
L1、L2、Smooth_L1损失函数对比
L1、L2以及Smooth_L1损失函数作为目标检测中回归层常用的损失函数,对他们进行一个对比分析.
三者公式对比如下:
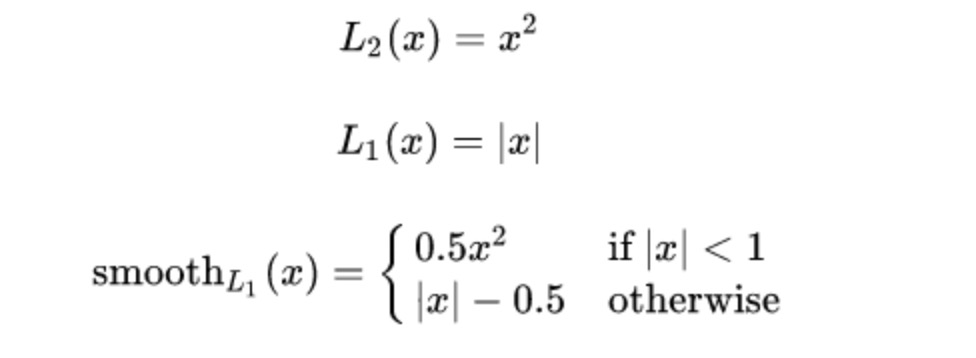
分别对三者求导数:
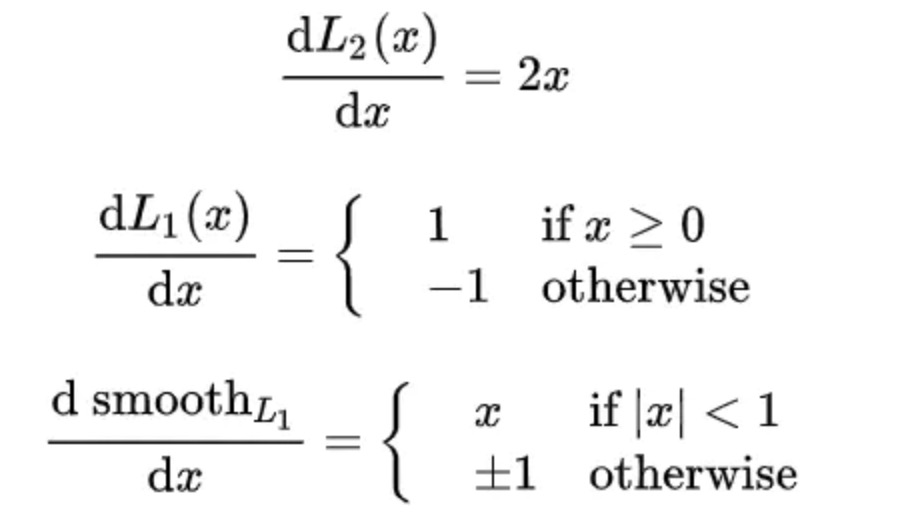
L2损失: 当损失增大时, L2对损失的梯度也增大,在训练初期能提供较大的梯度,因此收敛快。但是容易受离群点影响,例如某次训练时某个样本误差特别大,可能会主导梯度,导致训练不稳定,网络可能跑偏
L1损失: 导数为常数,训练初期相对于L2更加稳定(对噪声更鲁棒),收敛慢一点。后期,误差已经很小了,L1导数不变,若学习率不变,损失函数将在稳定值附近波动,难以收敛到更高精度
Smooth_L1: 在误差很大时,导数为常数,稳定。在误差很小时,梯度也会变得很小,可以收敛到更精确的精度
