
对比学习之SimCLR与MoCo小记
SimCLR 与 MOCO 都是采用自监督、对比学习的形式来训练视觉模型。因为对于主流的CNN网络,模型训练都依赖于人工标注,但是人工标注成本太大,我们能使用的标注数据只是真实世界图片数据的很小的子集。对于NLP任务而言,可以无需标注来进行模型预训练,然后再迁移到下游任务即可。SimCLR 等也是先采用无标注的图片得到预训练模型,可以用来特征提取或者迁移学习到下游任务.
SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
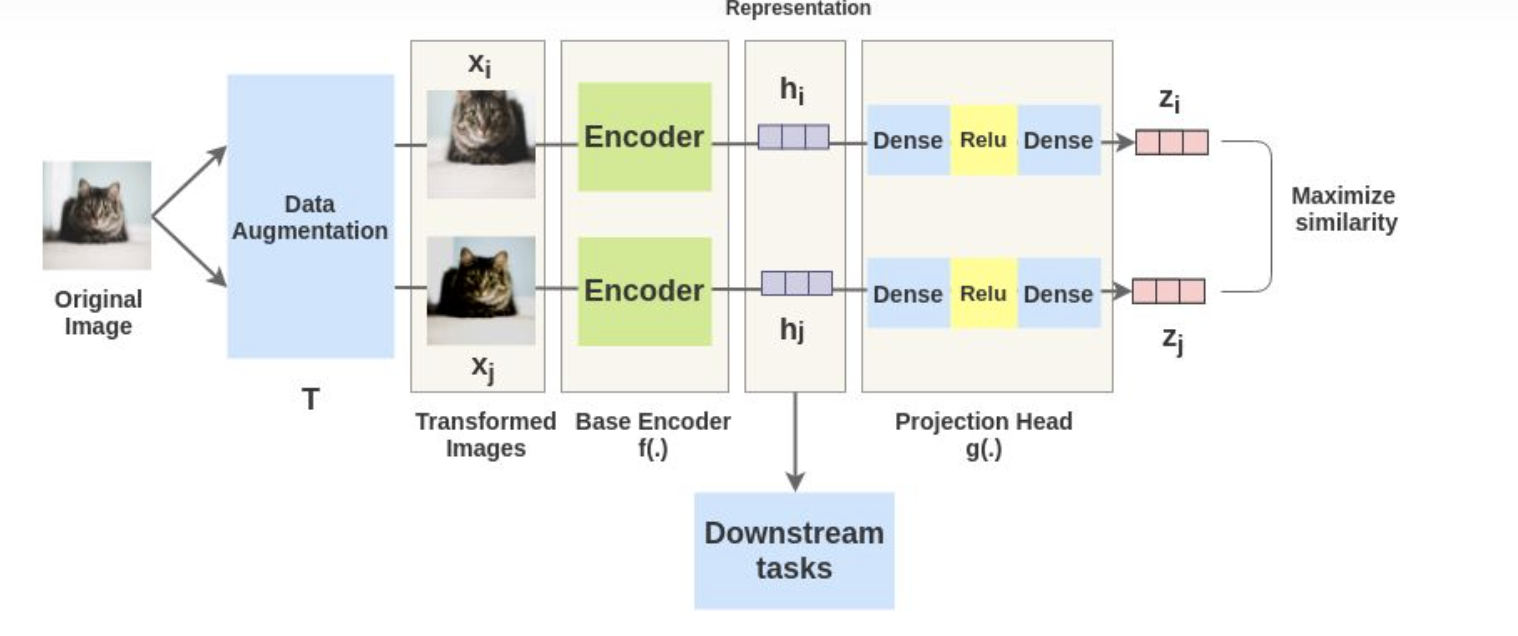
SimCLR 整体流程如上图,输入一张图片,首先对该图片进行数据增强得到增强后的图片,然后使用encoder进行编码得到embeddeding vector,然后通过投影层再进行特征映射,最后使用对比损失最大化相似度.
最后网络收敛后,只保留encoder, 此时encoder可以用来做特征提取器,亦可以作为下游视觉任务的预训练权重. 从上图来看,SimCLR的流程还是比较简单明了.
数据增强

simclr 主要通过数据增强来对输入进行采样,数据增强操作如上图所示。论文通过实验对比发现数据增强方式对对比学习很重要。
论文最终采用的数据增强方式: random cropping followed by resize back to the original size, random color distortions, and random Gaussian blur
encoder
自监督对比学习的目的就是为了得到encoder,encoder可以采用不同的形式,比如 CNN,transformer都可以
投影层
增加了一个投影层将encoder的输出映射到计算对比损失的空间,就是对特征再做了一个变换。
损失
采用对比损失,对比损失即将来至同一张图片的两张增强后图片特征拉近,来至不同图片的特征推理.
MoCo: Momentum Contrast for Unsupervised Visual Representation Learning
MoCo 论文主要思想和SimCLR 一致,做自监督的预训练

MoCo 的结构如上图,定义了一个 Quary q , 和一个队列的 k . 在该队列中,一般包含了单个的 positive 样本和多个 negative 样本。通过 contrastive loss 来学习特征表示
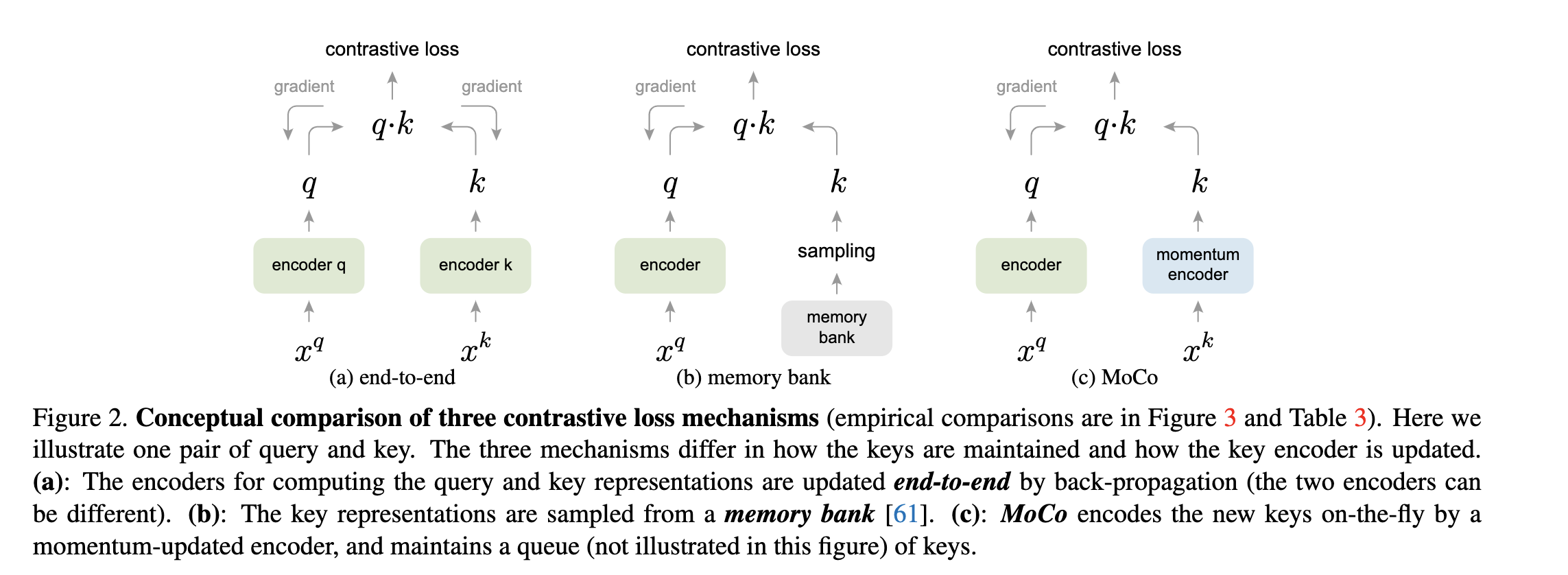
上图为三种对比学习的结构,SimCLR 就是第一种,对于第二种会占用大量的内存空间。
无论是SimCLR、MoCo 或者是MAE 都是旨在如何有效的在自监督下训练出一个有效的encoder.
