
Anchor free目标检测修炼之路:fcos -Fully Convolutional One-Stage Object Detection
主流的目标检测算法大多数是基于anchor box的, one-stage 的yolo-v2, yolo-v3, ssd…以及two-stage 的faster rcnn等. 但是引进了anchor超参数, 训练也不太容易. anchor free 的论文之前也有, 比如 yolo-v1, 旷视的用于文本检测的EAST. 由于各种原因, anchor based 的方法大行其道. 然而,2019年目标检测的论文有好些 Anchor free的论文, 不知道是不是anchor的很难再出大的改进了. 今天对其中的FCOS进行一个学习与总结
创新点
- 无需 proposal, 无需 anchor box, 减少超参数
- 将目标检测以 per-pixel 的形式实现, 与其它使用FCN的任务可以方便的联合
- one-stage, 超过主流的SSD, yolo-v3, retinanet等算法
方法
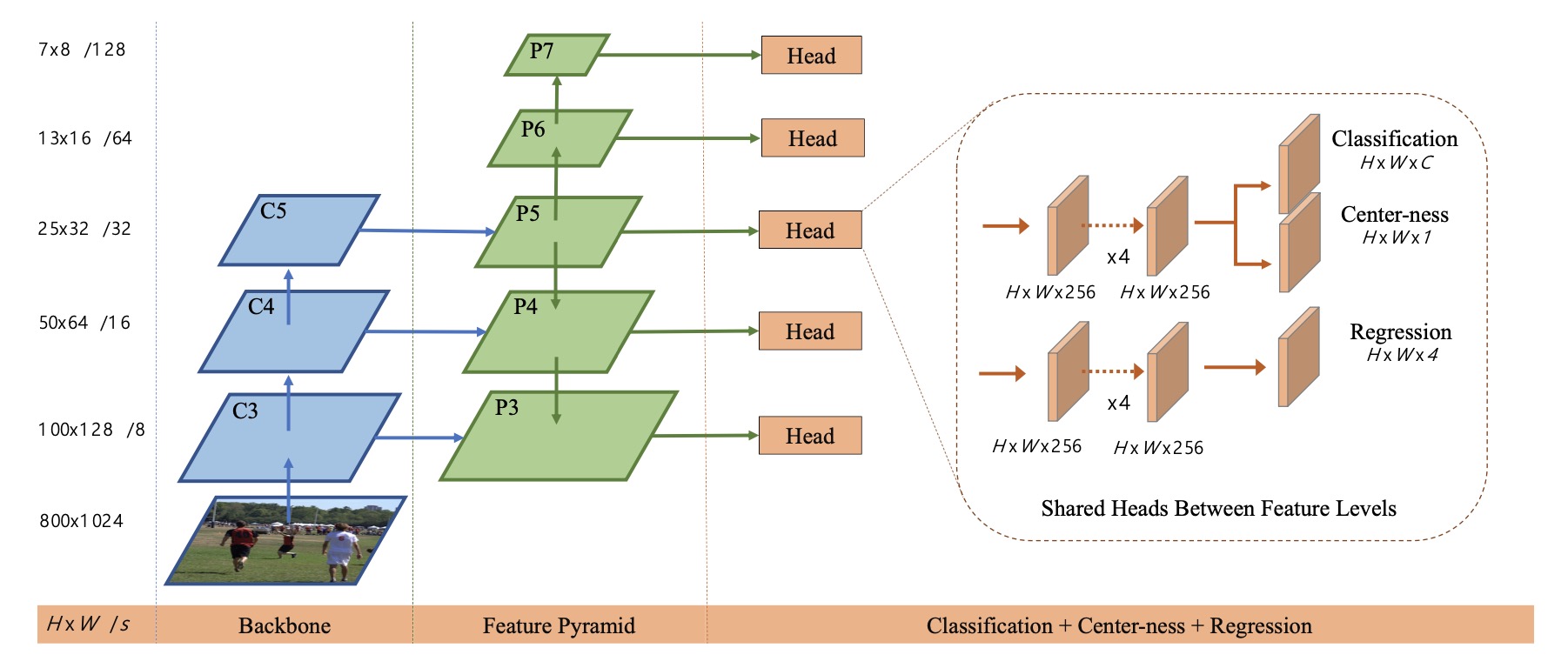
算法的整体框架如上图所示, 主干网络是 FPN结构, 在多个尺度下进行预测, 每个尺度下分类与回归头共享.
gt 生成

GT bounding box 为 $B _i = (x _0 ^{(i)}, y_0 ^{(i)}, x_1 ^{(i)}, y_1 ^{(i)}, c^{(i)})$, 分别为左上和右下角坐标, c 为类别.
对于某一级总下采样倍数为 $s$ 的 feature map 上的位置 $(x, y)$, 将其映射回原图 $(⌊s/2⌋ + x * s, ⌊s/2⌋ + y * s)$ , 这样做能尽量让 feature map 上的每个点对应到其映射回原图感受野的中心. 如下采样32, feature map 上每个点对应于原图为 32 * 32 的区域, $(0, 0 )$ 映射回原图为 $(16, 16)$, 位于感受野区域的中心.
对于正负样本的标记, feature map 上位置 $(x, y)$ 映射回去若落在任意 GT 内, 则该位置的类别标记为 GT 的类别. 否则为 0. 对于坐标回归, 计算当前点与gt box 四条边的距离, 当前位置的训练回归目标公式化为:
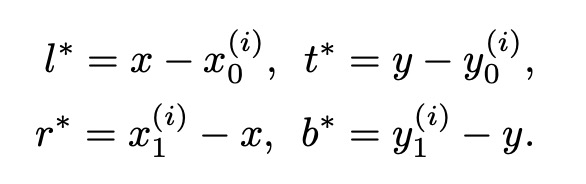
如果一个位置落在了多个目标内, 那么选择 bounding box 面积最小的作为回归目标. 如上图所示
网络输出
网络输出通道为类别数$C$ 加左上右下两个坐标即四个通道以及额外可添加的 center ness 的单通道输出. 对于分类器, 采用训练 $C$ 个二分类器. 回归头输出 $t = (l, t, r ,b)$, 可根据当前点坐标得到 bounding box.
损失函数
对于分类头使用 focal loss, 回头头使用 iou loss.
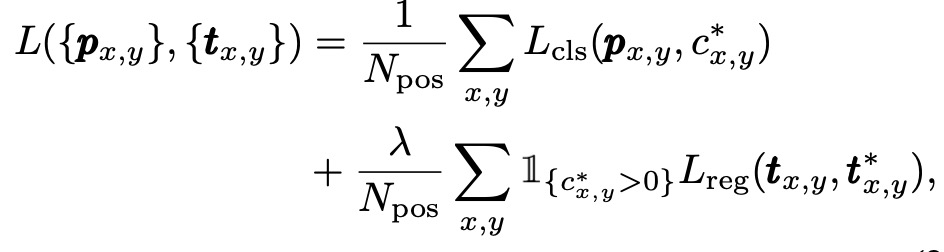
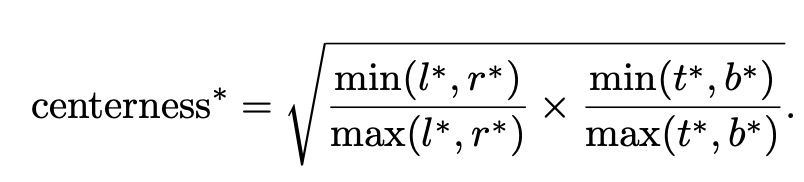
对于上式值为0,1之间, 处于物体正中心时值为1, 使用交叉熵损失进行训练。并把损失加入前面提到的损失函数中. 测试时,将预测的中心度与相应的分类分数相乘
result
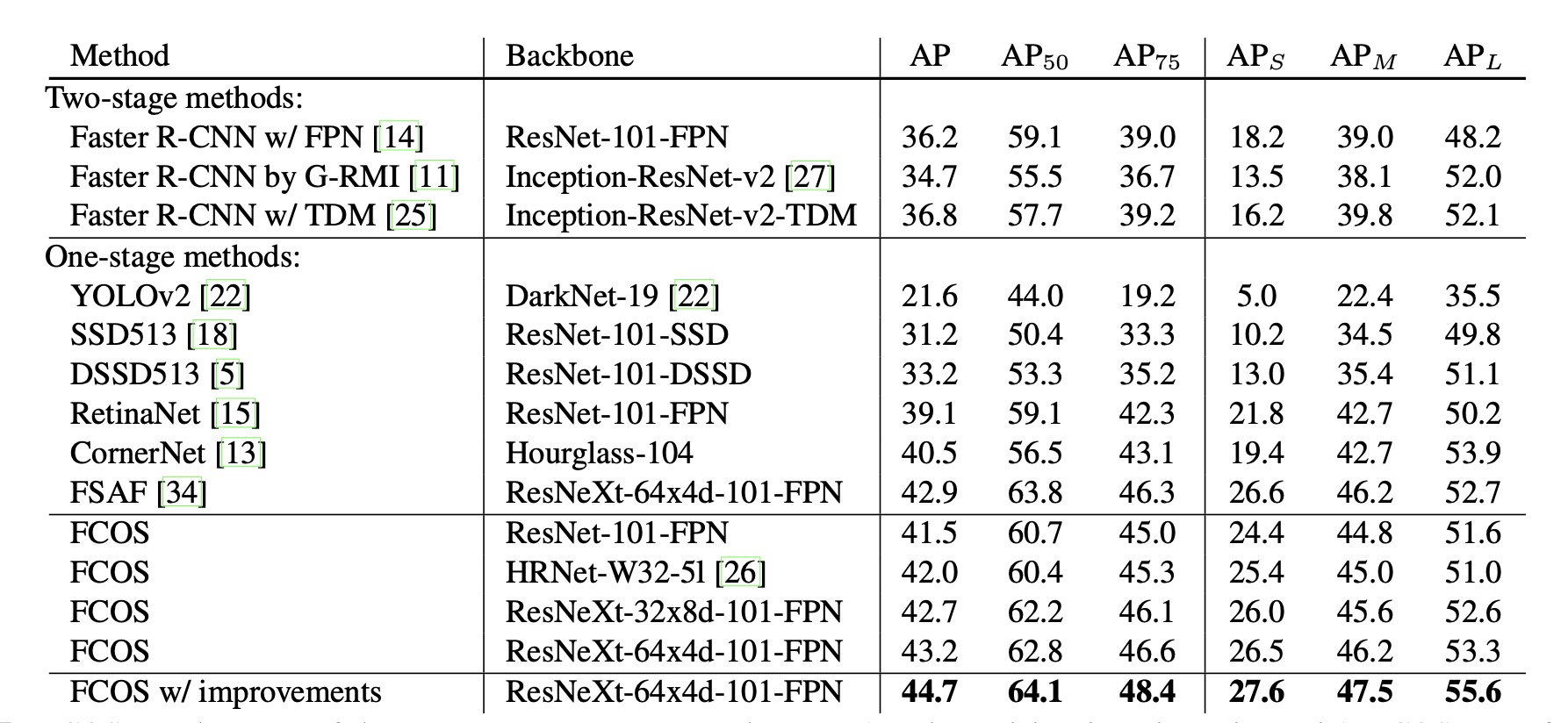
上图为和主流算法的对比, 可以看出由于sota算法
