
人脸检测网络: MTCNN
之前做人脸检测使用的是retinaface做的, 刚好最近被问到MTCNN, 以前没有细看, 正好做个笔记. MTCNN是2015年提出的用于人脸检测的网络, 发展到今天, 通用目标检测算法的检测能力已经大幅提升, MTCNN的结构我个人觉得设计太繁琐
论文创新点
级联多任务人脸检测架构, 即人脸检测box加五个关键点坐标
网络结构
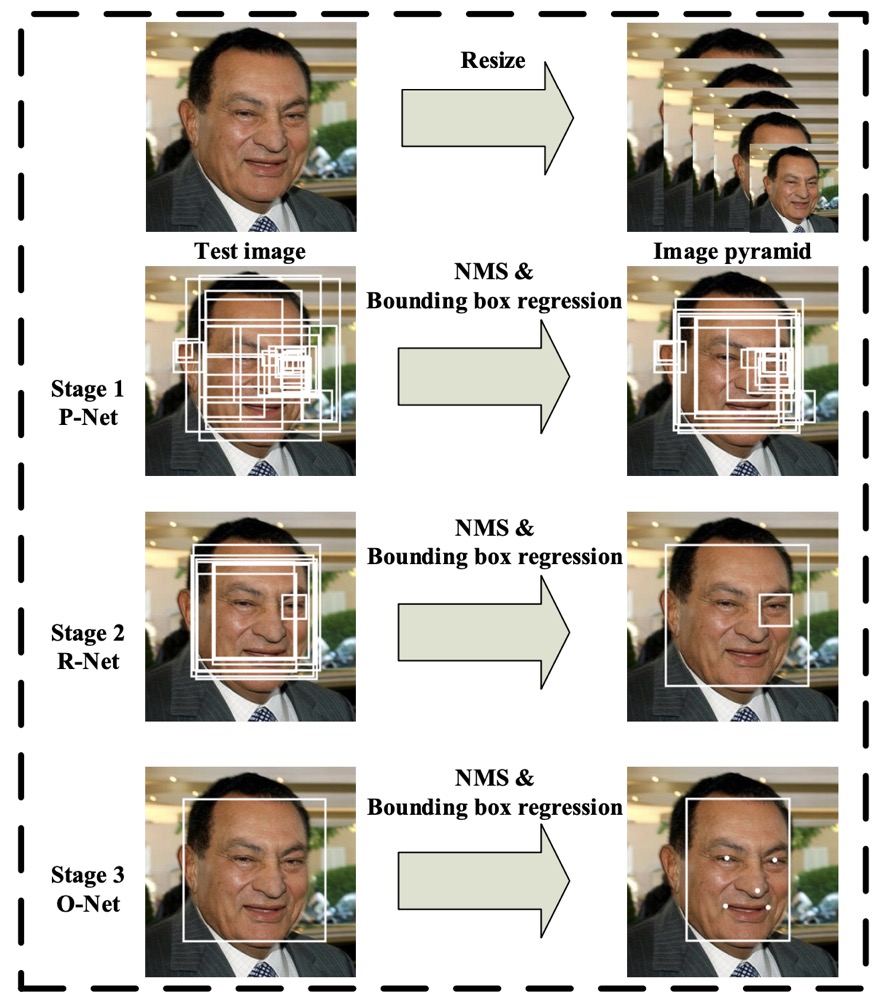
MTCNN 的网络结构如上图所示, 由三个级联的网络构成, 流程如下:
- 输入一张图片, 将其resize 到不同的尺寸得到图像金字塔(增加召回,针对不同尺寸的人脸)
- P-net, 生成候选人脸窗口和bounding-box, 然后进行NMS
- R-net, 将上诉候选框进行进一步的筛选并进行bbox回归, 排除背景框,再NMS
- 对候选框进一步进行人脸/背景分类, 以及box回归, 同时增加landmark关键点回归
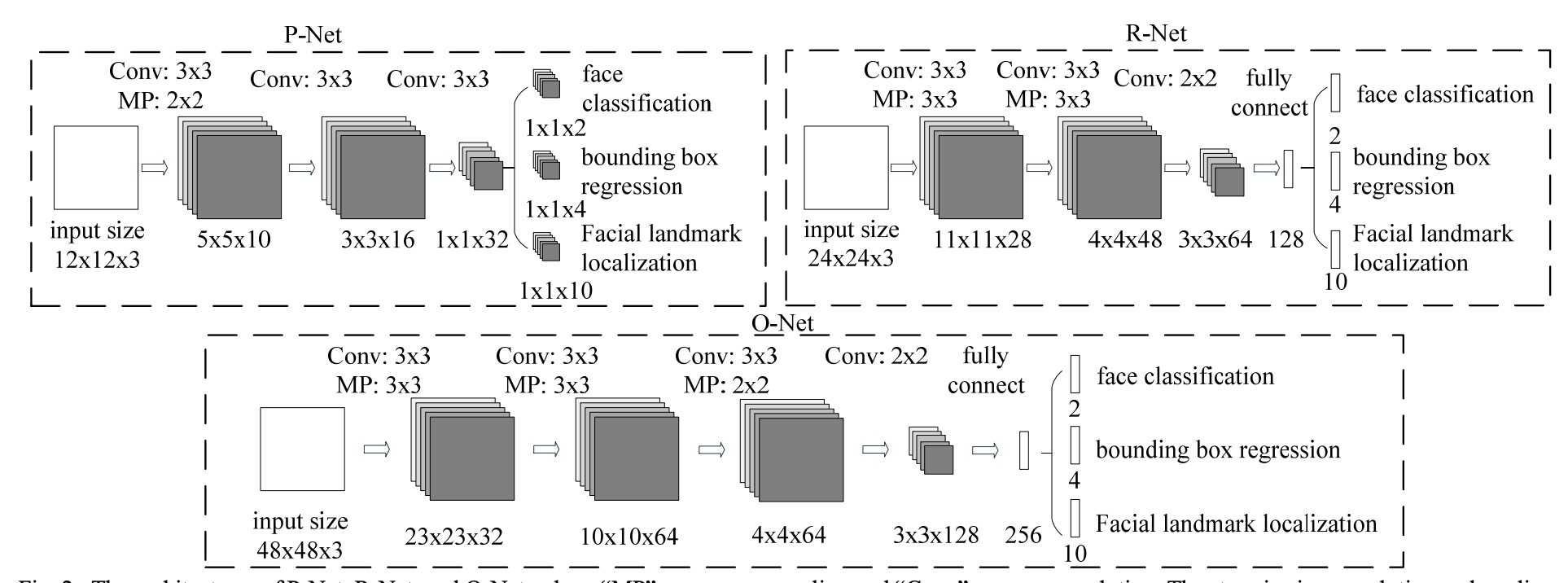
训练流程
- Pnet 输入为 12 * 12 的图像,从训练数据集中裁剪出 12 * 12 的样本,裁剪的人脸与GT IOU 大于0.65 记为正样本,小于0.4 记为负样本,二者之间的为部分人脸样本。
- 由于Rnet与Onet带全连接层,输入固定。Rnet 输入为24 * 24。从数据集中裁剪 24 * 24 的人脸框训练,以及使用Pnet的proposal作为训练样本(先NMS在resize到24 * 24)
- Onet 输入大小为48 * 48 ,使用Rnet生成的候选框(先NMS,再resize到48 * 48)作为训练样本;同时使用从数据集中裁剪的人脸作为训练样本
人脸分类任务:利用正样本和负样本进行训练
人脸边框回归任务:利用正样本和部分样本进行训练
关键点检测任务:利用关键点样本进行训练
关键点检测在 Pnet和Rnet中作为辅助,损失占比较小,预测时仅使用Onet的关键点输出结果
测试流程
Pnet为全卷积网络,输入可以为任意大小,但训练时均为12 * 12,为了检测不同大小的人脸,因此测试时先向下生成图像金字塔,下采样一倍时,12 * 12 的像素区域包含的信息为之前得 24 * 24 像素区域. 然后在不同的尺度下进行检测,使用NMS后,根据候选框提取图像,resize到24 * 24,输入Rnet, 再到Onet 输出.
损失
典型的多任务损失, 分类加回归损失.
边框偏移回归损失计算: 给定人脸标注框,(x1,y1)为左上角坐标,(x2,y2)为右下角坐标,新剪裁的边框坐标为(xn1,yn1),(xn2,yn2),width,height.则
$$offset _{x1} = (x1 - xn1)/width$$
