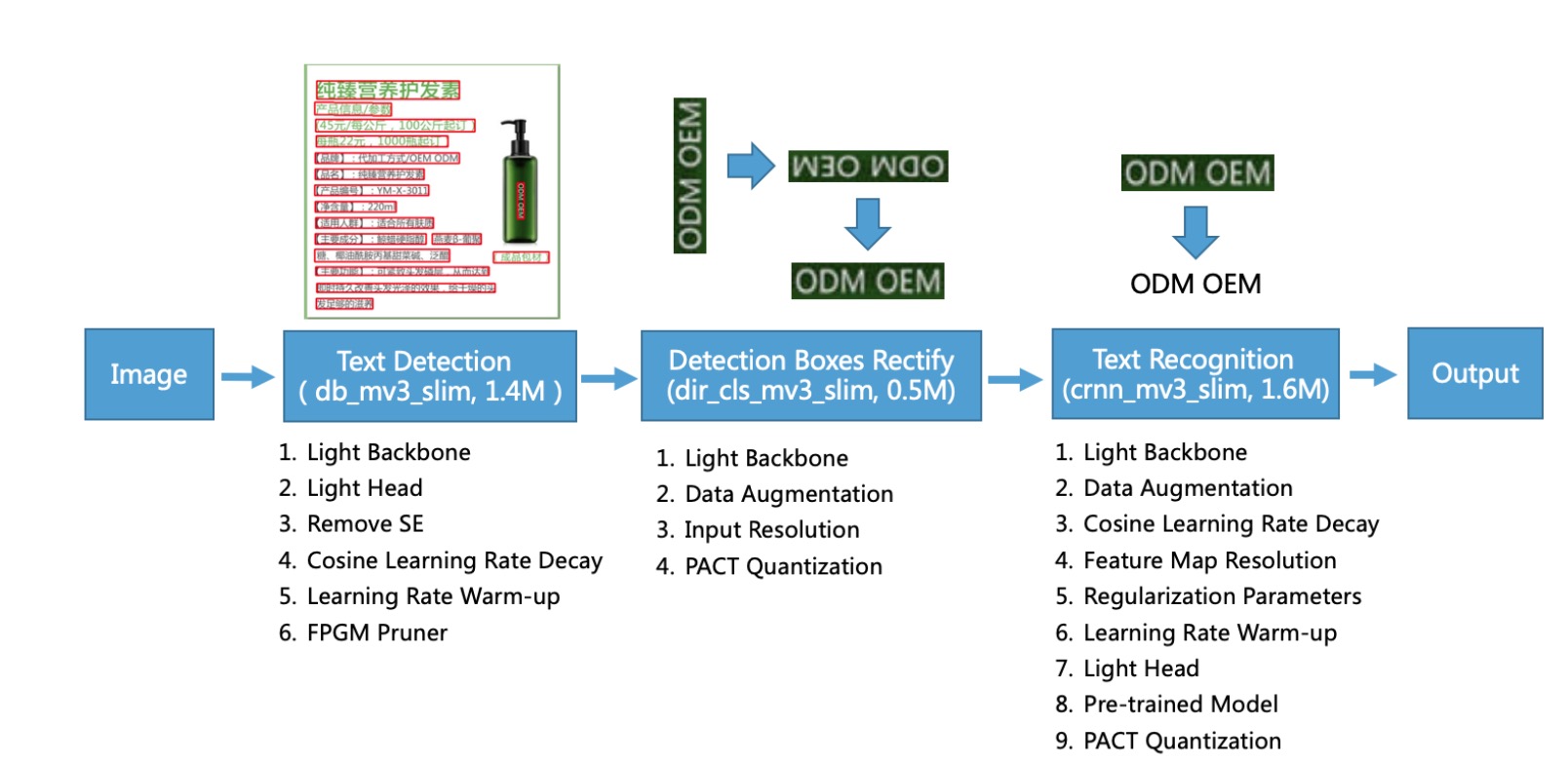
光学字符识别(OCR) 主要由文本检测、字符识别构成。如上图所示,PP-OCR 系统主要包含三个组件,文本检测(Text Detection),检测框修正(Detection Boxes Rectify), 文本识别(Text Recognition).
- Text Detection: 定位文本的位置 – DBNet
- Detection Boxes Rectify: 在文本识别前,检测的文本区域需要变换为水平的文本框 – 几何变换 ,同时还要判断文本方向是否正– 文本方向分类网络
- Text Recognition: 文本识别 – CRNN + CTC
以下对每个部分所采用的技术作介绍:
文本检测
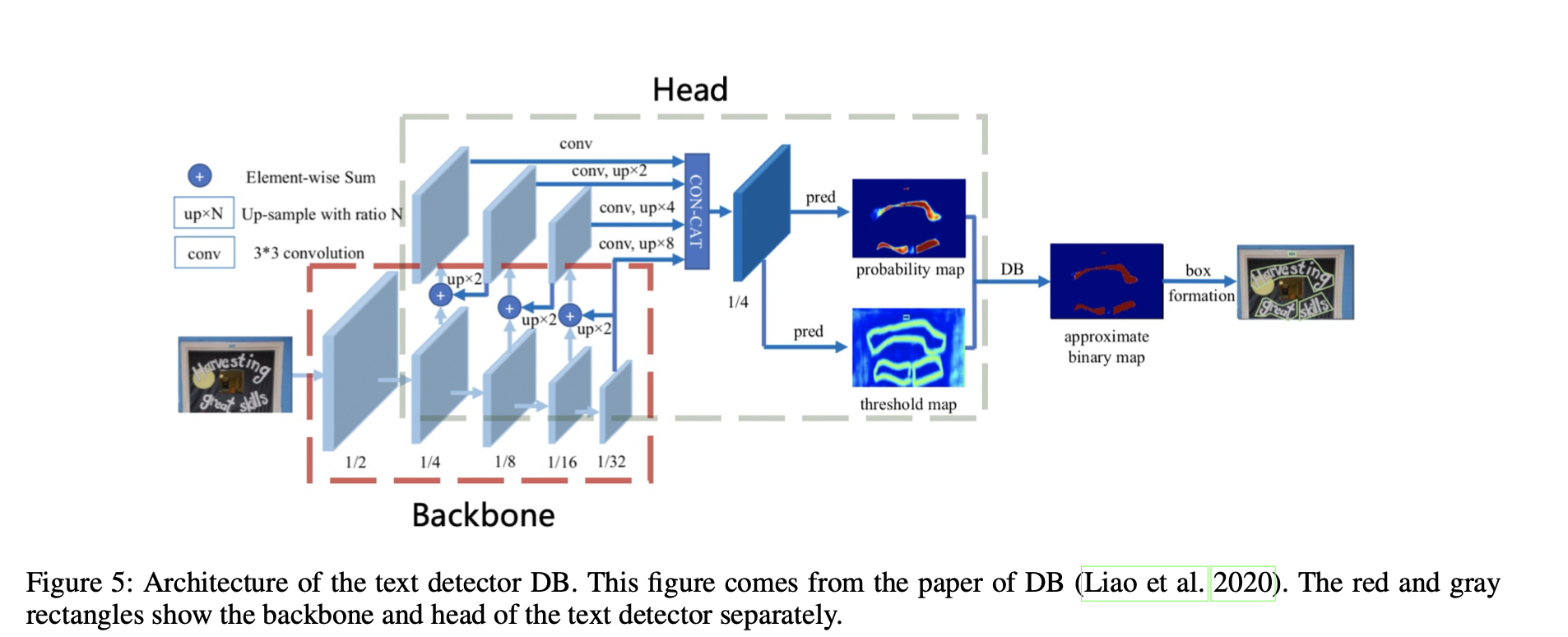
上图为DBNet 结构图。
Light backbone
使用轻量级的网络,比如mobileNetV1-V3, shuffleNet, 实验对比了大量的网络结构,在平衡性能和准确率之间mobilenetV3_large x0.5 最佳。
Light head
在采用DBNet的前提下,对于检测头,输出的概率图和阈值图的通道由原始的256降低到96,准确率轻微降低,模型大小由7 M降低到4.1M
Remove SE
在图片输入分辨率很大时,比如640 * 640 ,SE 模型的时间消耗过大,性能提升有限。PP-OCR 去掉SE模块,模型由4.1 M 缩小到 2.5M, 但是准确率无影响
Cosine Learning Rate Decay
Learning Rate Warm-up
FPGM Pruner
模型剪枝
方向分类
Light backbone
MobileNetV3 small x0.35
Data Augmentation
rotation, perspective distortion, motion blur and Gaussian noise etc, RandAugment
Input Resolution
一般来说提升分辨率可以提升准确率,backbone 本身就轻量级,输入 h ,w : 48, 192
PACT Quantization
文本识别
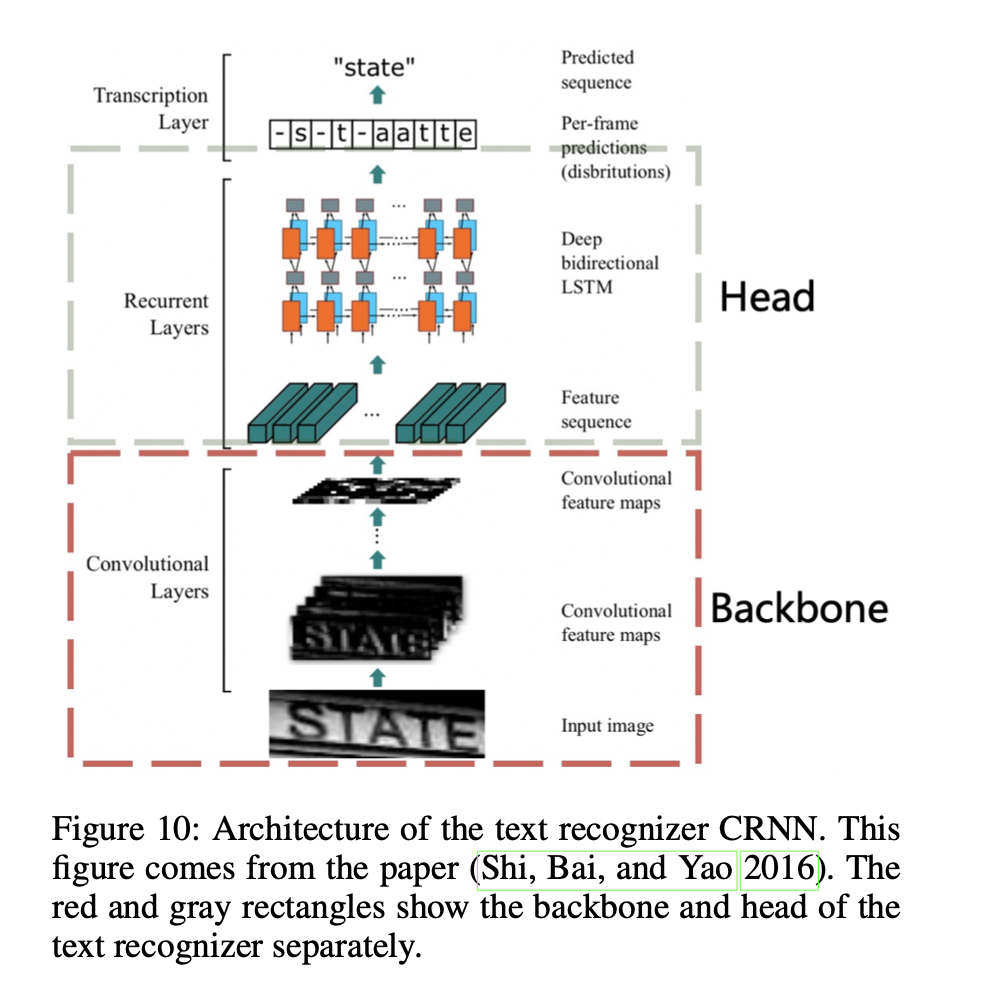
上图为CRNN 网络结构图
Light Backbone
CRNN backbone 采用 MobileNetV3 small x0.5 平衡准确率和性能.
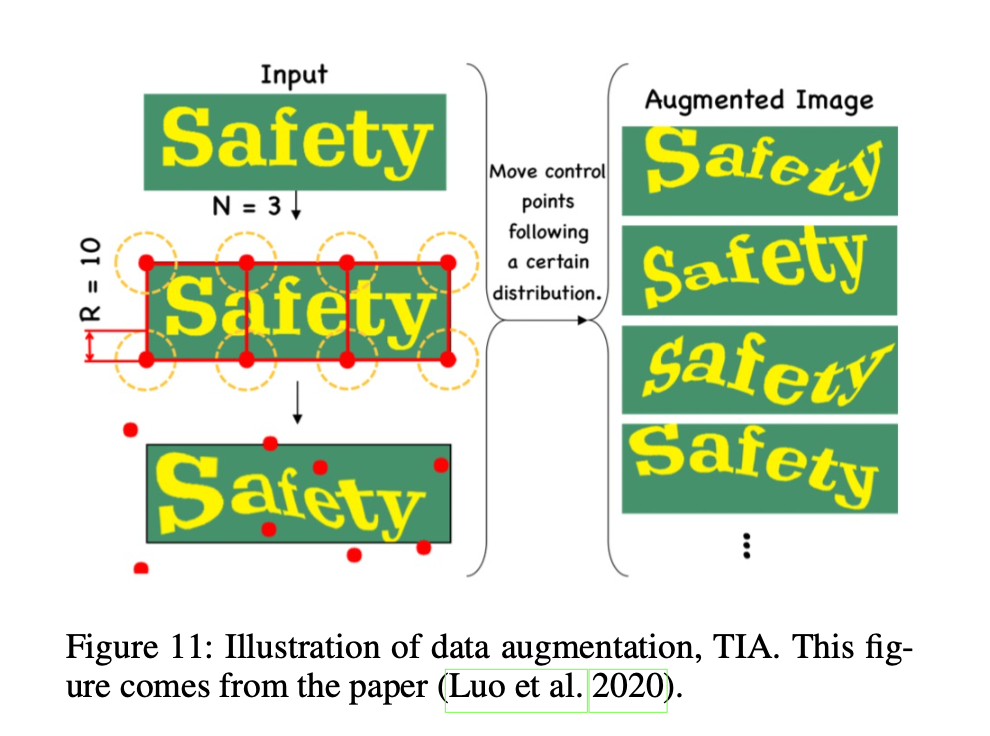
Data Augmentation
rotation, perspective distortion, motion blur and Gaussian noise etc, 以及 TIA
Cosine Learning Rate Decay
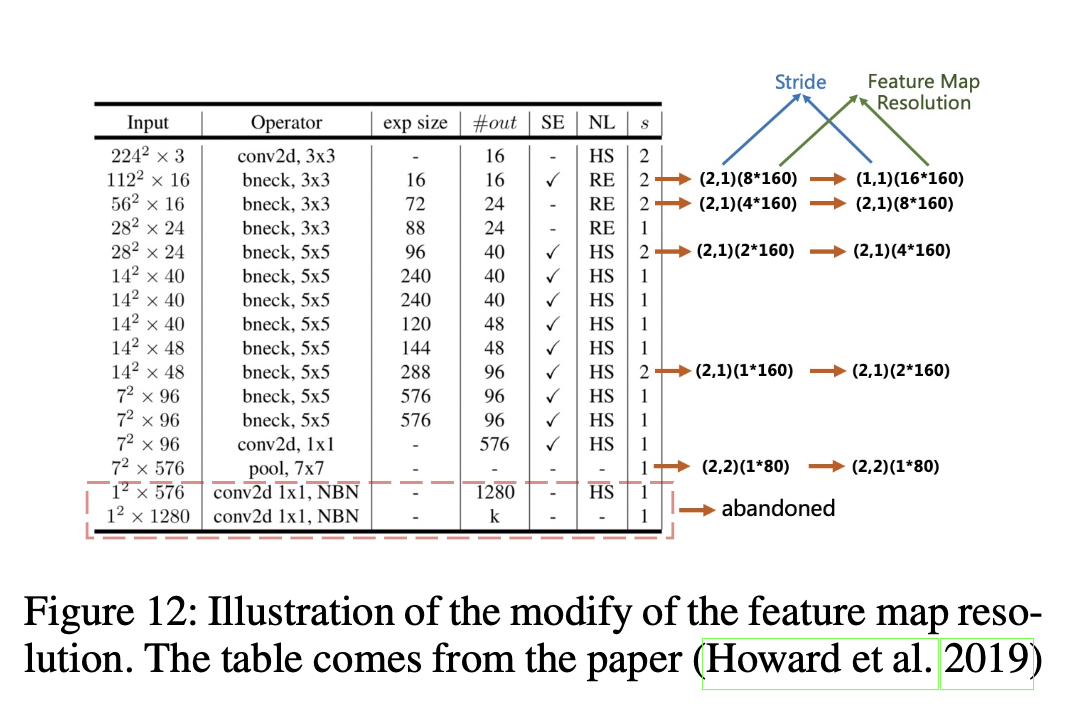
Feature Map Resolution
PP-OCR 中 CRNN 输入 高32,宽 320,同时需要对 Mobilenet的步长修改,如下图
Regularization Parameters
损失函数加 L2 正则,文中表示L2 正则对文本识别准确率影响很大
Learning Rate Warm-up
Light Head
采用全连接层对序列特征进行编码,将序列特征编码为普通序列中的预测字符。序列特征的维数对文本识别器的模型尺寸有很大的影响,特别是对于字符数超过6000的中文识别。同时,并不是维数越高,序列特征表示能力越强。在PP-OCR中,序列特征的维数根据经验设置为48
Pre-trained Model
PACT Quantization
数据集
如果想要训练一个OCR 系统大概需要多少数据?
文本检测:训练集 97K, 500 验证集。 68K是真实的图片,来自于 LSVT , RCTW-17 , MTWI 2018 , CASIA-10K, SROIE, MLT 2019, BDI, MSRA-TD500, CCPD, 以及百度搜素
方向分类: 600K 训练数据, 310 K 验证数据。训练数据包含从开源数据集中截取的100K 的水平样本,以及合成的500K 的反转文本,使用垂直字体合成一些文本图像,然后水平旋转它们
文本识别:17.9 M 训练集和 18.7 K 验证集,训练集中 1.9M是真实图片,其余16M合成图像主要集中在不同背景的场景、平移、旋转、透视变换、线条干扰、噪声、垂直文本等。合成图像的语料库来源于真实场景图像。所有的验证图像也都来自真实场景。
results

识别效果如上,PP-OCR 已开源,效果值得肯定。
