
Masked Autoencoders Are Scalable Vision Learners小记
读前三问
- 论文做了什么:论文以自监督的形式来训练自动编码器用来提取特征,实现无标注的预训练
- 怎么做的:对输入图片进行mask,采用编码器-解码器的结构,来重构出完整的额原图
- 论文达到了什么效果: 使用该方法预训练的VIT模型,再使用ImageNet-1k的数据,就能达到很高的准确率。同时作为下游迁移学习任务的预训练权重,性能超过有监督的预训练。
MAE 结构
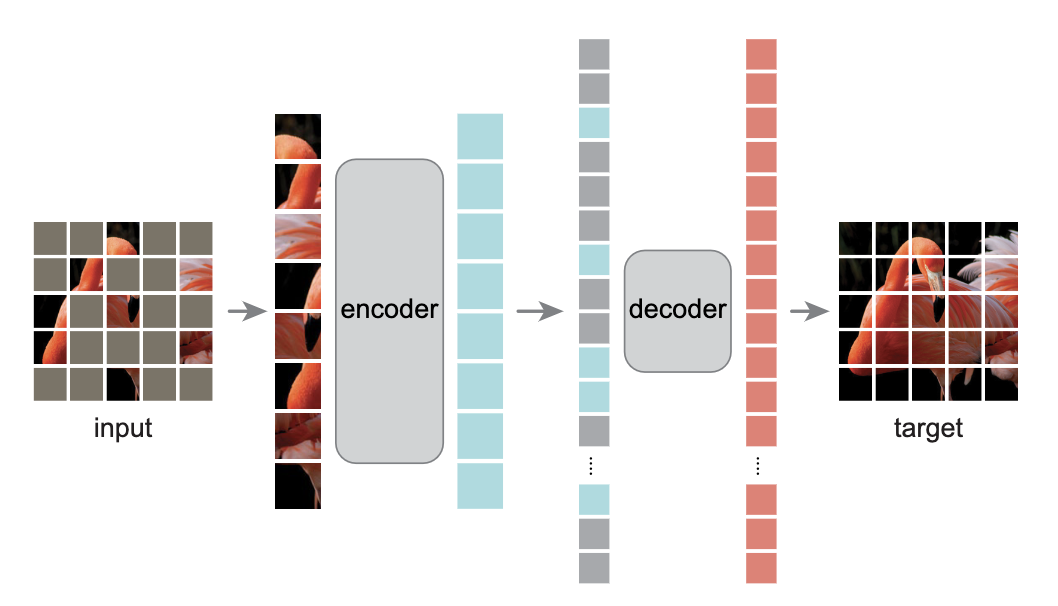
MAE 的整体思想结构如上图,对输入图片切成patch, 然后随机将部分图片块 mask 掉,然后对剩下的可见的图片块输入encoder 进行编码,然后将得到的embedded编码与 mask token 的embedded编码按照原图的顺序组合使用解码器去重构原图。在训练好模型后,将decoder丢弃掉,可以将encoder作为下游任务的特征提取器。MAE的整体结构相对来说还是很简洁。
Masking
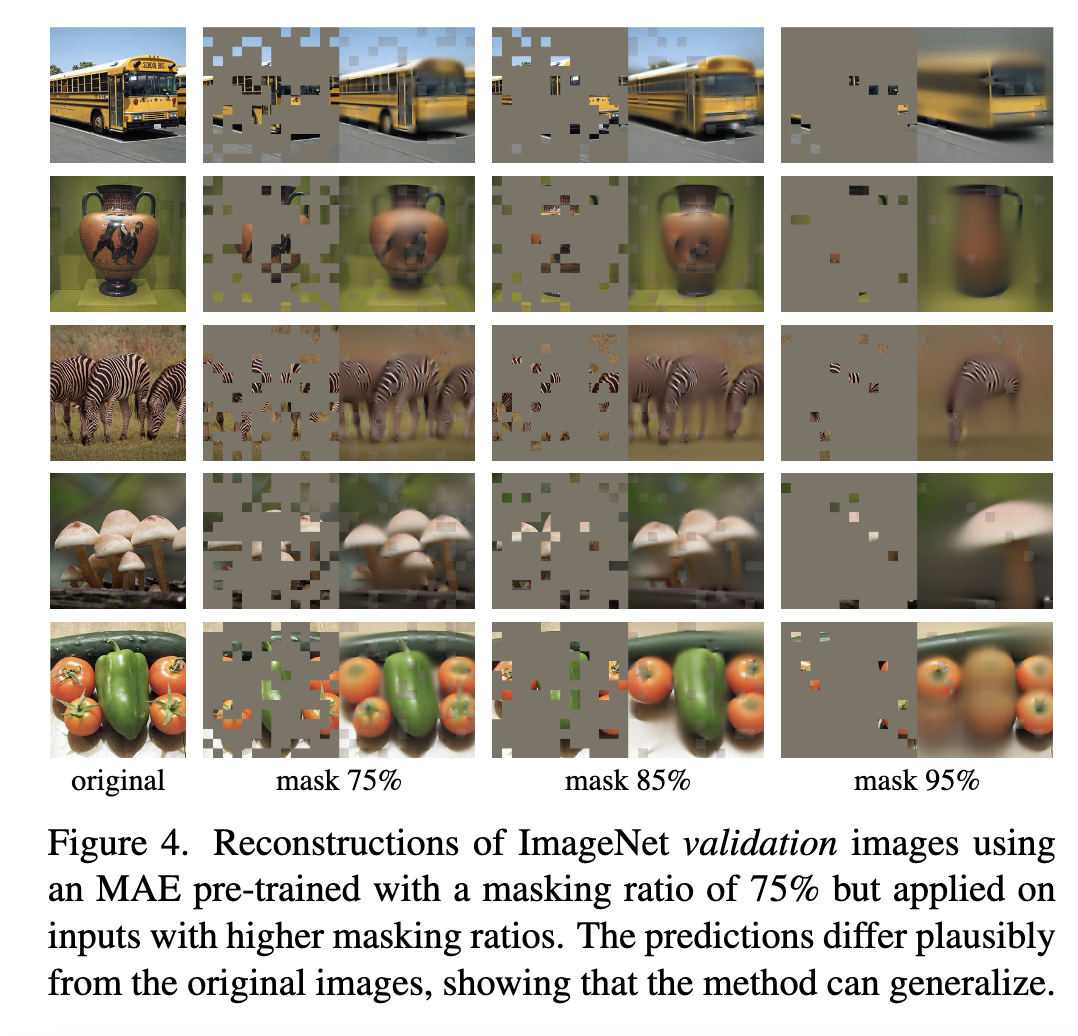
MAE 的encoder 采用 VIT模型,因此先将图片划分成不重叠的图片块,然后以较高的mask 率将图片块丢弃掉,输入到encoder中的只是原图的一个小的子集。 如上图所示,不同的mask 率下的输入和重构输出。
MAE encoder
标准 VIT encoder 模型,模型的输入不包含 mask 掉的图片, 对每一个输入图片片得到 embedding 向量。
MAE decoder
decoder 的输入包含 1)encoder 输出的所有向量 2)mask tokens. 会按照在原图中的顺序组合 mask token 和 encoder 的输出,同时会引入位置编码来指定每个图片块的位置。其中 mask token 和位置 pos_embedding 都是学习出来的.
重构目标
计算 mask patch 预测出的像素值和原图的像素值得 mse 误差,只就算mask patch 的重构误差。
总结
MAE 训练完后,使用训练好的encoder 可以用来图像识别特征提取或者作为下游任务的预训练权重。 由于CV领域一直以来比较依赖预训练,但是标注成本太大,导致真实世界大量的图片无法直接使用,因此在借鉴NLP里面的无标注预训练,比如BERT这些,MAE 以及MOCO 这一系列论文旨在研究对CV 进行自监督预训练。
