
object detection(1): Rcnn
Rcnn 作为使用CNN进行目标检测的开山之作, 之后,在其基础上延展出了fast rcnn, faster rcnn, mask rcnn, 等等, 都是在针对前人的问题不断改进, 本文对rcnn 进行小结.
主要贡献
- 使用CNN作为特征提取器进行目标检测
方法
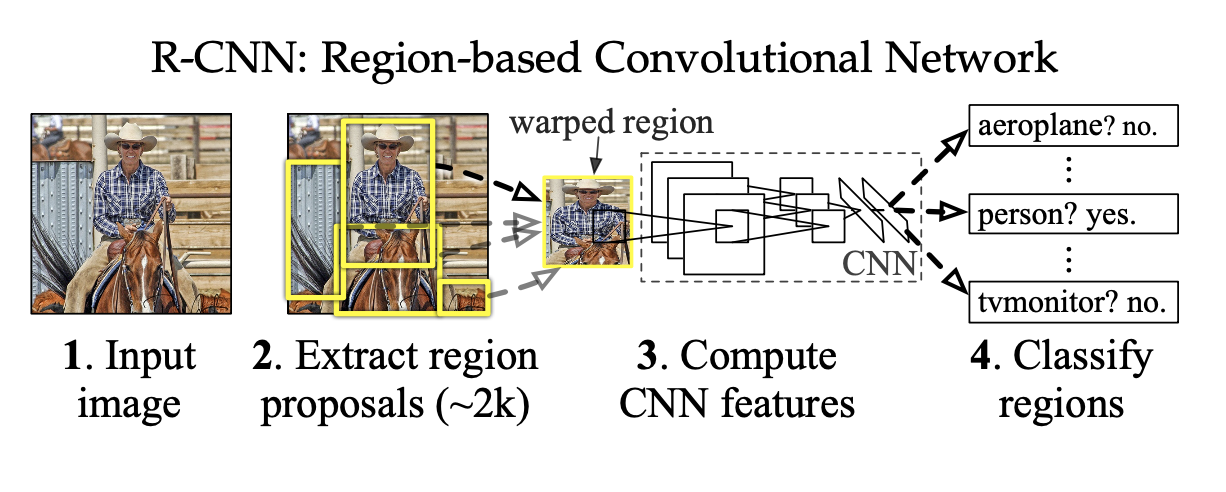
- 使用 SS 算法对图片进行 region proposal, 得到 2000 个候选的检测目标框
- 将得到的每个候选框 warp 到固定大小, 使用 Alexnet 进行特征提取, 抽取固定长度的特征向量
- 使用一系列指定类别的线性 svm 进行分类
- 使用一系列指定类别的 bounding box 回归器进行 bounding box 的校正
region proposals
region proposals 旨在根据图像特征, 对像素进行聚类, 生成可能的候选目标, 本文中作者使用的 Selective search 算法, 主要流程如下:
- 根据颜色相似性、纹理相似性、区域大小等特征, 将图像分割成很多小区域
- 采用自底向上的方法将分割的小区域合并成较大的区域
- 生成2000个左右的候选区域
Feature extraction
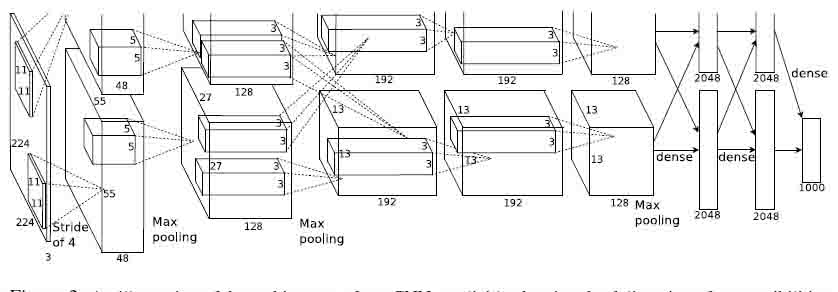
对于得到的每一个 region proposal, 使用 CNN 网络得到定长的特征向量(alexnet 为4096维, alexnet网络结构如上图所示, 去掉最后的分类层), 由于网络具有全连接层,所以网络对输入的尺寸有固定要求. 而得到 proposals 具有不同的尺寸, 文中粗暴的将其 warp 到要求的尺寸(warp 之前会将得到的初始box扩大16个像素).
对于特征提取器, 将网络最后的分类层替换为实际检测的类别(目标类别 + 背景), 使用 warp 图像来微调. 对所有 region proposals, 与GT 的 IOU 大于0.5, 均记为该图像中包含此类物体.
Object category classifiers
在提取到 CNN 特征后, 文中使用二分类 svm 对每个proposal 进行分类, svm 输入特征即为 CNN 得到的特征. 同时, 针对每个类别均训练一个 svm 分类器.
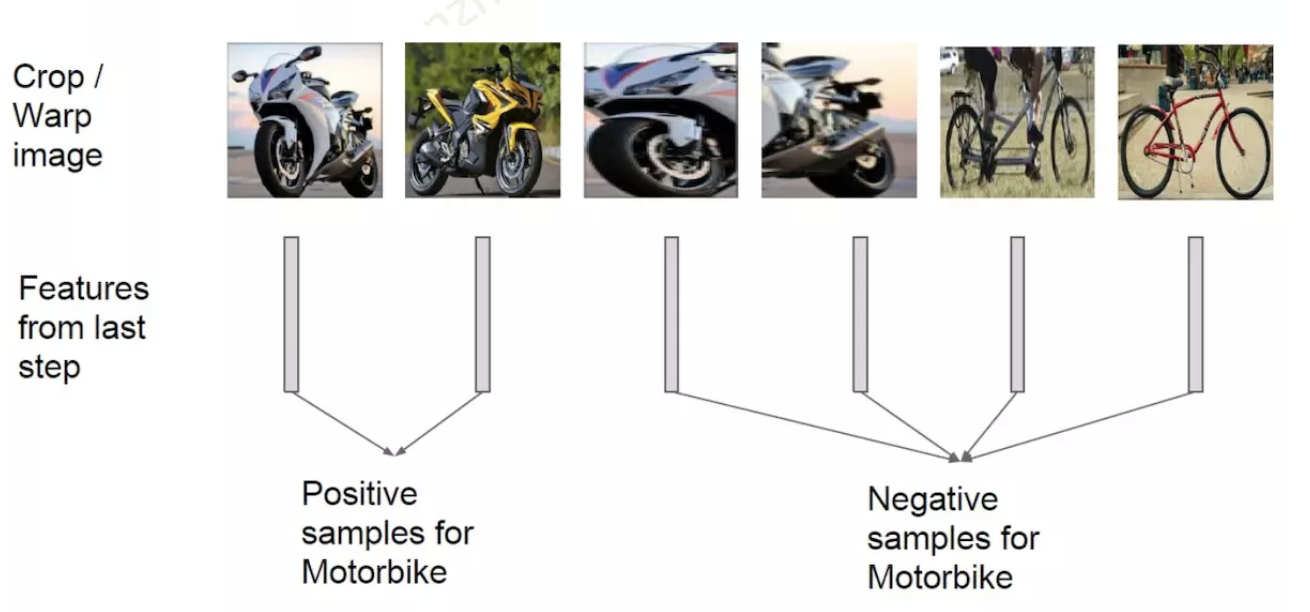
对于正负样本的选择, 针对部分包含同类样本的区域, iou 小于 0.3 均记为负样本.
测试阶段, 在 svm 分类器打分后, 使用 NMS 算法去掉冗余的区域子集.
Bounding-box regression

如上图所示, 红框为 SS 算法得到的 proposal, 绿框为实际目标框, 因此需要对 region proposals 进行校正.
记 $P =(P_x, P_y, P_w, P_h)$, 表示某 个 proposal 的中心坐标以及框宽和高. $G =(G_x, G_y, G_w, G_h)$ 为对应的 GT box.
根据以下变换将输入 proposal 转化为预测 $\bar G$:
$$ \bar G _x = P_w d_x(P) + P_x$$ $$ \bar G _y = P_h d_y(P) + P_y$$ $$ \bar G _w = P_w * exp(d_w(P))$$ $$ \bar G _h = P_h * exp(d_h(P))$$
前两项表示中心坐标的偏移值, 后两项为宽高的缩放比.
回归目标为:
$$W_* = argmin \sum ^N _i (t ^i _* - W ^T _* \psi _5 (P ^i))^2 + \lambda ||W _*|| ^2$$
其中, $\psi _5$ 是第五层池化层的特征. $W$ 是学习的参数向量. proposal坐标与GT坐标回归目标 $t _*$为:
$$t_x =(G_x - P_x)/P_w$$ $$t_y =(G_y - P_y)/P_h$$ $$t_w =log(G_w / P_w)$$ $$t_h =log(G_h / P_h)$$
rcnn 存在的不足
- warp 操作可能会使物体失真
- 每个候选区域都单独进行特征提取, 耗费时间空间, 且存在重复提取
- 不是端到端, 相当于多个算法级联在一起. 且训练繁琐.
rcnn 像是一个大杂烩, 更像是多个算法拼起来. 有不足才能有进步, fast rcnn 与 faster rcnn 则针对存在的不足进行了优化设计.

