
语义分割: deeplab V1到deeplab V3
deeplab 为一个系列, 因此将其放在一起进行个回顾
Deeplab-v1 与deeplab-v2
将deeplab-v1与deeplab-v2放在一起, 主要是因为二者总体结构很接近, v1主要是关于空洞卷积与使用全连接的条件随机场有关全连接的CRF应用于图像分割请详见我之前的文章, v2引进SPPnet的思想,引入ASPP技术.
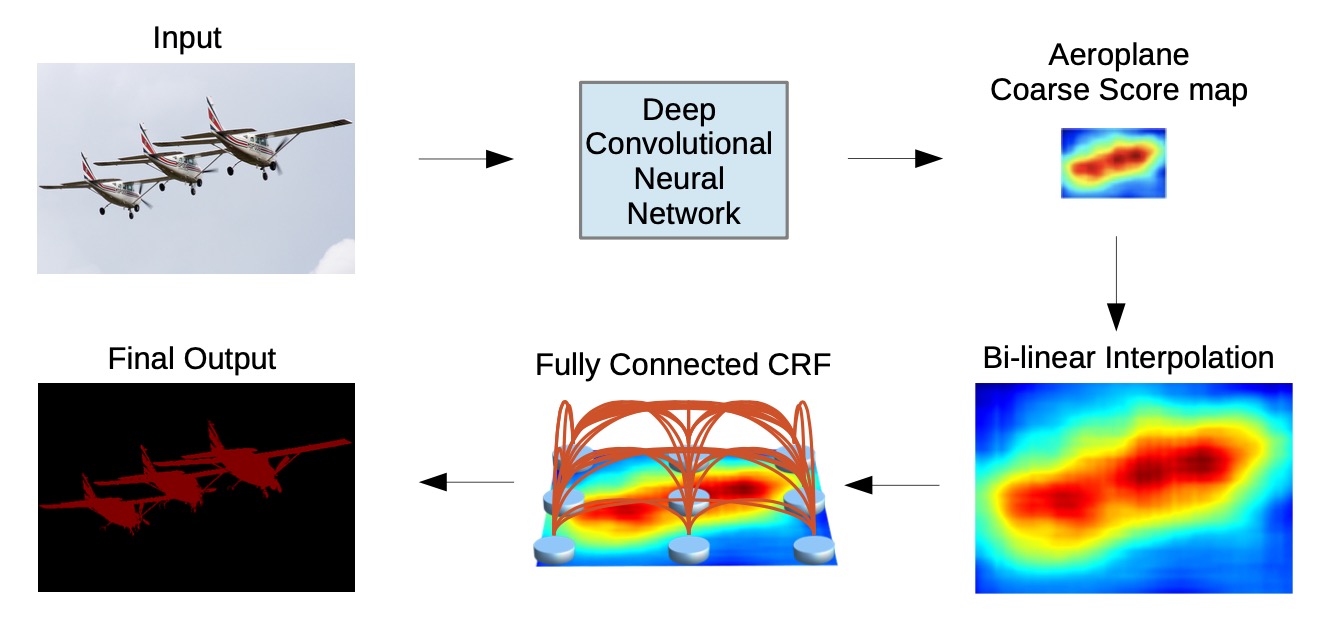
deeplav-v1与deeplab-v2总体结构如上图, 输入图片经过卷积神经网络得到粗糙的score-map(此时为原图8倍下采样,相对于FCN而言,同VGG16backbone情况下, FCN最深层得到特征图大小32倍下采样), 然后经过插值得到原图大小的score-map, 然后使用全连接的CRF得到更精细的分割结果.
deeplab-v1与deeplab-v2的分割流程与FCN整体相似, deeplab-v1 使用VGG作为backbone, deeplab-v2使用resnet作为backbone, 区别在于下采样之后deeplab-v1使用Atous卷积, v2进一步使用了ASPP.
Atous卷积
称为空洞卷积或膨胀卷积, 按字面意思理解即是对卷积核进行填0扩张.
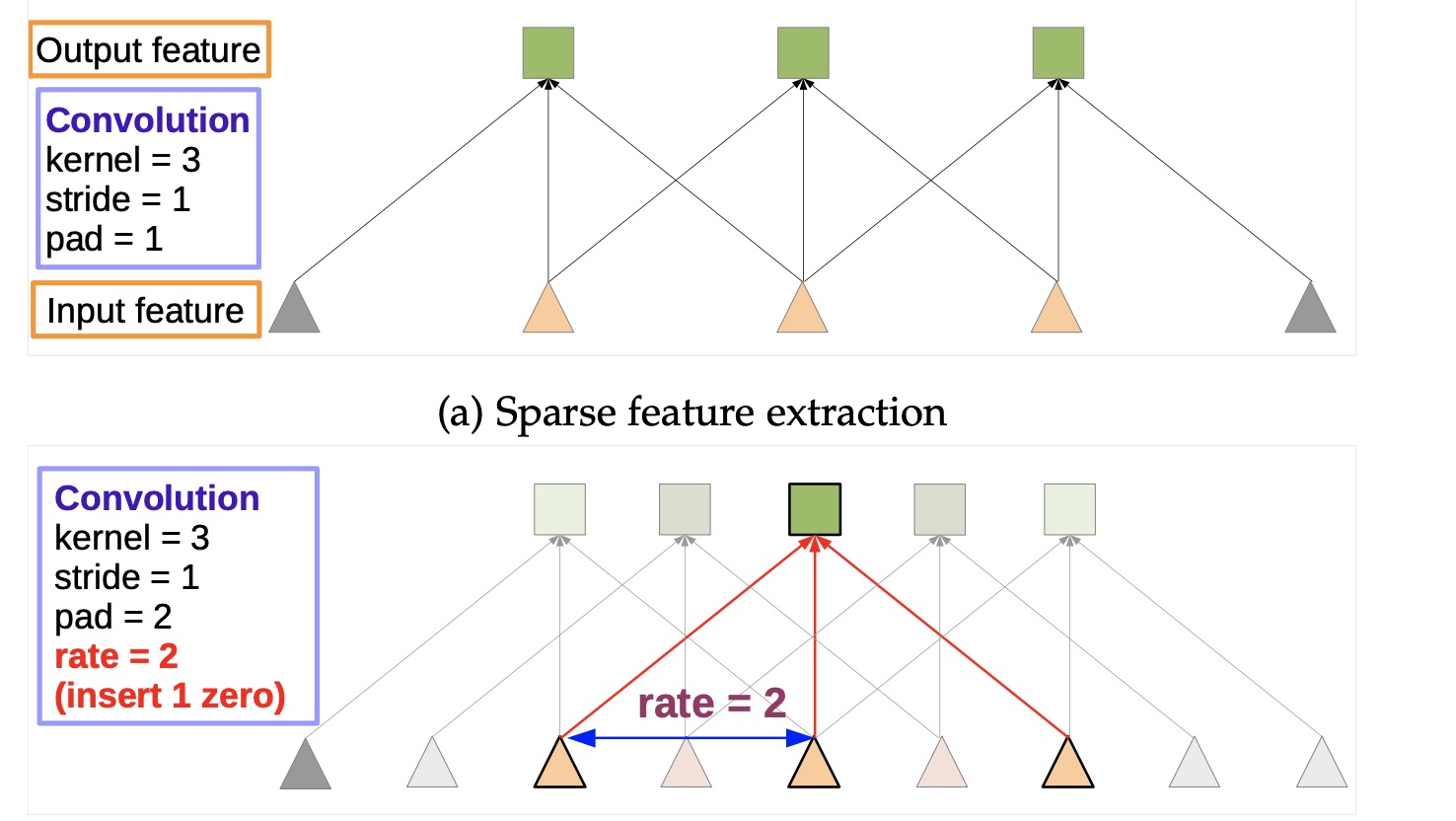
假如卷积核为1维卷积,大小 (1 * 3), 图中上图为标准卷积, 黄色三角形为卷积核,标准卷积中卷积核是连续的,下图中空洞卷积对卷积核0填充,此时卷积核的感受野由(1 * 3)变为了(1 * 5),拥有更大的感受野就可以获得更多的上下文信息. 同时输出也变大了,即进行了上采样. (当然在低层实现时并不会直接对卷积核填0, 卷积核大小不会变,会在im2col的时候进行操作)
ASPP
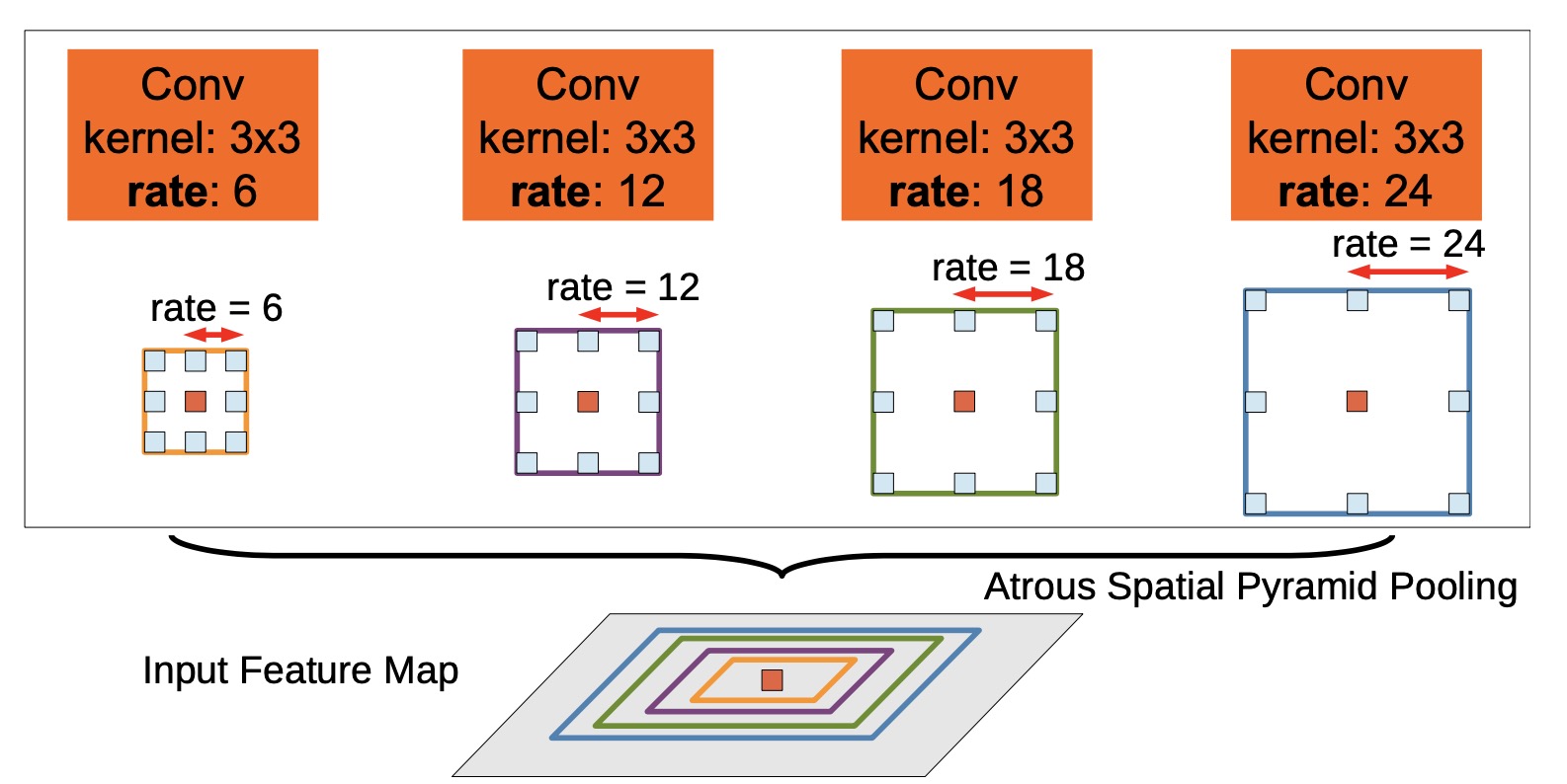
ASPP 借鉴了SPP的思想, 使用多个具有不同扩张率的卷积核进行计算, 然后融合在一起。
deeplab-v3
deeplab-v3 主要是在v2中做了些调整。
Going Deeper with Atrous Convolution Using Multi-Grid
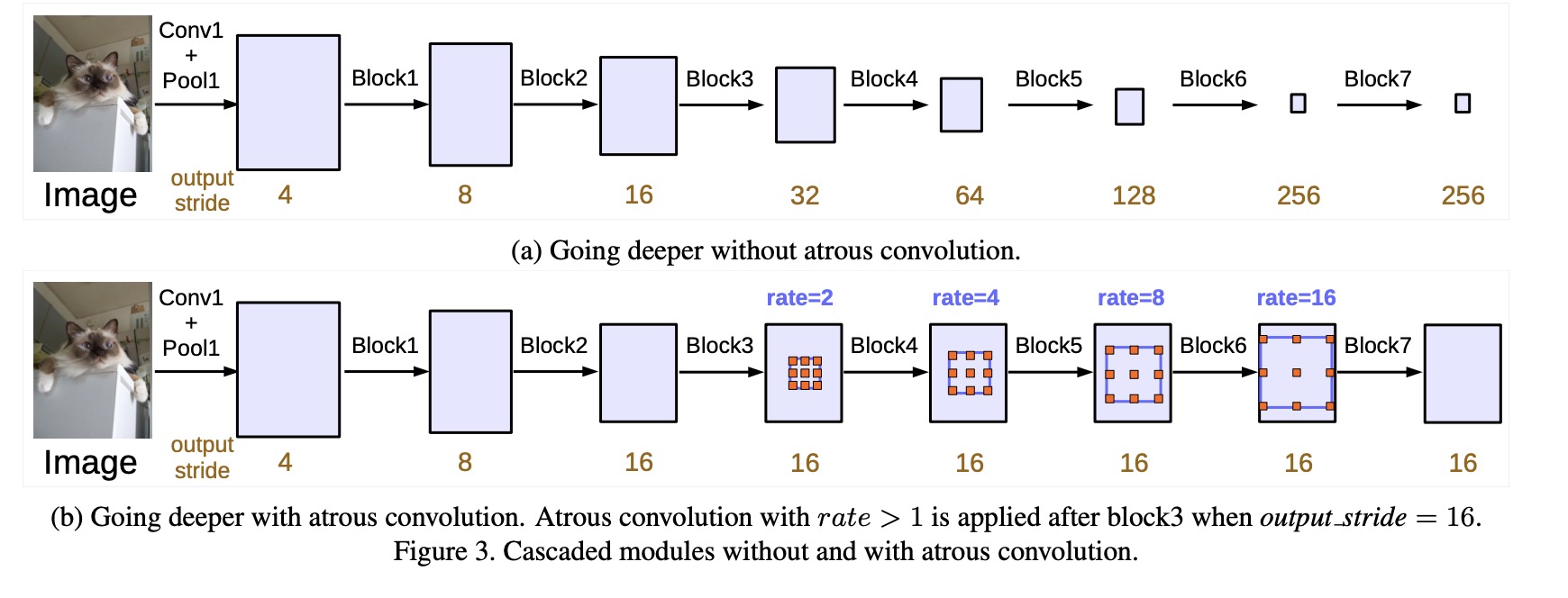
- 图中a为不使用空洞卷积, 由于卷积池化操作导致特征图越来越小
- 图中b为带空洞卷积,保持步幅的情况下可以获得更大的感受野同时不增加参数,还能获得更大的输出
block1,2,3,4 为残差网络的4个块, 5,6,7为复制的block4。每个块使用了不同大小的扩张率, 例如, 当output stride(表示当前层相对于原图的下采样倍数)= 16, Multi Grid = (1, 2, 4), 该层三个卷积核的扩张率分别为 2 · (1, 2, 4) = (2, 4, 8).
改进的ASPP
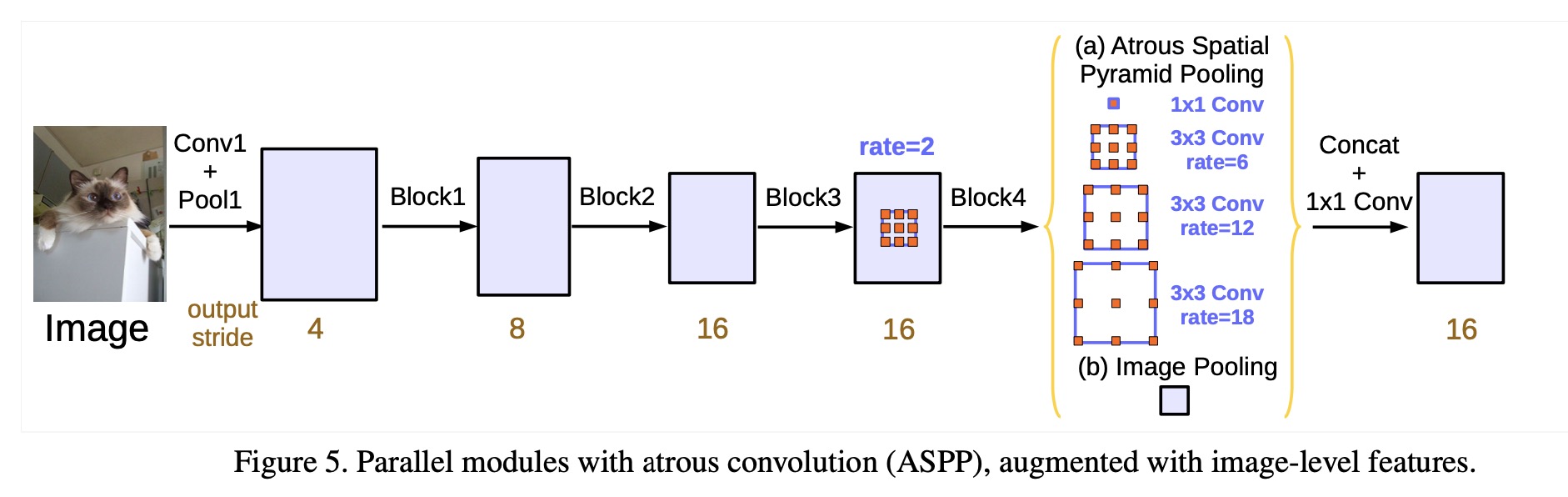
结合了更多的特征信息:
- 1 * 1 卷积与 3 * 3 的带有不同扩张率的空洞卷积
- 图像池化获得全局信息,使用全局平均池化
- BN
- 输出特征先进行concat,再 1 * 1 卷积融合
