
yolov6 是美团开源的模型,主要是工业应用,官方说速度精度都比v5 和 x 高, 最近也用到了efficientRep 作为backbone, 记录一下 论文做了

对于常用的目标检测而言,测试集和训练集的类别时保持一致的,即我们想要检测什么,那么训练集就有该类别的数据. 对于zero-shot 即测试集的出

论文三连问 论文做了什么:使用分类数据集来训练检测模型的分类器,使检测器可以识别出上万的类别 论文怎么做的:对于检测标注格式的数据和分类标注格式
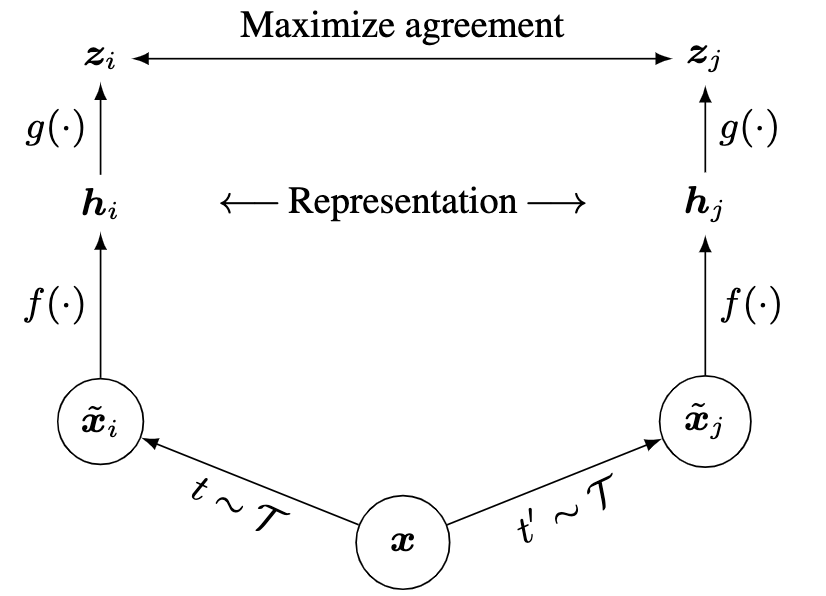
SimCLR 与 MOCO 都是采用自监督、对比学习的形式来训练视觉模型。因为对于主流的CNN网络,模型训练都依赖于人工标注,但是人工标注成本太大,我们能使用的标
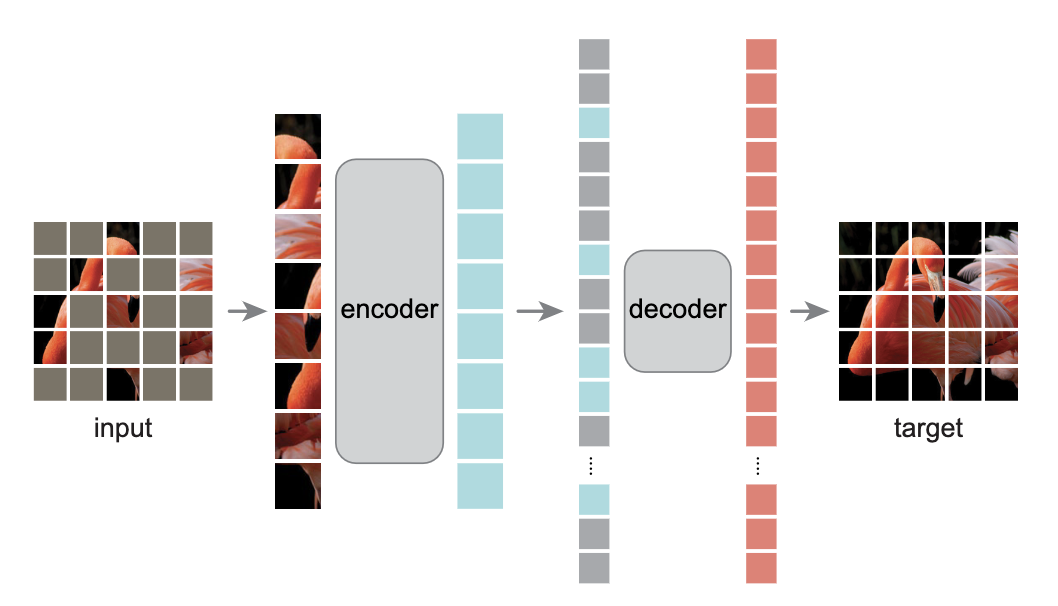
读前三问 论文做了什么:论文以自监督的形式来训练自动编码器用来提取特征,实现无标注的预训练 怎么做的:对输入图片进行mask,采用编码器-解码器
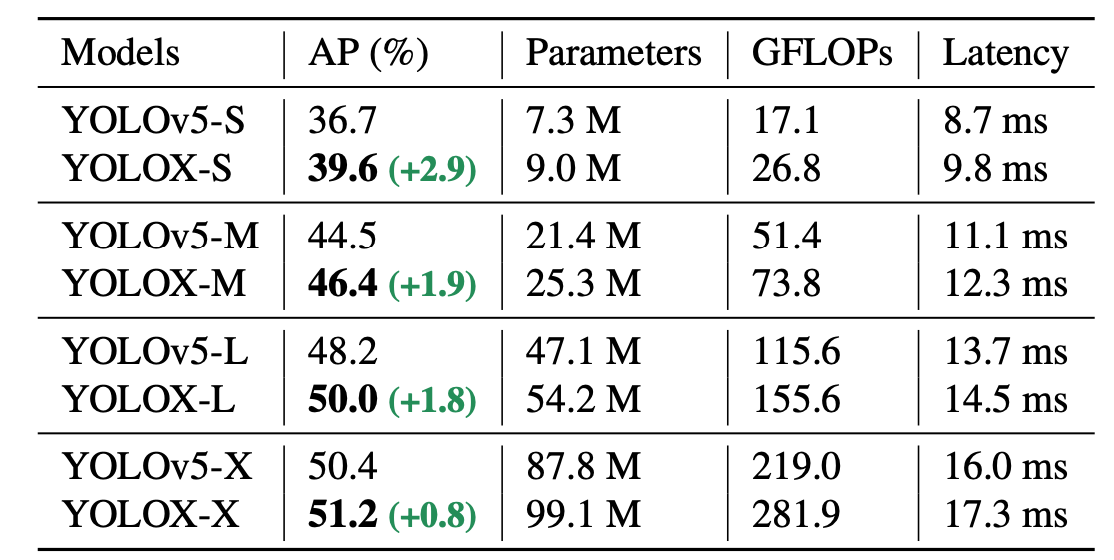
yolox 是旷世今年推出的一个新的YOLO检测器技术报告,核心是将YOLO与anchor free方式实现,性能超过了之前的YOLO系列。此笔记记录Y
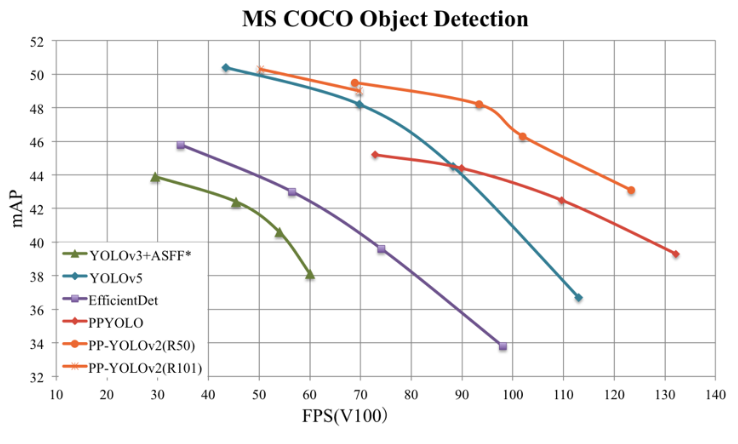
PP-YOLOv2 是百度对于ppyolo-v1 的升级版,主要是引入了各种插件来提升性能。如下图,ppyolov2 在相同的map下能达到更高的FPS. PPyolo-v2 的改进
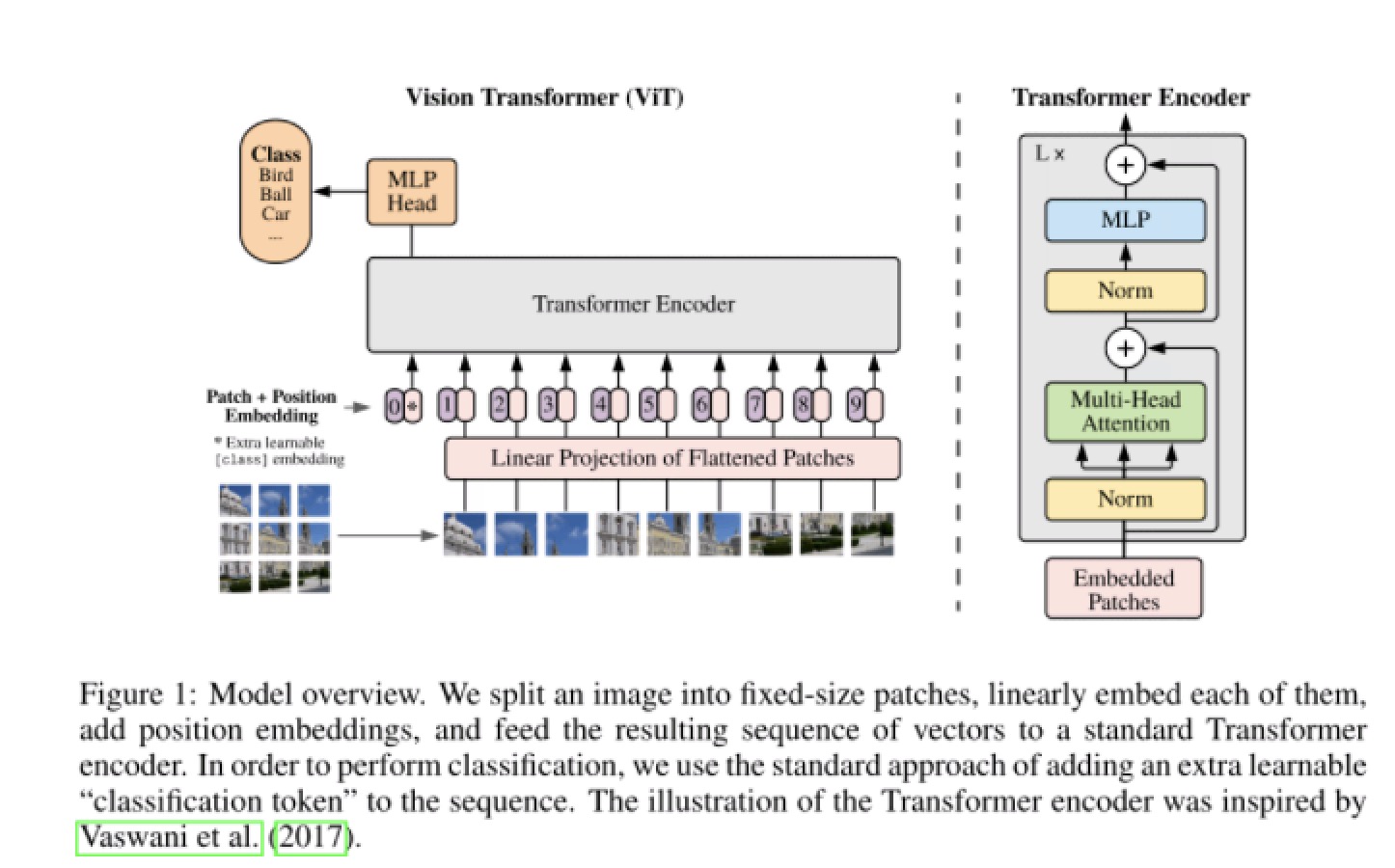
本文主要从代码角度记录使用transformer实现图像分类的流程. 代码vit-pytorch/ 总体结构 结合上图与代码展开: 前向传播过程代码
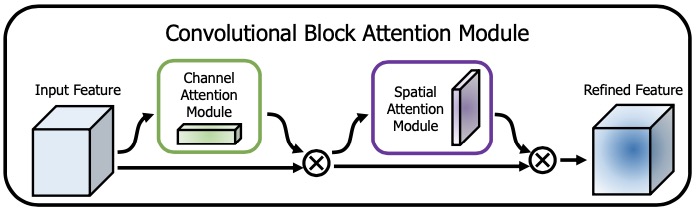
之前谈过SE-net, 对于目标检测或检测用于特征通道的attention, 今天记录一下CBAM模块, 对分类或检测中用来获取通道、空间位置的a
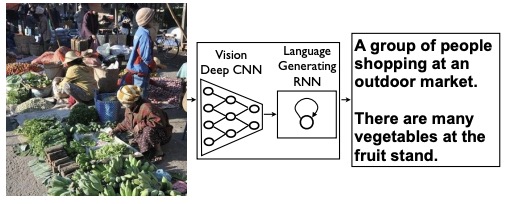
图像描述生成作为结合CV与NLP的跨模态学习任务, 在人工智能领域也是热门的研究点. 模型 Image caption 是在给定照片的情况下生成人类可读的文字描述的具有挑
