
Reid之路(一):初识 reid: Deep Learning for Person Re-identification:A Survey and Outlook
目前团队项目逐渐偏向识别,自己的工作重心逐渐由检测、分类转向reid相关,自己之前对reid也没有深入,因此准备记录自己在reid工作上的成长过程.
前言
person-reid 又简称 reid,是旨在用来从图片序列或视频中检索行人的技术。可总体划分为以下5步:
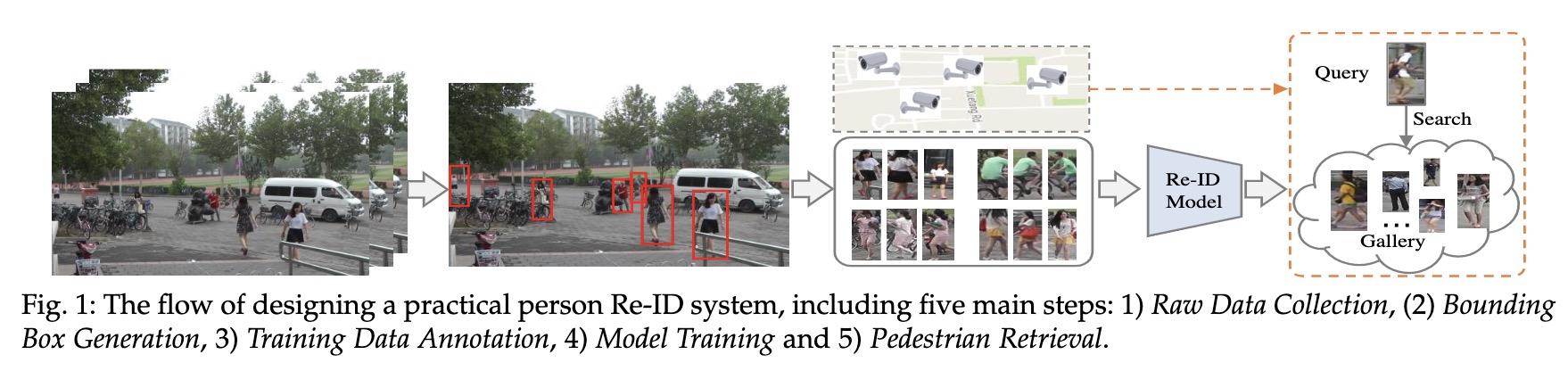
- 原始数据采集: 主要来自于监控摄像头
- 行人框生成: 将图片中的行人裁剪出来,可通过人工或使用行人检测算法
- 训练数据标注: 可能包含行人属性、相机等,对于新场景,一般需要重新标注
- 模型训练: 模型集中于特征表示学习、距离度量学习或者二者的组合
- 行人检索: 给定 query(感兴趣的行人) 和 gallery 集合,用训练得到的模型抽取各自的特征表达,然后计算 query 和 gallery 中每个行人的相似度进行排序.
论文中将ReID技术分为 Closed-world 和Open-world 两大子集 , 本文主要记录 closed-world 的reid, 即常见的标注完整的有监督的行人重识别方法.
closed-world reid
闭集 reid 主要基于以下假设:
- 行人通过视频或图片获得行人外观
- 用bounding box 表示行人,同一个行人要有多个box
- 足够多的训练数据
- 标签正确
- query 必须出现在gallery中
closed-world reid 系统主要包含三个部分:特征学习(设计特征组合策略)、深度度量学习(设计不同的损失函数或采样策略)以及排序优化(优化检索的排序列表).
特征学习方法

如上图所示,特征学习方法主要分为为四种:
- Global Feature Representation Learning:全局特征表示学习对每一张行人图片抽取抽取全局特征向量。实现上有:单张图像训练分类、输入多种图像使用 triplet loss 训练,以及广泛使用的将每个ID看做一个类别的以多分类实现。以及attention机制等。
- Local Feature Representation Learning:利用局部图像区域(行人部件或者简单的垂直区域划分)来进行特征学习,并聚合生成最后的行人特征表示
- Auxiliary Feature Representation Learning:利用一些辅助信息来增强特征学习的效果,如语义信息(比如行人属性等)、视角信息(行人在图像中呈现的不同方位信息)、域信息(比如每一个摄像头下的数据表示一类域)、GAN生成的信息(比如生成行人图像)、数据增强等;
- Video Feature Representation Learning:利用视频的时空信息提取特征,根据多帧的信息来构建行人特征
- Architecture Design:设计更好的网络结构以适合reid场景. 如通常将最后一层卷积的步长为1,最后一层池化使用自适应平均池化等
Deep Metric Learning
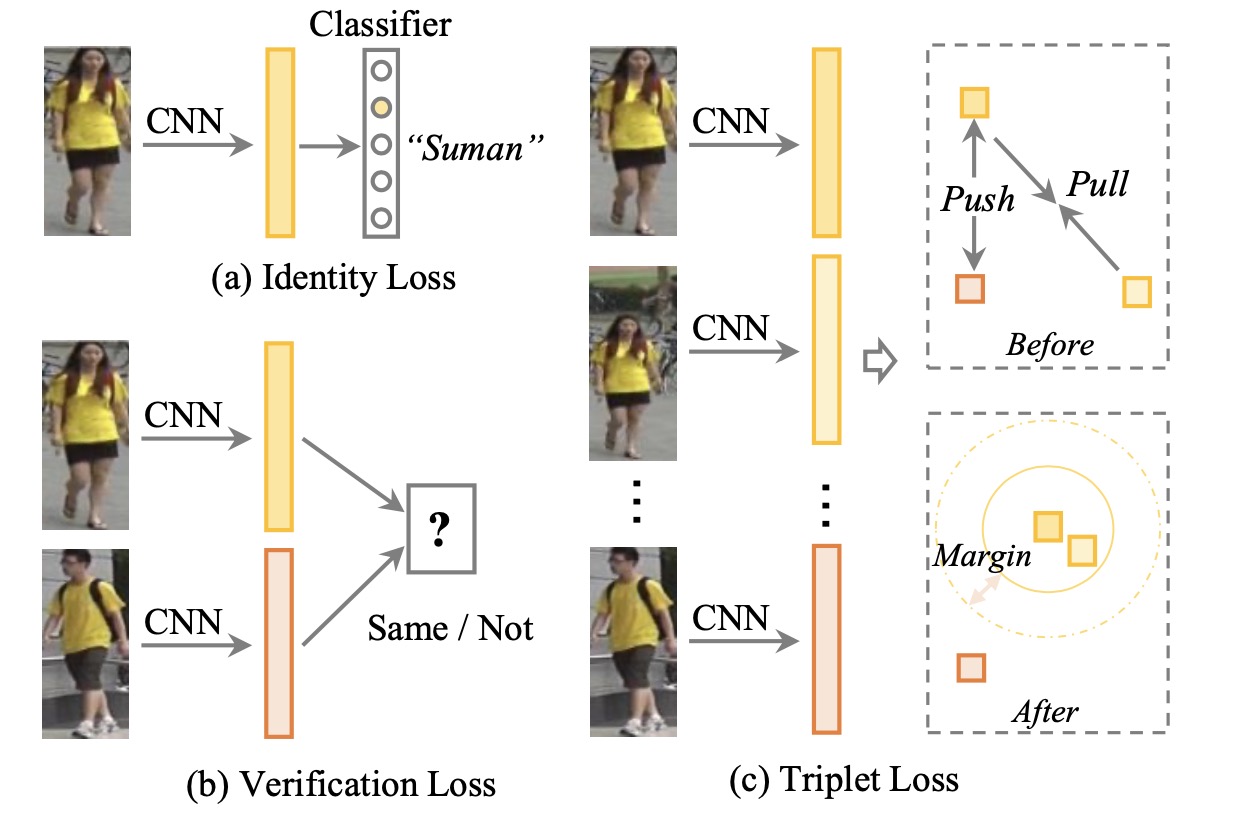
度量学习主要是设计loss函数指导特征表达学的更好.
- Identity Loss: 将reid 看做分类问题,每个 identity 是一个独立的类别。
- Verification Loss:将Re-ID的训练当成图像匹配问题,是否属于同一个行人来进行二分类学习,常见的有对比损失函数,二分类损失函数
- Triplet Loss:将Re-ID的训练当成图像检索排序问题,同一个行人图片的特征距离要小于不同行人的特征距离,以及其各种改进
- Training strategy:自适应采样,自适应损失加权
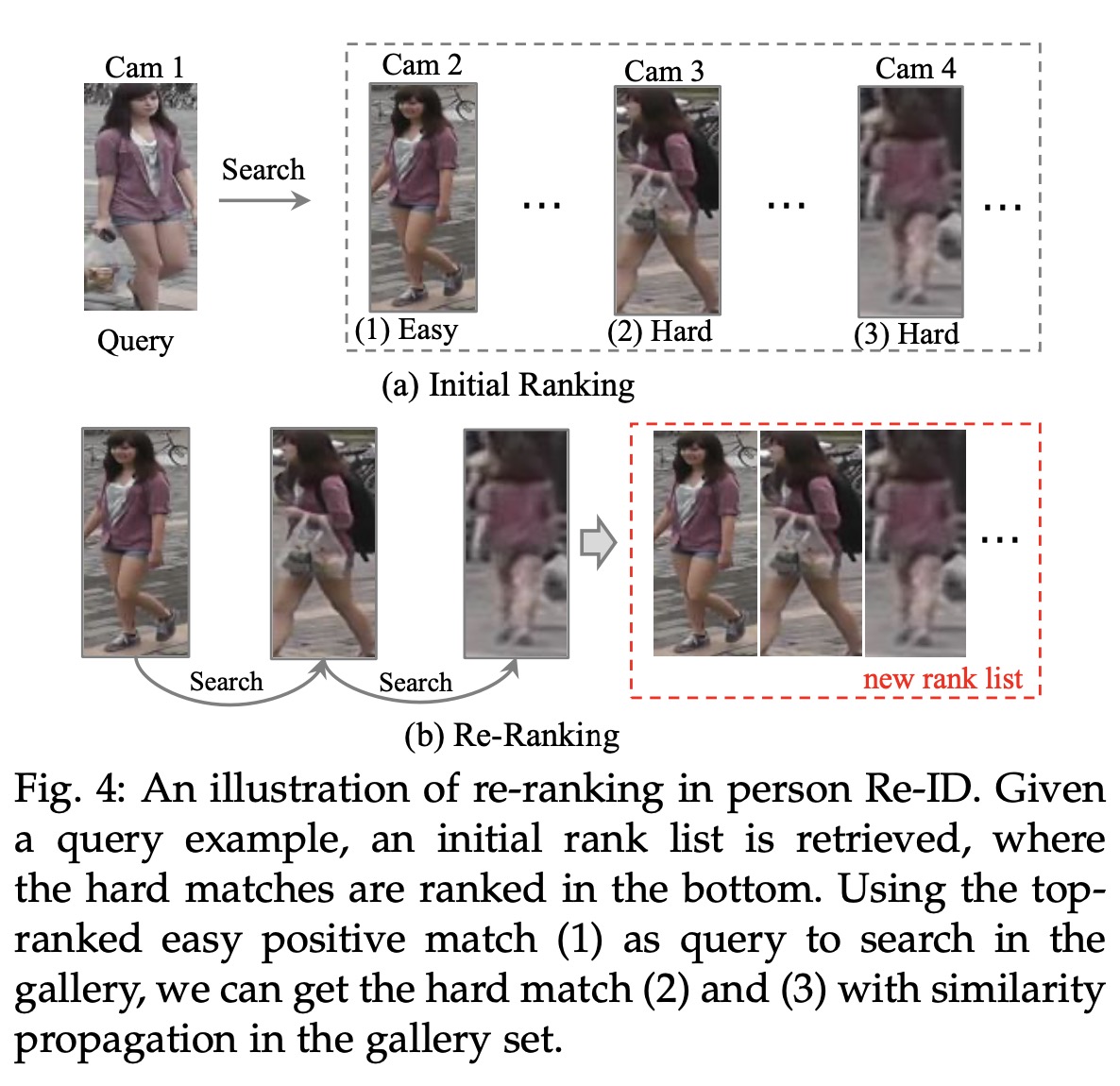
排序优化
用学习好的reid特征得到初始的检索排序结果后,利用图片之间的相似性关系来进行初始的检索结果优化,主要有:
- re-rank
- rank-fusion
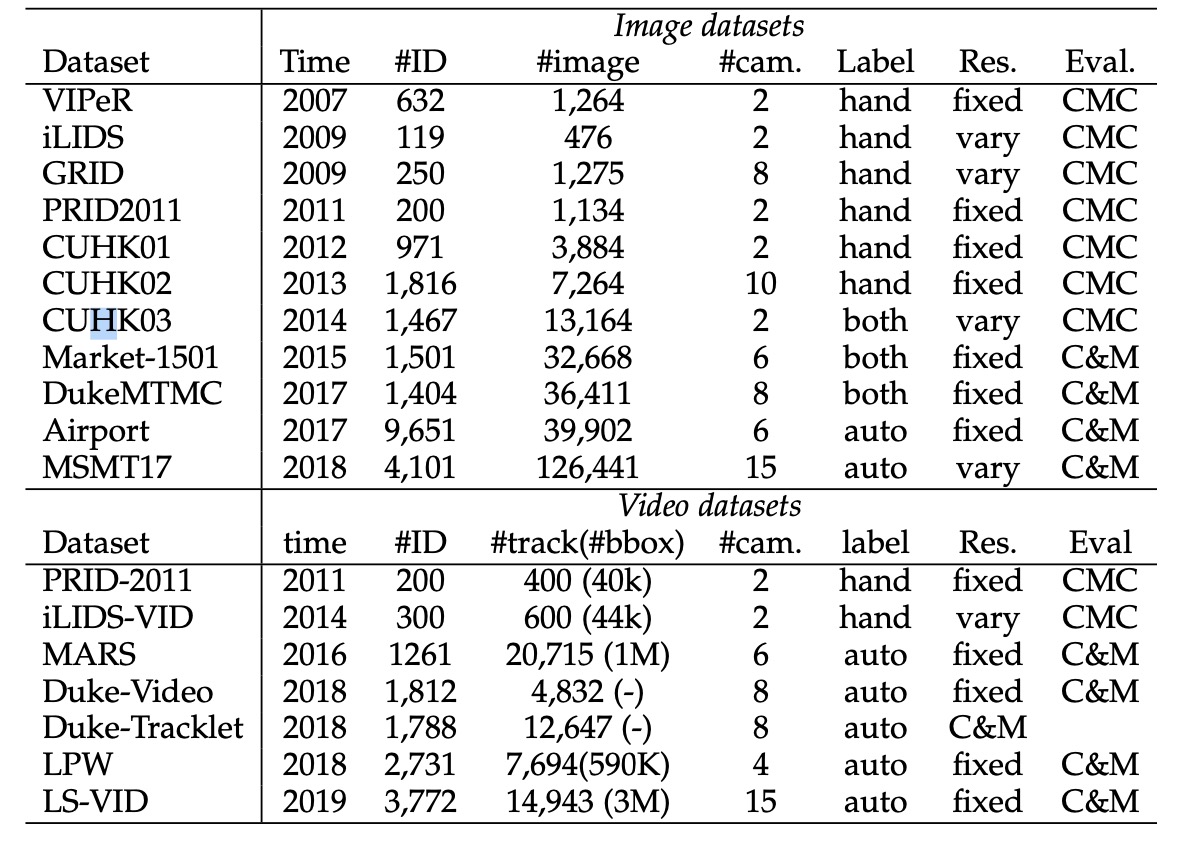
数据集
评价指标
reid 评价指标主要有:
- rank-k, 即检索结果中 top-k 的准确率
- mAP:
结语
从以下内容看来closed-world 的reid总体框架还是容易理解。接下来自己将根据使用到的代码、论文来记录reid学习过程.
REF
Deep Learning for Person Re-identification: A Survey and Outlook
