
监督分类之:KNN算法
KNN简介
K近邻(K-Nearest Neighbor)学习是一种简单的监督学习方法。方法流程主要是:对于给定的测试样本,基于某种距离度量找出训练集中与其最靠近的K个样本,根据这K个样本的类别来决定测试样本的类别,一般采用投票法,即判别为K个中出现次数最多的类别。(这种思路很早就知道了,完全不觉得这也属于高大上的机器学习啊,明明没有‘’学习‘’啊)。 所以,KNN是‘懒惰学习’的代表:无训练时间开销。相对的,训练阶段进行学习处理的为‘急切学习’,显然,大部分的机器学习方法都属于后者,比如:SVM,DNN,LR等。
KNN示例
假设训练样本为两类二维样本,红色的 +,和绿色的-。蓝色的点为测试样本
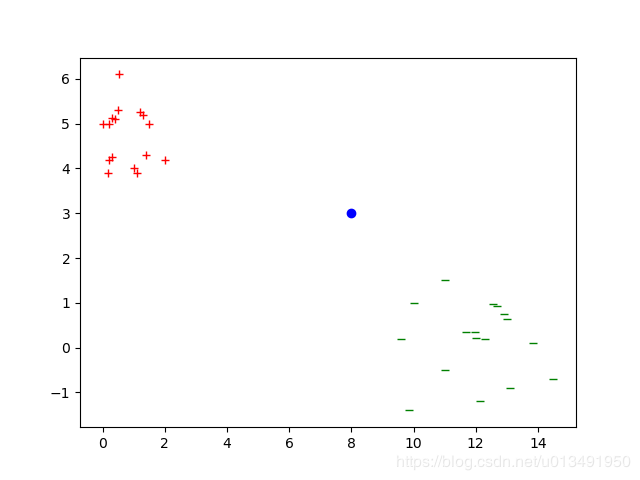 KNN分类需要定义相似性度量函数,对于本例二维点可以采用欧氏距离函数作为判别,计算测试点到所有样本点的距离,选取前K个判断类别。
KNN分类需要定义相似性度量函数,对于本例二维点可以采用欧氏距离函数作为判别,计算测试点到所有样本点的距离,选取前K个判断类别。
对于KNN,找到合适的距离度量函数很重要,同时,K值的选取对结果也起着很大的作用。
当K小时,只有最靠近输入实例的训练实例对预测结果起作用,也容易过拟合,导致高方差; 当K很大时,与输入实例不相似的训练实例对训练结果也起作用,会导致高的偏差
总体流程如下: 1. 计算训练集中的每个样本与测试样本的距离 2. 将距离按地址排序 3. 选取与当前测试样本距离最小的K个样本 4. 计算K个样本所属类别出现的频率 5. 选取频率最高点的所属类别为预测分类
基于KNN的mnist数据集分类
mnist手写数字数据集包含(0-9)10个类别的手写数字 ,训练集有55000张图片,测试集有1万张图片,可视化部分结果如下:
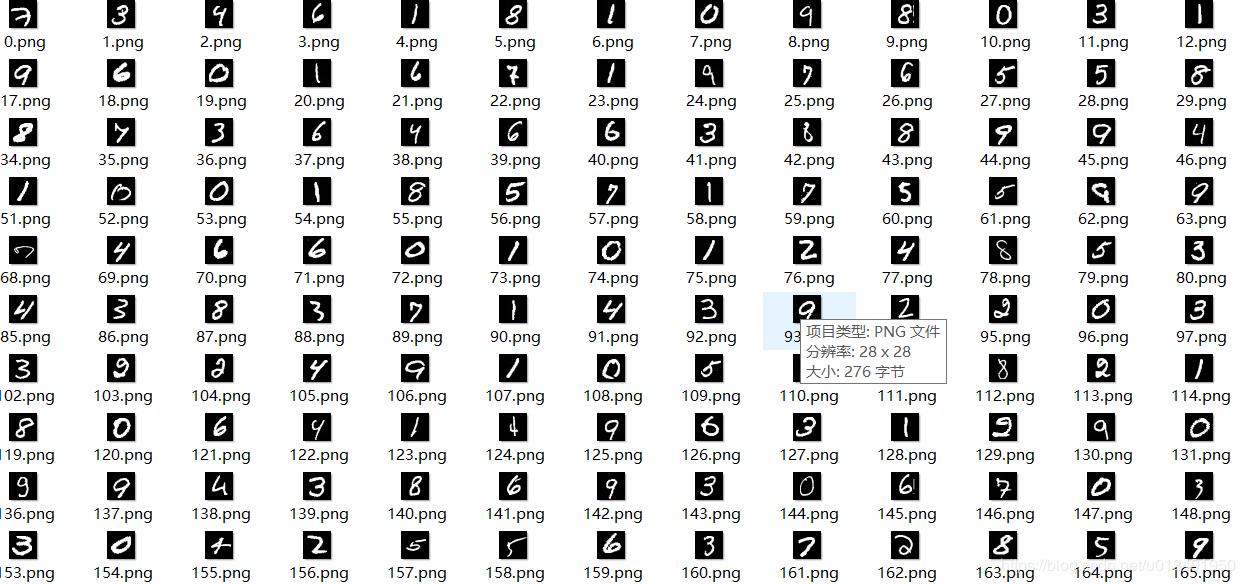
使用的图片数据是将图片转换为行向量之后的数据(数据来源TensorFlow里tutorials.mnist里的数据),数据已进行归一化(即像素值/255)。
TensorFlow环境下代码
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import time
class Knn():
def classMnist(self,sample,train_data,train_label,k = 10):
dataRows = np.shape(train_data)[0]
sampleRep = np.tile(sample,(dataRows,1)) # 将测试样本变为和训练集一样大小的数组,不用循环计算
distance = np.sqrt(np.sum(np.power(sampleRep - train_data,2),axis=1)) # 采用欧式距离
sortIndex = np.argsort(distance)
countClass = {}
for i in range(k):
label = train_label[sortIndex[i]][0]
if str(label) in countClass:
countClass[str(label)] = countClass.get(str(label)) + 1
else:
countClass[str(label)] = 1
return list(zip(countClass.values(),countClass.keys()))[0][1]
test = Knn()
mnist = input_data.read_data_sets('MNIST_data/',one_hot=False) #载入数据,类别标签非one-hot vector
train_data = mnist.train.images[0:55000,:]
train_lab = np.reshape(mnist.train.labels[0:55000],[55000,1]) #reshape 为 array
test_data = mnist.test.images[0:10000,:]
test_lab = mnist.test.labels[0:10000]
equ = 0 # 统计预测对的个数
begin = time.time() # 计时
for i in range(len(test_data)):
im_vec = test_data[i,:]
im_lab = test_lab[i]
pre = test.classMnist(im_vec,train_data,train_lab)
print('the label is: '+ str(im_lab)+'; the classification result :' +str(pre))
if int(pre) == im_lab:
equ = equ + 1
print(equ/len(test_data))
end = time.time()
print(end-begin)
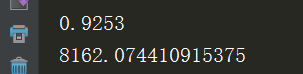
实验中,设置的10近邻,最终精度达到:
后记
KNN算法由于每次都要和整各训练集做比较,当样本很大时,时间空间复杂度比较比(主要还是从时间效率考虑)。在KNN基础上,推出了K-d树,尤其当训练数据量远大于样本特征维度时,效率很高。
