
East:An Efficient and Accurate Scene Text Detector阅读及应用
East是旷视科技2017年发表的论文,针对于场景文本检测。East网络也可以轻易的扩展到其他目标检测任务上。我主要在改进版的East基础上做手机号码检测与识别,以及之前的基于yolo的水印检测。
Overview
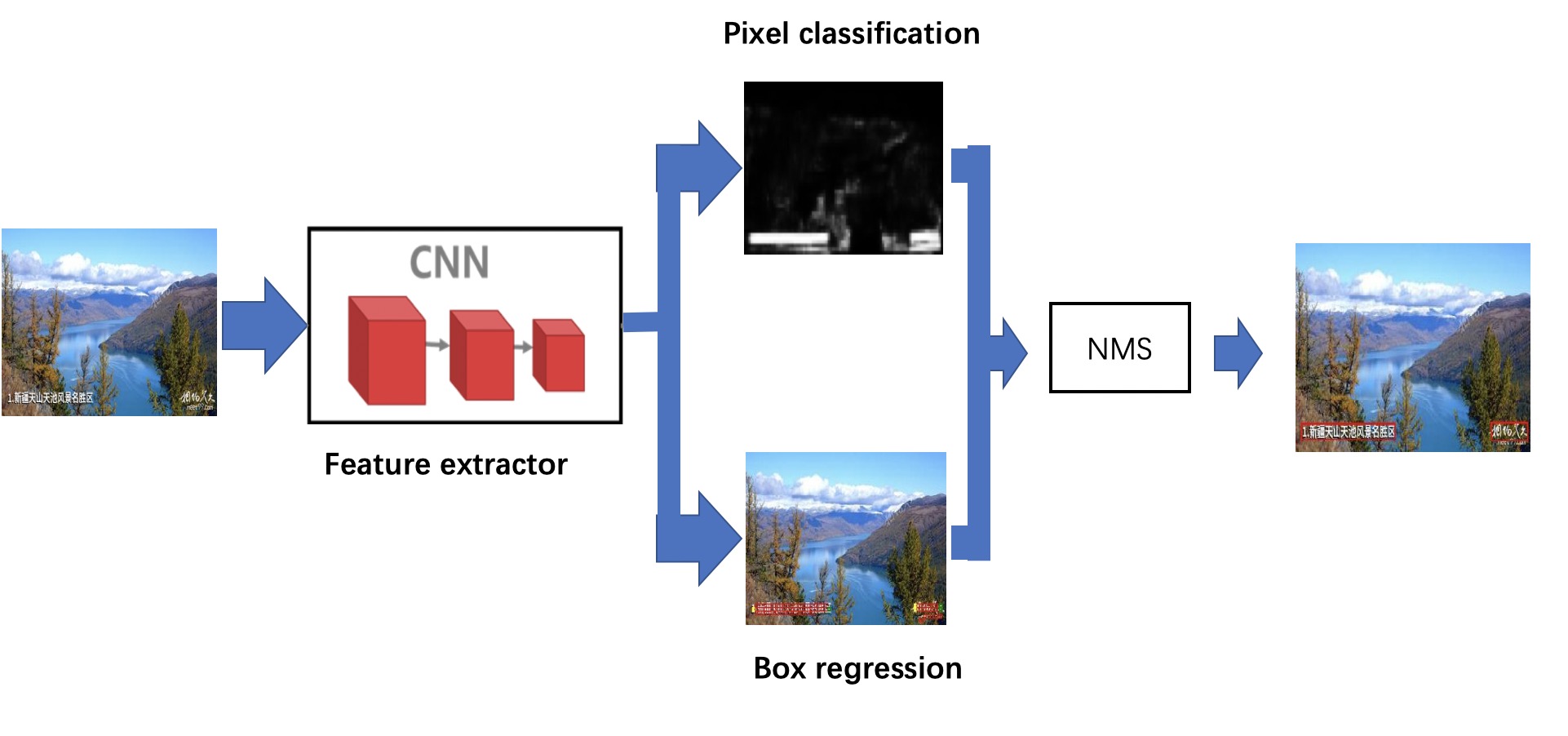
East的检测流程如图所示,类似于maskRCNN,一个分支做像素级语义分割(二分类(文本框与背景),另一个分支做box的回归。然后NMS得到最终的目标框。
网络结构
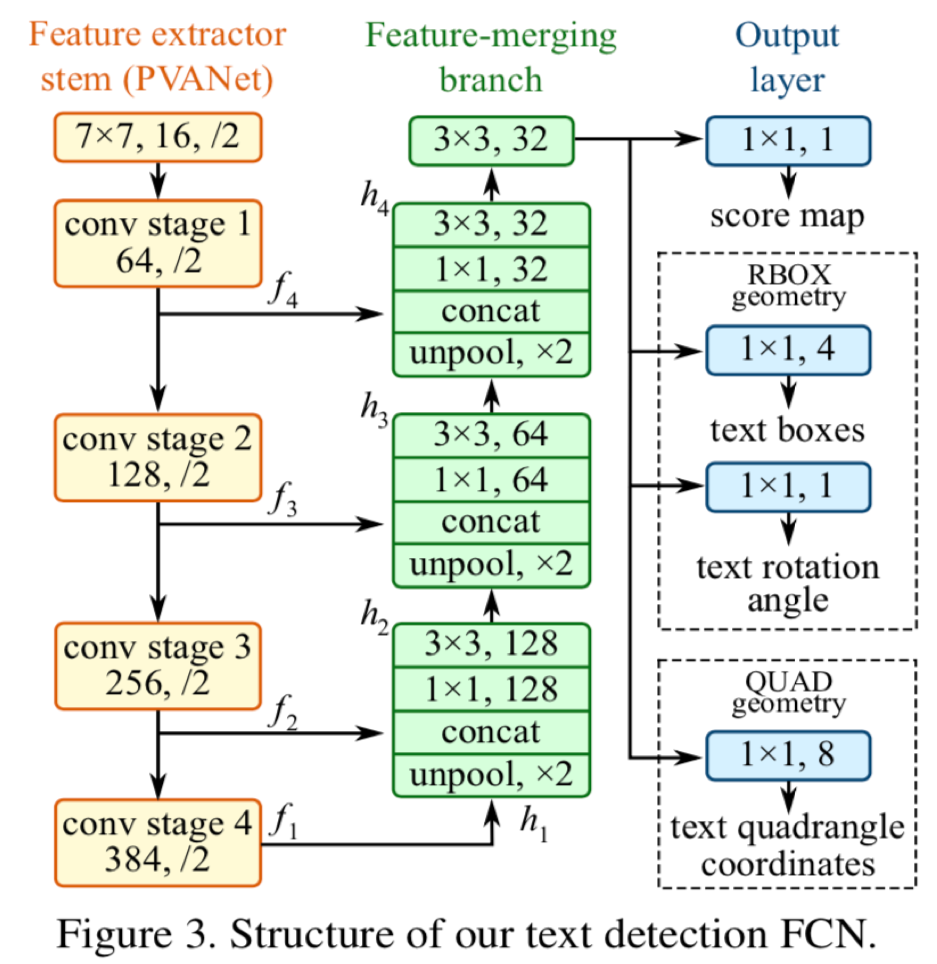
- 采用PVA net做特征提取, 然后又是标准的语义分割步骤,上采样以及跨层连接实现高层特征与低层特征融合。
对于网络的输出,首先输出单通道的score-map,每个点是否属于文本的概率。对于box回归,作者设计了两种方式,一种是RBOX,二是QUAD。
RBOX:d1,d2,d3,d4,r。分别代表每个像素点到文本框各个边的距离,r代表预测的旋转角度。
QUAD:(x1,y1;x2,y2;x3,y3;x4,y4)。这种方式为每个像素点直接预测框的四个坐标(难度大)。
label 生成
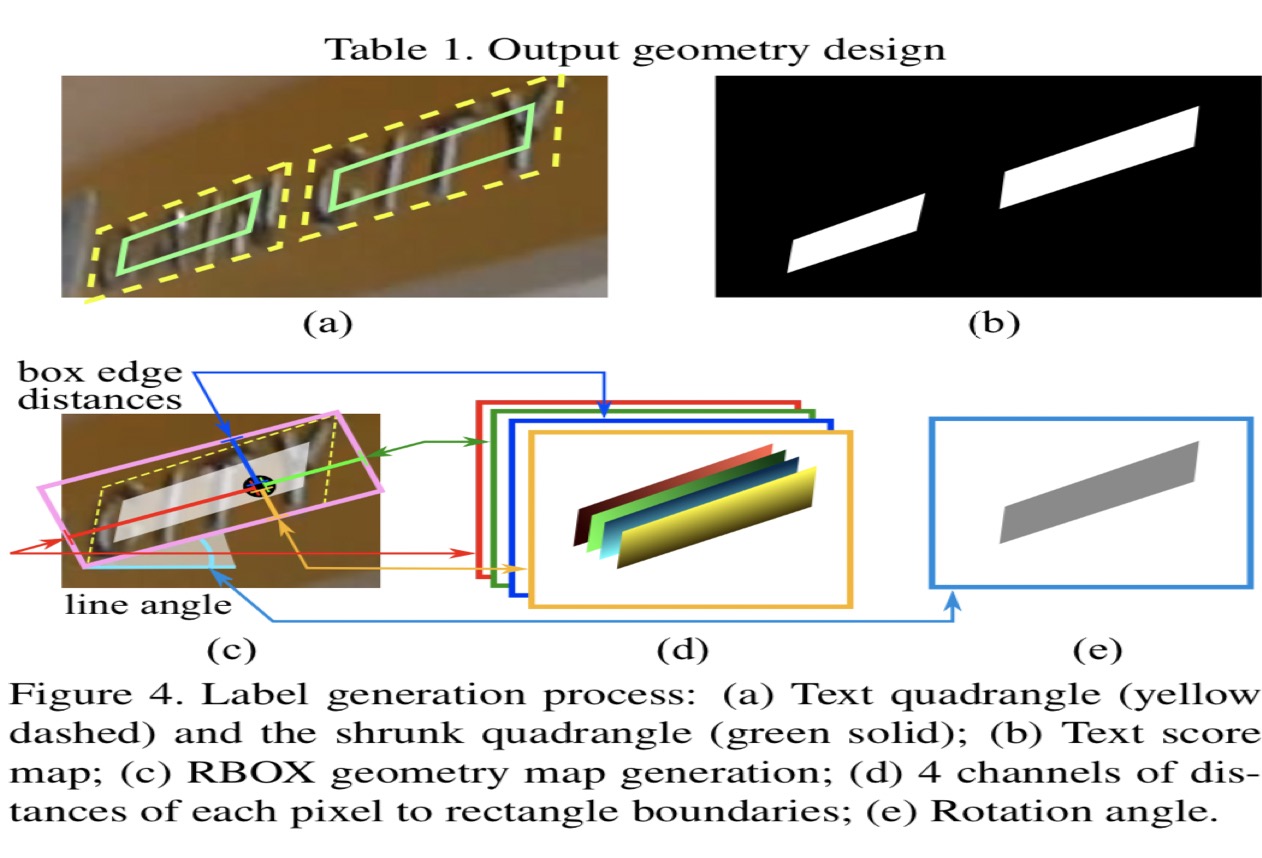
如图中a所示,首先对人工的框进行缩放消除人工误差。对于像素级分割则生成b中所示的GT。生成以最小面积覆盖区域的旋转矩形,并计算每个像素点到旋转举行四条边的距离放到四个通道里。以及旋转角度为一个通道。
损失函数

对于像素级分割采用平衡交叉熵损失,对于RBOX作者设计了IOU损失以及角度的cosine损失,QUAD在采用了smoothed L1损失。
advancedEAST
East对长文本检测效果欠佳(个人认为是由于文本跨度太长会导致中间部分像素预测不准)。在East的基础上,网上的大神对East的输出结构进行了改进。
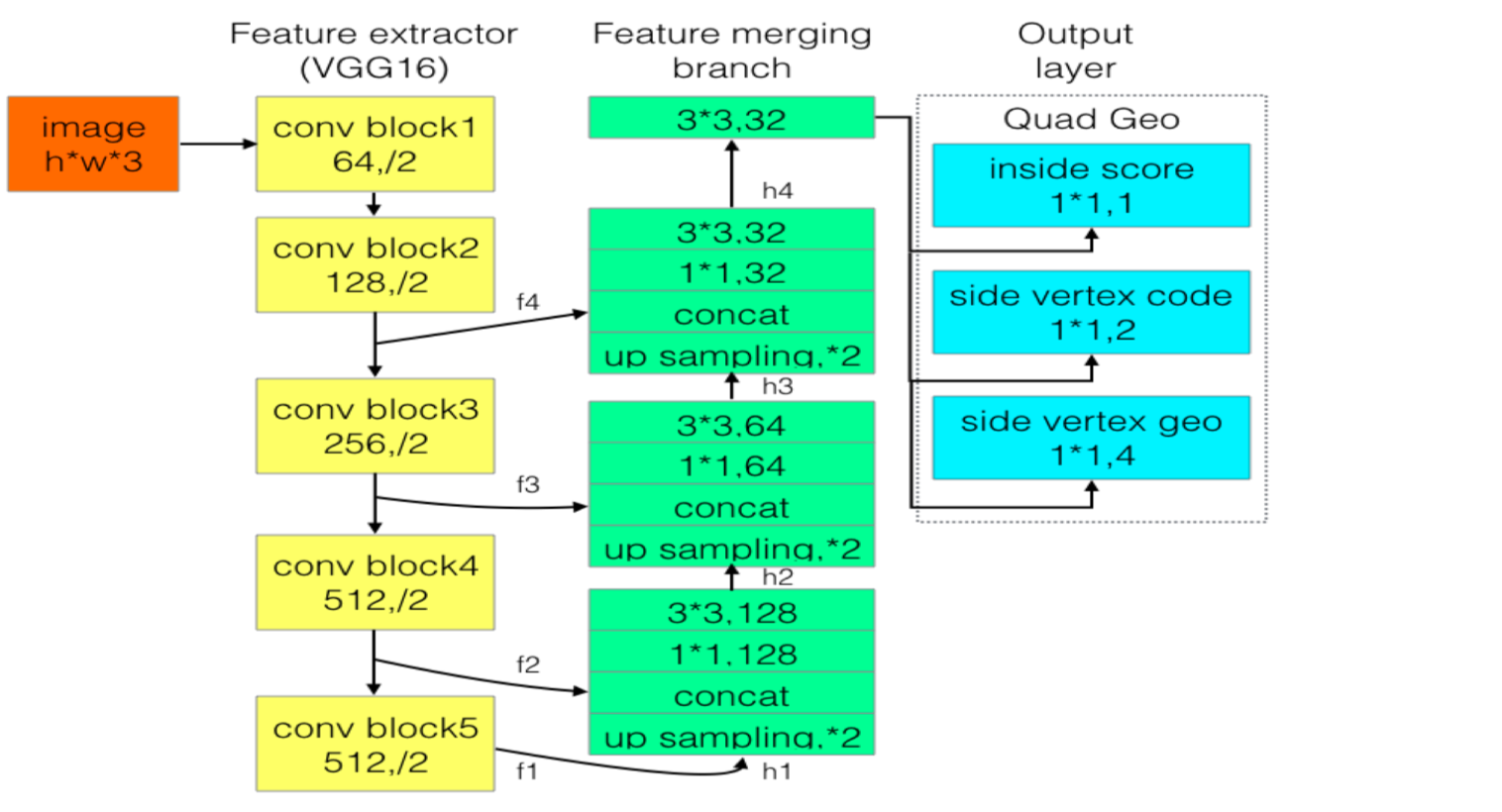
特征提取器没有太大的影响。作者主要修改了输出层,修改为7通道的输出。如下图:

此时做box的回归预测不再是所有像素参与,仅使用边界像素去预测相邻的两个坐标。输出层分别是1位score map, 是否在文本框内;2位vertex code,是否属于文本框边界像素以及是头还是尾;4位geo,是边界像素可以预测的2个顶点坐标。所有像素构成了文本框形状,然后只用边界像素去预测回归顶点坐标。边界像素定义为黄色和绿色框内部所有像素,是用所有的边界像素预测值的加权平均来预测头或尾的短边两端的两个顶点。头和尾部分边界像素分别预测2个顶点,最后得到4个顶点坐标。
advancedEAST后处理过程:
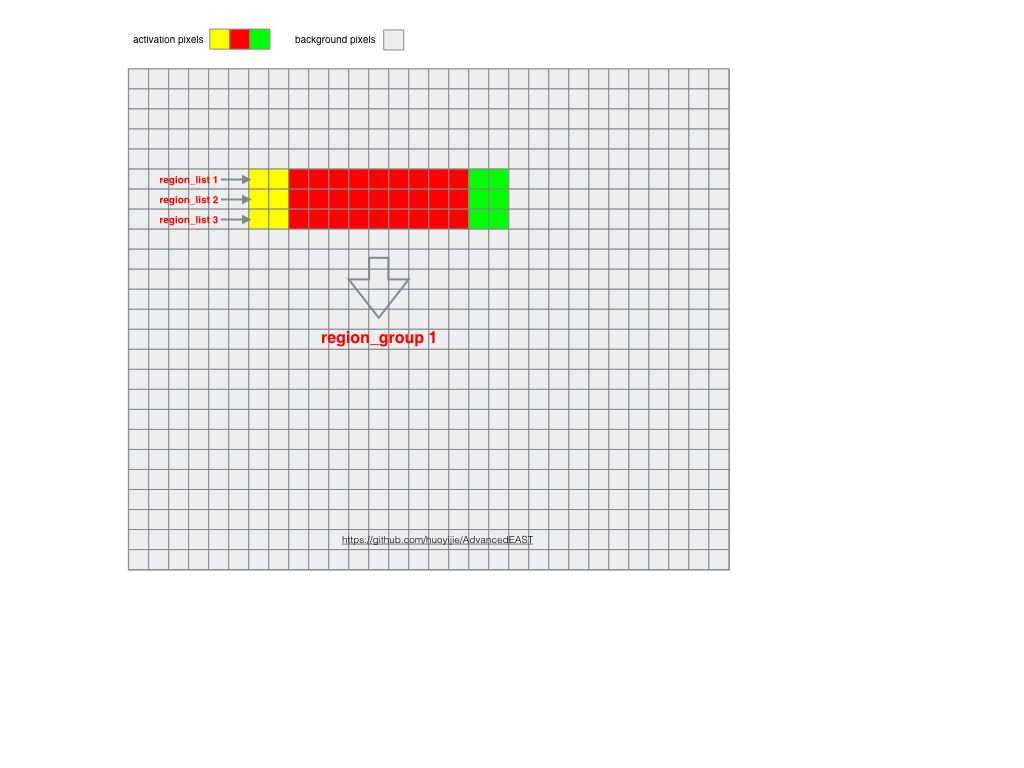
- 1.由预测矩阵根据配置阈值得出激活像素集合
- 2.左右邻接像素集合生成region list集合
- 3.上下邻接region list组成region group(文本框激活区域)集合
- 4.遍历每个region group,生成其头和尾边界像素集合,
5.根据头和尾边界像素预测的到顶点Delta值与该边界像素坐标值计算顶点坐标,每个顶点的所有预测值的加权平均值作为最后的预测坐标值,并输出score
# coding=utf-8 import numpy as np import cfg def should_merge(region, i, j): # 判断两个激活点坐标是否邻接 neighbor = {(i, j - 1)} return not region.isdisjoint(neighbor) def region_neighbor(region_set): # 根据当前region list 的坐标生成下一行的region list应该包含的的坐标点, 且左右边界分别列减一与加一 # 例:当前region list 的region_set{(50, 24),(50, 25)} # 那么下一行的它的下一行的neighbor 为 {(51, 23), (51, 24), (51, 25), (51, 26)} region_pixels = np.array(list(region_set)) j_min = np.amin(region_pixels, axis=0)[1] - 1 j_max = np.amax(region_pixels, axis=0)[1] + 1 i_m = np.amin(region_pixels, axis=0)[0] + 1 region_pixels[:, 0] += 1 neighbor = {(region_pixels[n, 0], region_pixels[n, 1]) for n in range(len(region_pixels))} neighbor.add((i_m, j_min)) neighbor.add((i_m, j_max)) return neighbor def region_group(region_list): # region list 按上下行是否邻接合并 S = [i for i in range(len(region_list))] D = [] while len(S) > 0: m = S.pop(0) if len(S) == 0: # S has only one element, put it to D D.append([m]) else: D.append(rec_region_merge(region_list, m, S)) return D def rec_region_merge(region_list, m, S): rows = [m] tmp = [] for n in S: # 判断region list 是否邻接,邻接就合并, 以下分别判断region list[m]的行坐标小于n 或 n的行坐标小于m if not region_neighbor(region_list[m]).isdisjoint(region_list[n]) or \ not region_neighbor(region_list[n]).isdisjoint(region_list[m]): # 第m与n相交 tmp.append(n) for d in tmp: S.remove(d) for e in tmp: rows.extend(rec_region_merge(region_list, e, S)) return rows def nms(predict, activation_pixels, threshold=cfg.side_vertex_pixel_threshold): # 区域list region_list = [] for i, j in zip(activation_pixels[0], activation_pixels[1]): merge = False for k in range(len(region_list)): # 对于每一对激活像素坐标,与region list 中的每一个region比较,行相邻就合并 if should_merge(region_list[k], i, j): region_list[k].add((i, j)) merge = True # Fixme 重叠文本区域处理,存在和多个区域邻接的pixels,先都merge试试 # break if not merge: region_list.append({(i, j)}) D = region_group(region_list) # 记录四边形坐标, shape(四边形个数, 4个顶点, 每个顶点2个坐标) quad_list = np.zeros((len(D), 4, 2)) score_list = np.zeros((len(D), 4)) for group, g_th in zip(D, range(len(D))): total_score = np.zeros((4, 2)) for row in group: for ij in region_list[row]: # 边界像素? score = predict[ij[0], ij[1], 1] if score >= threshold: # 头or尾? ith_score = predict[ij[0], ij[1], 2:3] # 制作GT时头为0, 尾部为1. 小于trunc_threshold 为头, 大于 1- trunc_threshold 为尾 if not (cfg.trunc_threshold <= ith_score < 1 - cfg.trunc_threshold): ith = int(np.around(ith_score)) total_score[ith * 2:(ith + 1) * 2] += score # 激活图上坐标*感受野大小得到对应到原图的坐标 px = (ij[1] + 0.5) * cfg.pixel_size py = (ij[0] + 0.5) * cfg.pixel_size # 当前点坐标加上 距离左上、左下 or 右上、右下的坐标差即得到左上、左下 or 右上、右下坐标 p_v = [px, py] + np.reshape(predict[ij[0], ij[1], 3:7], (2, 2)) # 更新对应四边形的左上、左下 or 右上、右下坐标, 值为累计的加权和 quad_list[g_th, ith * 2:(ith + 1) * 2] += score * p_v #四边形的最终坐标为所有预测坐标的加权求和 / 权值和 score_list[g_th] = total_score[:, 0] quad_list[g_th] /= (total_score + cfg.epsilon) return score_list, quad_list
应用
- 1. 水印检测。训练集为算法合成水印,测试集为真实水印。水印召回接近90%,非水印图片检测为水印图片率为2%。待改进训练方式以及尝试加入attention机制。

- 2.下一步手机号码检测识别。
