
Transformer 个人小结
transformer 已经出来三年了,自己也没有深入了解,触及皮毛,最近想研究一下detr, 顺便写个 📒 记录一下对transformer的理解,个人主要从代码角度理解它的训练、测试的输入输出,关于理论网上太多了,自己只记录几个重点。这篇博客主要参考于李宏毅教授的课程以及 pytorch的transformer代码。
self-attention
说transformer离不开self-Attention。先从RNN引入,对于循环神经网络及其变体,它们都存在一个时间步的概念,对于一个输入的样本序列,网络处理每一个样本总是有一个先后顺序 (对于单向RNN,总是先处理第一个时间步的样本,然后带着从第一个样本获取的特征再处理第二个时间步的样本,以此类推),所以对于输入序列,RNN是串行处理,所以导致慢,不能使用GPU进行高效的并行训练。为了解决这个问题,提出了transformer。
时序样本序列由于前后样本之前存在关联,RNN通过串行(单向、双向)来获得整体序列样本之间的关系。self-attention 实现不需要串行就能让序列中的样本互相‘看见’彼此.
结合李宏毅课件和代码
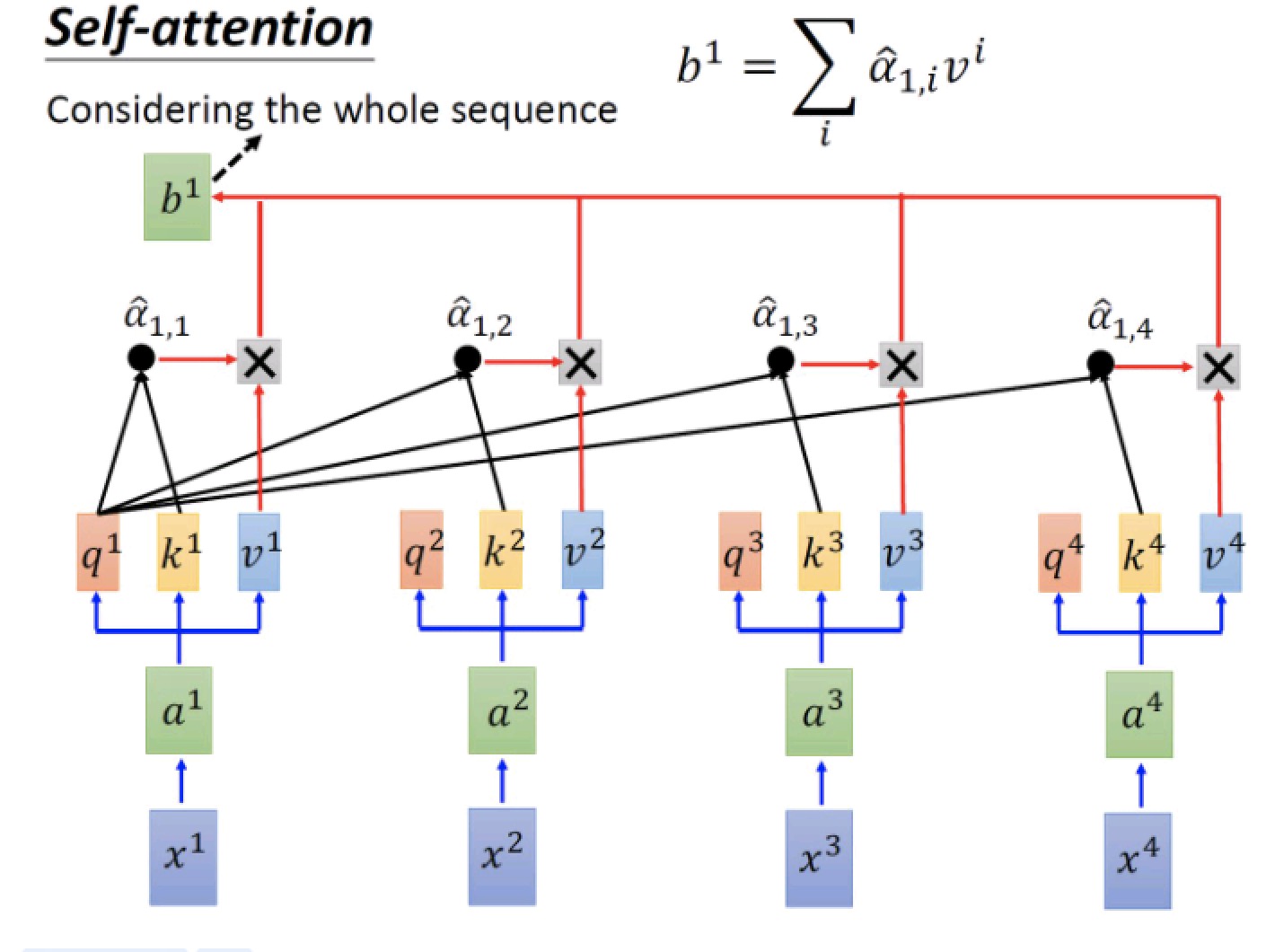
假如输入一个句子包含4个单词,x1,x2,x3,x4,先进行embeding, 每个单词表示为 1 * 512 维的 vector, 分别为 a1,a2, a3, a4,然后使用三个矩阵 $W _q$, $W _k$, $W _v$ 分别与 a1 ,a2, a3, a4 运算得到 q(query), k (key), v (value), 然后每个输入单词的 q 都会与句子中的每一个单词的 k 计算 attention值 (相关性、相似性) 再与各个 v 相乘获取加权和即为该单词经过self-attention 层后的表达. 经过上诉操作,任一输入单词都带有了整个输入序列每一个单词的信息了.
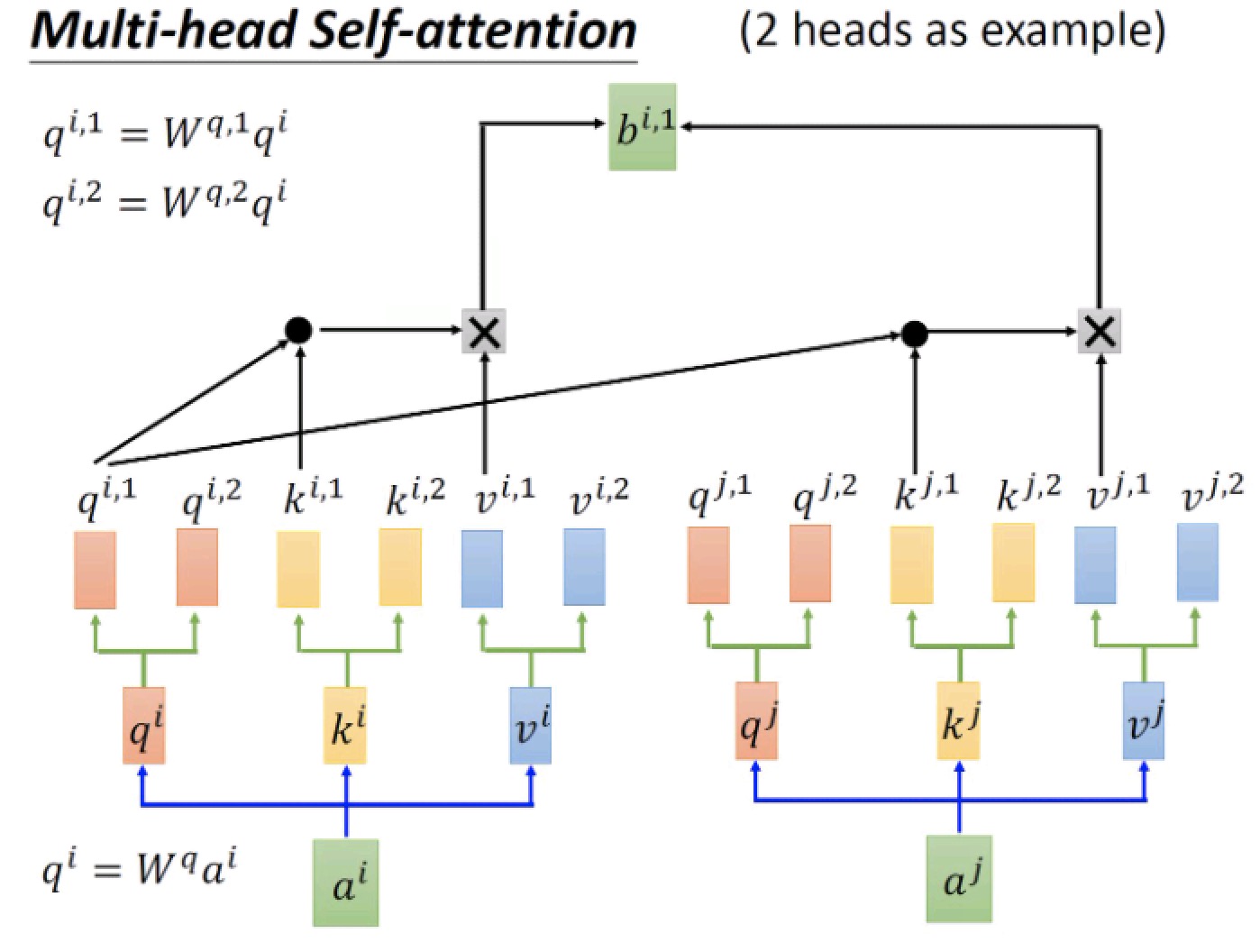
上诉 $W _q$, $W _k$, $W _v$ 只有一个,所谓 multihead 即有多个 $W _q$, $W _k$, $W _v$ , 网络变宽,特征更丰富。
位置编码
对于RNN,样本按顺序读入,天然带顺序的属性。self-attention 没有位置、先后的信息,对于时序序列,位置信息不可少。transformer里在对输入单词embeding 之后加上了文中提出的PositionalEncoding. 编码公式如下:
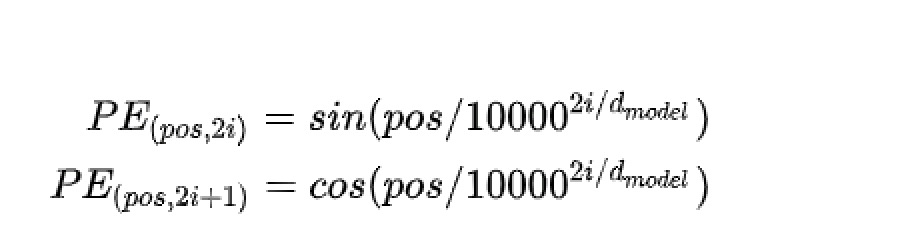
代码预设句子长度200,对每一个位置按上诉公式进行编码得到 200 * 512 的矩阵,比如第一行代表输入第一个单词的位置信息编码. 最终会和每个对应位置输入单词的embedding 向量相加.
def _get_sinusoid_encoding_table(self, n_position, d_hid):
def get_position_angle_vec(position):
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2])
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2])
return torch.FloatTensor(sinusoid_table).unsqueeze(0)
FFN
全连接 + 残差
class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return x
transformer结构
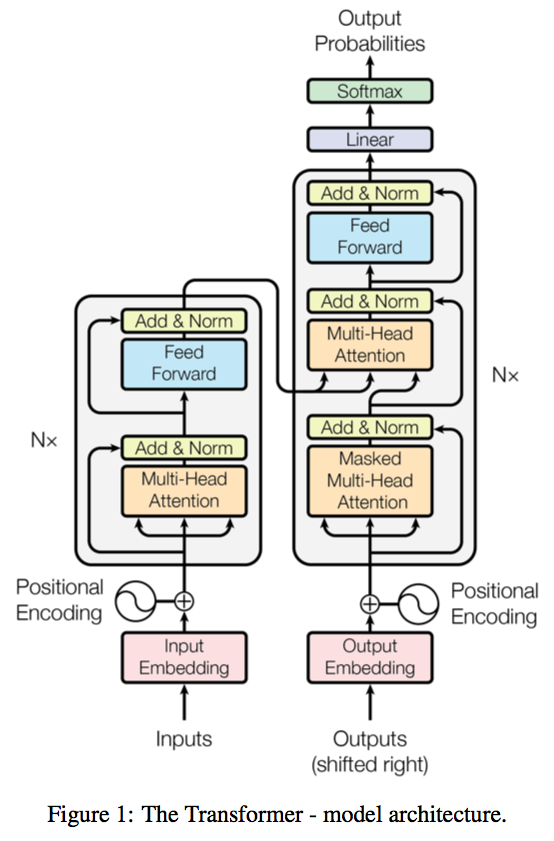
左边编码器,右边解码器,网上解释太多不细说,主要记录一下代码里面的细节。
src_mask: 输入mask, 对于每个句子 src_mask 是个一维bool向量,对于batch训练的输入,各个句子的长短不一,需要对短句子进行填充,但是计算attention的时候是整个句子计算,所有不希望对填充的token计算attention值,src_mask 标志哪些是填充token,计算attention时在softmax前后赋予其很小的值。
trg_mask: 目标句子的mask, 对于每个句子,句子有n个单词,trg_mask 是个 n * n 的矩阵,比如在目标语句中第一个单词只能和自己计算attention值,第二个单词能看见第一个单词,所以可以与第一个单词和自己计算attention值,以此类推,seq2seq 模型在解码器训练和测试时一般会输入一个单词预测下一个,然后将预测的单词的再输入解码器预测下一个,测试时只能这样,但训练时这样就存在串行,效率低。因此transformer在训练时采用teacher forcing策略,直接将整个gt句子用于decoder的输入,那么一次性进行整个句子的预测,计算每个预测单词的loss.
对于只有三个单词的目标句子,trg_mask如下:
|true | false | false|
|true | true | false|
|true | true | true |
Masked Multi-Head Self-attention : 在decoder中,第一次是Masked Multi-Head Self-attention 层,因为训练时输入了整个句子的ground-truth,那么会计算各个单词之间的attention值,但是实际预测的时候目标语句前面的单词是不知道后面的单词的,所以计算attention的时候会与trg_mask 按位乘.
在decoder 中 第一个 Masked Multi-Head Self-attention 的 query, key, value 来自于 output embedding, 第二个 Multi-Head Self-attention query 来自于第一个 Masked Multi-Head Self-attention的输出,key, value 来自encoder 的输出.
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
output = torch.matmul(attn, v)
return output, attn
