
Yolo-v5从代码到服务部署实践
yolo-v5 非论文,仅工程实现。本文主要记录自己对yolo-v5代码的学习、理解,以及实际服务部署。
网络结构
yolo-v5 包含4种模型结构,分别是yolov5s、yolov5m、yolov5l、yolov5x, 越往后模型越大。但是以上4种模型基本构造类似,大模型网络更宽、更深. 本文主要以yolov5s 作网络结构展示. 其它的几种主要区别在于网络深度与宽度不同,主结构一样。
yolov5 网络结构如下图所示:
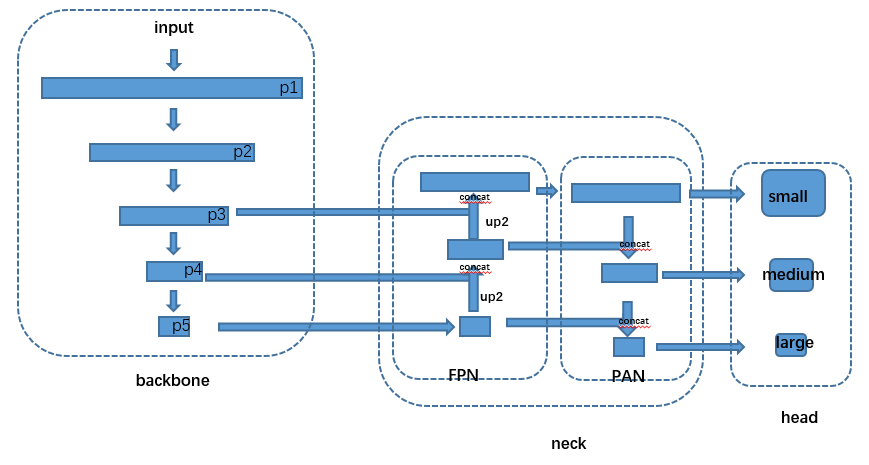
v5s 按代码展开如下:

其中 CSP、CSP1 分别对应于 BottleneckCSP 模块 中的上图和下图.
模块学习、理解
FOCUS 模块
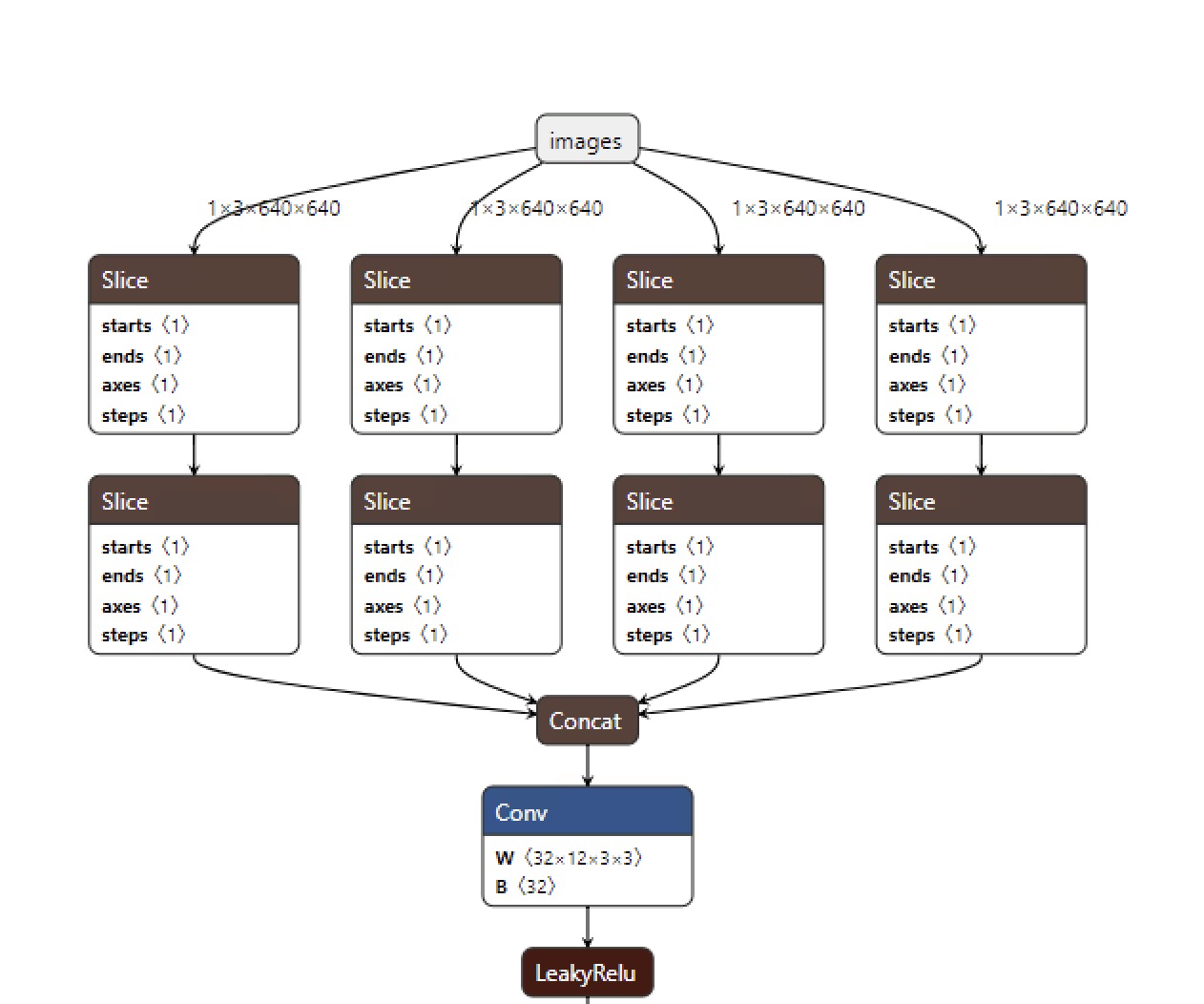
focus 对输入图片进行了切片, 核心代码如下:
torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
## 输入x 为 (b, c, w, h), ::2 分别表示 w(h) 轴从索引0 开始,每个两个index取一个值
x[..., ::2, ::2]
经过上诉切片增加了输入:

上图大图输入640 * 640 的图片,右边是切片后的四个子图。
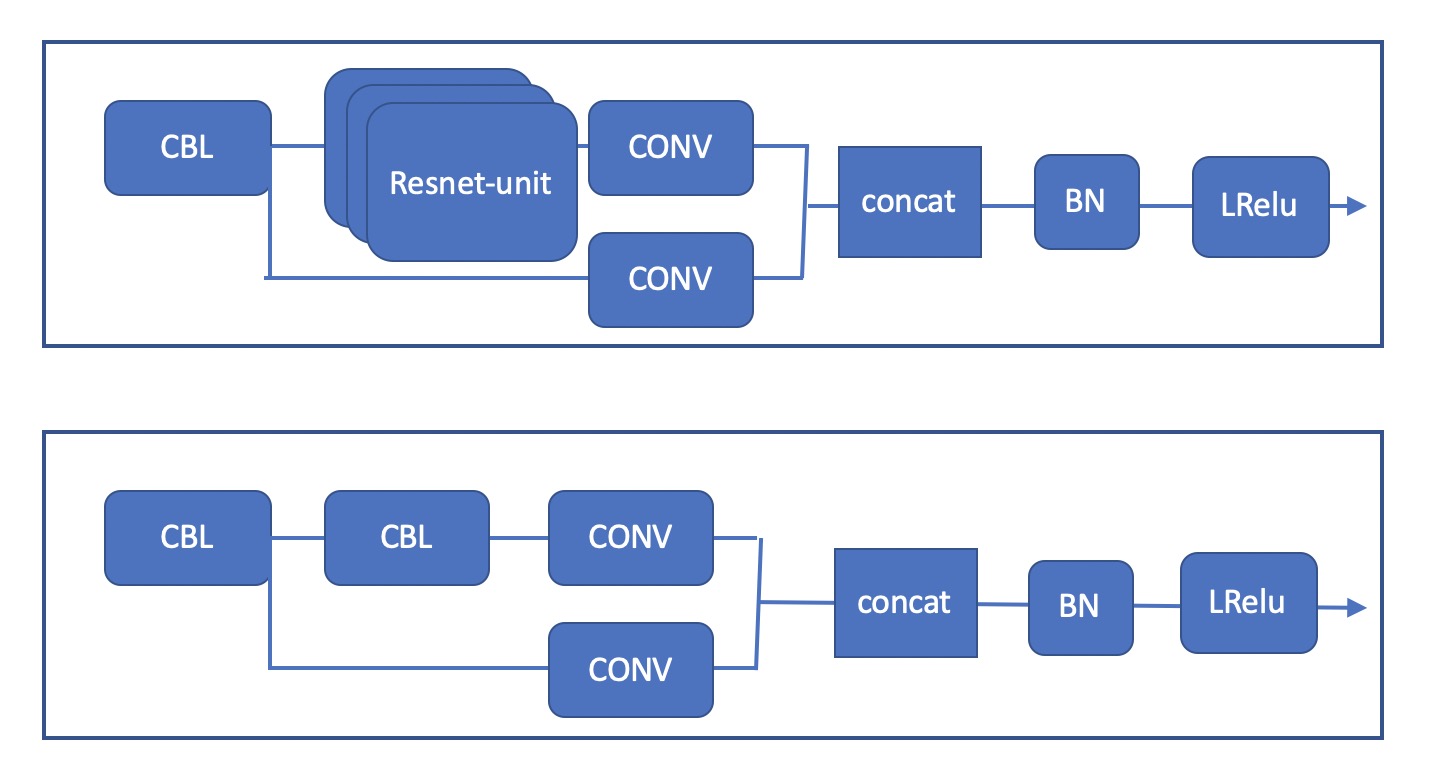
BottleneckCSP 模块
采用了CSPNet的思想,但和原始的CSPNet有所区别。 yolov5 有两种CSP结构,在主干网络中采用的CSP具有shortcut即残差单元,head 中的CSP无残差单元。结构如下
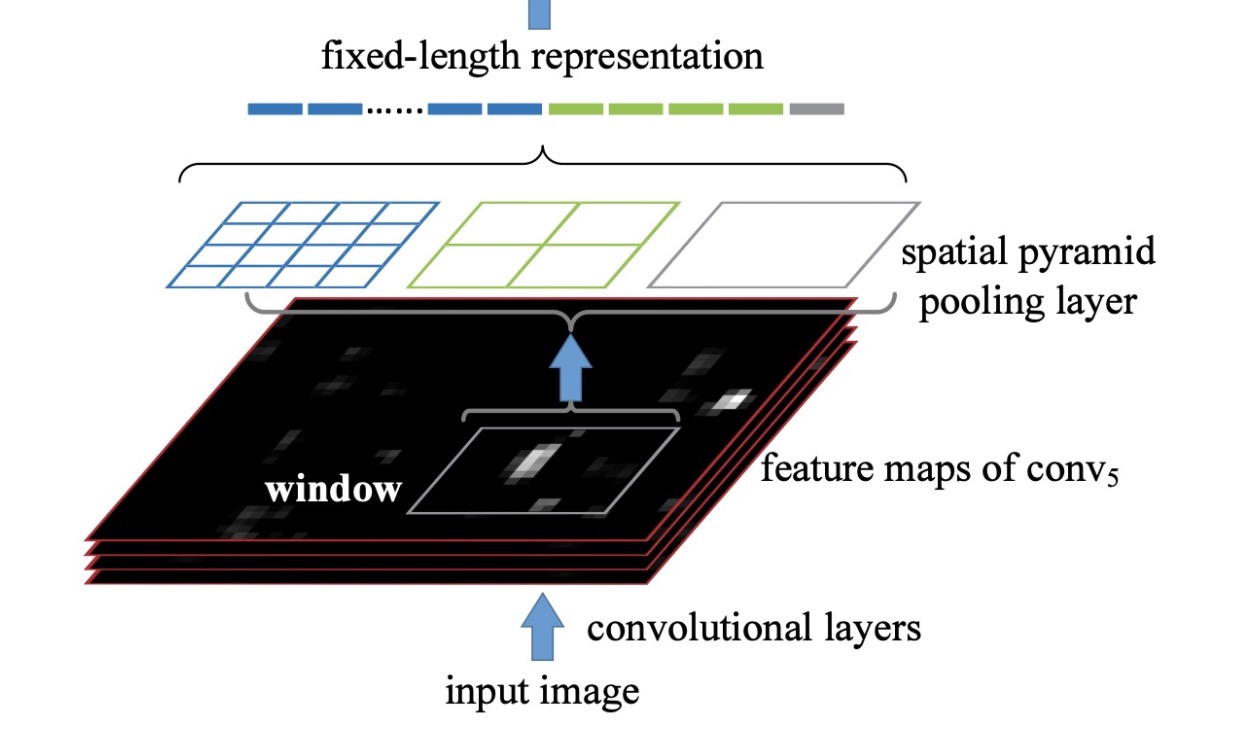
SPP 模块
采用了空间金字塔池化SPP,核大小分别为 (5, 9, 13)
spp理论上如下图,但 yolov5 代码中池化层步长为1,填充kernel_size//2, 因此输入输出大小一样.
Neck
如上网络结构图中的 Neck 部分所示,yolov5 的 Neck 采用了FPN + PAN 的结构。
Detect 模块
yolov5 检测层延续yolo head 的形式,$N$ 为anchor的个数, 浅层分配小anchor 负责检测小目标,深层分配大anchor, 检测大目标. 但是实际匹配的时候只要gt 与 anchor 在给定比例内,都能激活.

模型构建
yolov5 模型由定义于配置文件中,yolov5s,yolov5m,yolov5l,yolov5x, $depth\_multiple$, $width\_multiple$ 不同,其余均相同,可见控制生成不同的模型,主要由以上两参数控制,同时说明4个版本的模型的主题结构基本一致,主要在于各层的卷积核个数(网络宽度)、堆叠层数(网络深度)不同。
# 控制模块深度
n = max(round(n * gd), 1) if n > 1 else n
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args)
# 控制模块宽度
c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
损失计算
yolov5 中预测框的回归方式和v3(v4 采用的v3 head)不一样,关于v1-v3的框的回归计算,可以参考本人之前的小结 yolov1-yolov3个人理解.
以下参考自 https://github.com/ultralytics/yolov5/issues/471 中对yolov5 回归方式的讨论:
yolov5 代码中:
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
公式化为:
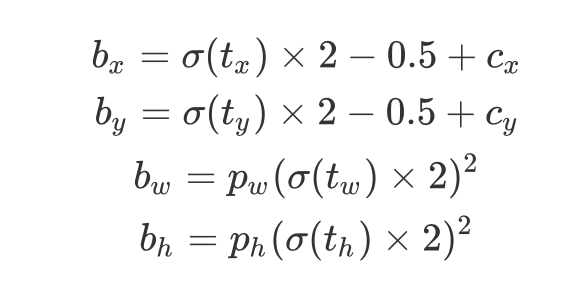
yolov3中的回归方式:
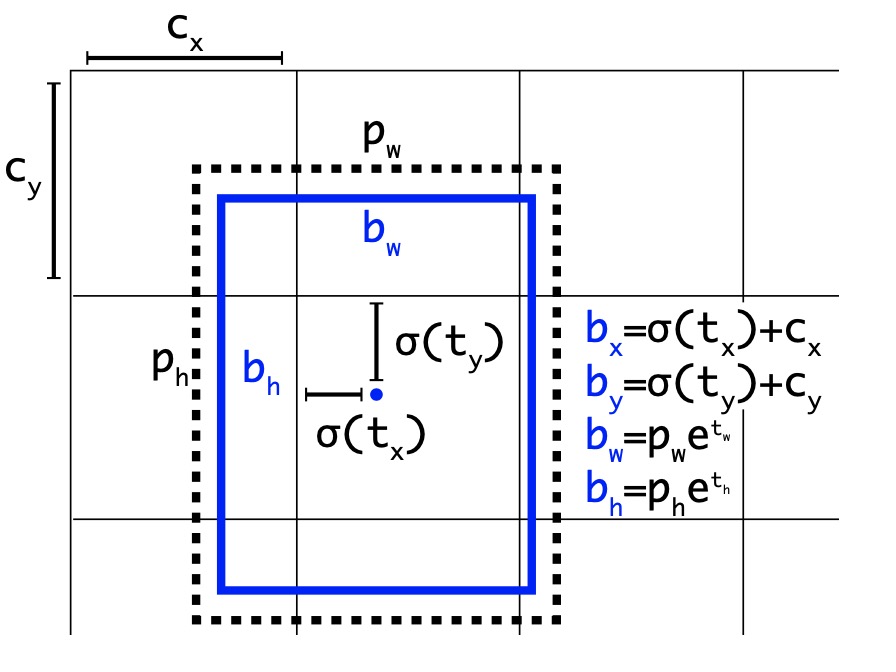
至于为什么采用这种形式,开发者的原话如下:
The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training. yolov3 suffers from this problem as well as yolov4.For yolov5 I made sure to patch this error by sigmoiding all model outputs, while also ensuring that the centerpoint remained unchanged 1=fcn(0), so nominal zero outputs from the model would cause the nominal anchor size to be used. The current eqn constrains anchor multiples from a minimum of 0 to a maximum of 4, and the anchor-target matching has also been updated to be width-height multiple based, with a nominal upper threshold hyperparameter of 4.0.
总结主要就是网络输出的宽、高无约束,若采用之前得形式,容易跑偏.
分类:focal loss
回归:可采用 giou,diou,ciou loss.
在线数据增强
数据增强方式:
- mosaic
- mixup
- 以及各种常用的仿射变换数据增强,比如:颜色空间、degrees、translate、scale、shear等
根据代码梳理数据加载过程:
def __getitem__(self, index):
index = self.indices[index]
hyp = self.hyp
mosaic = self.mosaic and random.random() < hyp['mosaic']
# 马赛克增强和letterbox增强互斥
if mosaic:
# Load mosaic
img, labels = load_mosaic(self, index)
shapes = None
# MixUp https://arxiv.org/pdf/1710.09412.pdf
# 如果需要mixup 则再生成一张马赛克数据进行mixup
if random.random() < hyp['mixup']:
img2, labels2 = load_mosaic(self, random.randint(0, self.n - 1))
r = np.random.beta(8.0, 8.0) # mixup ratio, alpha=beta=8.0
img = (img * r + img2 * (1 - r)).astype(np.uint8)
labels = np.concatenate((labels, labels2), 0)
else:
# letterbox 只图片resize与填充
# Load image
img, (h0, w0), (h, w) = load_image(self, index)
# Letterbox
shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
labels = self.labels[index].copy()
if labels.size: # normalized xywh to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
if self.augment:
# Augment imagespace
# 图像增强
if not mosaic:
# 马赛克操作后已经进行了 random_perspective
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
# Augment colorspace
# hsv 颜色空间增强
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
# Apply cutouts
# if random.random() < 0.9:
# labels = cutout(img, labels)
nL = len(labels) # number of labels
if nL:
# 坐标转换以及归一化
labels[:, 1:5] = xyxy2xywh(labels[:, 1:5]) # convert xyxy to xywh
labels[:, [2, 4]] /= img.shape[0] # normalized height 0-1
labels[:, [1, 3]] /= img.shape[1] # normalized width 0-1
if self.augment:
# flip up-down, 上下翻转
if random.random() < hyp['flipud']:
img = np.flipud(img)
if nL:
labels[:, 2] = 1 - labels[:, 2]
# flip left-right,左右翻转
if random.random() < hyp['fliplr']:
img = np.fliplr(img)
if nL:
labels[:, 1] = 1 - labels[:, 1]
labels_out = torch.zeros((nL, 6))
if nL:
labels_out[:, 1:] = torch.from_numpy(labels)
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
return torch.from_numpy(img), labels_out, self.img_files[index], shapes
letter box
对于目标检测,训练时输入一般都是正方形,所以需要对图片进行resize, 暴力的resize 会丢失目标长宽比,如果保持长宽比那么训练时一般先保持长宽比缩放,然后进行填充成方形。虽然测试时也能这么做,但是如果填充区域很大的话,在填充区域上花费的推理时间是不必要的,如果能够减少这些时间消耗,那么就能降低推理时间,letter box 即从推理阶段降低时间。(目前以Torch加载模型可以使用该策略加速,但是当导出为 onnx (以及onnx 转 tf_saved_model)时,不能使用,因为导出时模型输入大小已固定, 导出torch script 本人未测试,但应该也不行)
步骤
- 假如输入图片大小 1080 * 1920 (高、宽),网络输入(640, 640),缩放比例 $ratio = min((640 / 1080), (640/ 1920))$, 即以最长边的缩放比率为准
- 计算缩放后的尺寸: 高 n_h :1080 * ratio 取整 360, 宽 n_w :640
- 计算需要填充的像素:首先计算原本需要填充的像素,640 - 360 = 280,即高度需要填充280个像素,宽度不需要填充。 然后将计算出的像素差与32相除求余为24,即高度方向需要填充24个像素数,采用上下各填充12像素
- 将图像resize到(360, 640), 然后使用 cv2.copyMakeBorder 对图像上下左右进行填充,填充值为灰色. 得到新图像 (384, 640)
相对于 (640, 640)的图像, (384, 640) 图像卷积后得到的特征图在高度上更小,输出的 grid 少,运算更快、解码更快,所以能降低推理时间。 此策略只用于推理阶段.
模型训练
VOC数据集转换
需要将VOC格式的数据进行转换,以下脚本在VOC数据集目录下生成 images、 labels 保存yolov5所需的数据, 目录结构如下
VOCDATA
+ JPEGImages/
+ ImageSets/
* Main/
train.txt
val.txt
+ Annotations/
+ images/
* train/
* val/
+ labels/
* train/
* val/
import xml.etree.ElementTree as ET
import os
import shutil
year = "2012"
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(data_dir, image_id, train, classes=None):
in_file = open(os.path.join(data_dir, 'VOC' + year + '/Annotations/%s.xml' % (image_id)), encoding='utf-8')
if train:
out_file = open(os.path.join(data_dir, 'labels/train/%s.txt' % (image_id)), 'w', encoding='utf-8')
else:
out_file = open(os.path.join(data_dir, 'labels/val/%s.txt' % (image_id)), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if classes is not None:
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
def make_txt_labels(data_dir, classes=None):
if not os.path.exists(os.path.join(data_dir, 'images')):
os.makedirs(os.path.join(data_dir, 'images/train'))
os.makedirs(os.path.join(data_dir, 'images/val'))
if not os.path.exists(os.path.join(data_dir, 'labels')):
os.makedirs(os.path.join(data_dir, 'labels/train'))
os.makedirs(os.path.join(data_dir, 'labels/val'))
# make train labels
train_image_ids = open(os.path.join(data_dir, 'VOC' + year + '/ImageSets/Main/train.txt'), encoding='utf-8')
for image_id in train_image_ids:
image_id = image_id.strip()
convert_annotation(data_dir, image_id, True, classes)
img_path = os.path.join(data_dir, 'VOC' + year + '/JPEGImages', image_id + '.jpg')
shutil.copy(img_path, os.path.join(data_dir, 'images/train/'))
# make val labels
val_image_ids = open(os.path.join(data_dir, 'VOC' + year + '/ImageSets/Main/val.txt'), encoding='utf-8')
for image_id in val_image_ids:
image_id = image_id.strip()
convert_annotation(data_dir, image_id, False, classes)
img_path = os.path.join(data_dir, 'VOC' + year + '/JPEGImages', image_id + '.jpg')
shutil.copy(img_path, os.path.join(data_dir, 'images/val/'))
return os.path.join(data_dir, 'images/train'), os.path.join(data_dir, 'images/val')
data_dir = ''
make_txt_labels(data_dir)
超参含义
几个主要超参
box: 0.05 # bbox回归损失系数
cls: 0.5 # 分类损失系数
cls_pw: 1.0 # 分类 BCELoss 正样本权重
obj: 1.0 # 前景物体损失系数
obj_pw: 1.0 # 前景物体 BCELoss 正样本权重
iou_t: 0.20 # 分配anchor时IOU阈值,当任一物体与任一anchor的IOU大于阈值时,均将此物体分配给该anchor,代码中已弃用
anchor_t: 4.0 # 分类anchor时,物体和anchor的宽高比小于此系数,将物体分给该anchor检测,一个物体可以同时分配给多个anchor
anchors: 3 # 每个输出层的anchor个数
模型导出以及生产部署
使用yolov5中自带的 export.py 脚本可以将模型导出为 TorchScript, ONNX, CoreML
代码中默认设置导出detect 层,但是运行 ONNX 服务时,预测结果有负数
将以下代码设置为 False
model.model[-1].export = True
model.model[-1].export = False
但是导出Core ML 会报错,我们只需要 ONNX 模型
TritonServer
配置文件如下:
name: "yolov5"
platform: "onnxruntime_onnx"
max_batch_size : 0
input [
{
name: "images"
data_type: TYPE_FP32
format: FORMAT_NCHW
dims: [ 3, 640, 640 ]
reshape { shape: [ 1, 3, 640, 640 ] }
}
]
output [
{
name: "output"
data_type: TYPE_FP32
dims: [1,25200,7]
}
]
TFServer
由 ONNX 转换为 tf_saved_mode.pb
import onnx
import numpy as np
from onnx_tf.backend import prepare
model = onnx.load('yolov5.onnx')
tf_model = prepare(model)
tf_model.export_graph('yolov5_saved_model')
导出的为模型可直接用于 tensorflow_server, 签名默认 default_serving, 输入输出如下:
"inputs": [{'node_name': 'images', 'node_type': 'FP32', 'node_shape': [1, 3, 640, 640]}],
"outputs": [{'node_name': 'output_0', 'node_type': 'FP32', 'node_shape': [1, 25200, 7]}]
- 由于模型导出输入大小已固定, 需将 letterbox 中 auto 与 scaleFill 设置为 False,不然预测坐标映射会原图是偏的
如果不想重写 NMS 函数,可以在拿到服务端结果后,将其转换为 torch 的tensor, 不然调用不了原代码
torch.from_numpy(pred.astype(np.float32))转换两次之后得到的tf saved_model推理时间长。本人在2070 supero 下做过对比试验。在tf_serving下,输入分辨率640:yolov5s (tf_saved_model)推理时间平均为0.09s, efficientdet-d0(tf_saved_model) 推理时间平均为0.024s。在Triton_server 下,经过两次转换之后的yolov5s(tf saved_model)已经无法在Triton里运行了,各种算子报错,未能解决。所以只对比 yolov5s onnx版与efficientdet-d0 (tf_saved_model), 在Triton下yolov5s(onnx) 平均推理时间为0.025左右,efficientdet-d0(tf_saved_model)平均推理时间基本保持一致。
